
ΑΙhub.org
Interview with Jerone Andrews: a framework towards evaluating diversity in datasets

Jerone Andrews, Dora Zhao, Orestis Papakyriakopoulos and Alice Xiang won a best paper award at the International Conference on Machine Learning (ICML) for their position paper Measure Dataset Diversity. Don’t Just Claim It. We spoke to Jerone about the team’s methodology, and how they developed a framework for conceptualising, operationalising, and evaluating diversity in machine learning datasets.
Could you give us a summary of your paper – what is it about and what is the problem you are trying to solve?
In our paper, we propose using measurement theory from the social sciences as a framework to improve the collection and evaluation of diverse machine learning datasets. Measurement theory offers a systematic and scientifically grounded approach to developing precise numerical representations of complex and abstract concepts, making it particularly suitable for tasks like conceptualising, operationalising, and evaluating qualities such as diversity in datasets. This framework can also be applied to other constructs like bias or difficulty.
We identified a significant issue in the field: the concept of diversity in datasets is often poorly defined or inconsistently applied across various works. To explore this, we reviewed 135 papers on machine learning datasets, covering text, image, and multimodal (text and image) datasets. While these papers often claimed their datasets were more diverse, we found that the term “diversity” was rarely clearly defined or measured in a consistent manner.
Our paper advocates for the integration of measurement theory into the data collection process. By doing so, dataset creators can better conceptualise abstract concepts like diversity, translate these concepts into measurable, empirical indicators—such as the number of countries represented in a dataset for geographic diversity—and evaluate the reliability and validity of their datasets. This approach ultimately leads to more transparent and reproducible research in machine learning.
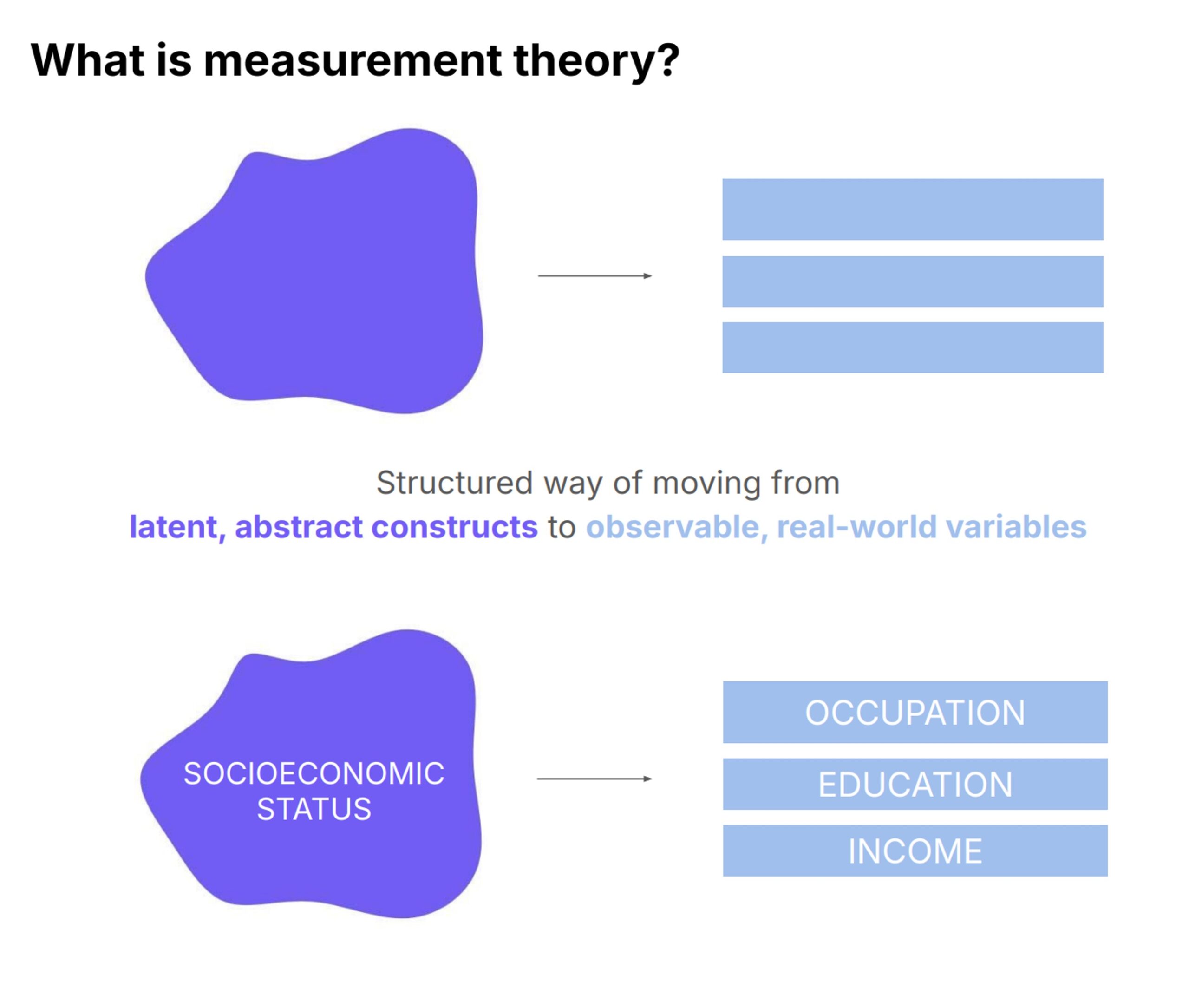 Measurement theory. Image credit: Jerone Andrews.
Measurement theory. Image credit: Jerone Andrews.
Could you explain conceptualisation, operationalization and evaluation in this context?
Conceptualization involves clearly defining the constructs we want to measure, using precise and agreed-upon terms. For example, if we’re aiming to achieve diversity in terms of ethnicity, we need to specify exactly what we mean by ethnicity, as it can vary significantly depending on cultural and geographical contexts.
Operationalization is the process of translating these abstract constructs into something that can be empirically measured. For instance, if we’re dealing with race, and our dataset is sourced from the internet, it can be challenging to infer someone’s race directly. Instead, one might use a proxy, such as skin tone, which can be operationalised when collecting or labelling data.
We split evaluation into two: reliability and validity. Reliability focuses on ensuring that the measurements are consistent and dependable. This can involve methods like test-retest reliability, where we might collect data from Twitter today, and then again next week using the same queries. By comparing the two datasets, we can assess the consistency of our data collection methodology. Validity, on the other hand, is about determining whether the empirical measurements align with the theoretical constructs. One approach to this is cross-dataset generalisation. For example, you could train a model on your dataset and then test it on another similar, pre-existing dataset. If the model performs consistently across different datasets, it suggests that the diversity captured by your dataset is valid and generalizable, at least in comparison to what has been done before.
How does your method build on, and differ from, previous work in the field?
Our work addresses a significant gap in the field: the lack of an agreed-upon method for evaluating whether a dataset is truly diverse. We build on this by introducing a framework from social sciences to bring more structure to the evaluation process.
It’s two-fold. First, we aim to provide a principled framework for researchers to follow when collecting datasets, ensuring that their claims about diversity are backed by concrete evidence. Second, our framework is designed for reviewers of machine learning papers who need to critically evaluate the diversity claims made in these papers. Unlike models, where evaluation standards are rigorous and well-established, datasets often do not undergo the same level of scrutiny. This leads to many dataset papers claiming diversity without adequate justification. Our framework is a response to this inconsistency, emphasising that claims about dataset diversity should be supported with the same rigour expected in model evaluations.
In the paper, you carry out a case study. Could you tell us a little bit about that?
The case study in our paper examines the Segment Anything dataset (SA-1B) from Meta, with a focus on how they approach and measure diversity within the dataset. We analysed how the creators operationalised diversity across various dimensions, such as geographical diversity, object size, and object complexity. For example, they measured the complexity of segmentation masks, which serves as a proxy for the diversity of object shapes. By comparing these metrics to those in other segmentation datasets, they could assess the relative diversity and difficulty of their dataset. This comparison helps in identifying whether the dataset provides a balanced representation of different complexities or if it is skewed towards simpler or more complex masks. Through this analysis, we illustrated the importance of clearly defining and measuring diversity to ensure that datasets genuinely reflect the diversity they claim to represent.
If you were to give a call to the community with recommendations and things that they should consider when they’re carrying out their research, what would you say?
The challenges we face in dataset diversity are not solely the responsibility of dataset collectors or reviewers; they are symptomatic of the broader research culture. Often, negative results are underreported, and critical analysis, such as making detailed comparisons or plots, might be overlooked because it could cast a paper in a less favourable light. My call to action is for the research community to shift the focus of the review process for dataset papers from just the final product to the entire process the authors undergo. Currently, there’s an overemphasis on the end results, which leads to datasets being released with claims of greater diversity based solely on better model performance. However, better performance doesn’t necessarily equate to true diversity; it could mean a newly proposed “more diverse” dataset has introduced more spurious correlations, allowing models to take shortcuts rather than genuinely reflecting diverse data.
Our paper also emphasises the importance of recognising that diversity doesn’t automatically reduce bias, nor does having more data inherently make a model less biased or a dataset more diverse. A larger dataset might increase compositional diversity by including a wider variety of things or concepts, but it could also introduce new spurious correlations. It’s crucial to differentiate between constructs like diversity, bias, and scale, and understand that achieving one does not automatically mean achieving the others.
About Jerone

|
Jerone Andrews is a research scientist at Sony AI. His work focuses on responsible data curation, representation learning, and bias detection and mitigation. Jerone holds an MSci in Mathematics from King’s College London, followed by an EPSRC-funded MRes and PhD in Computer Science from University College London. His research career includes a Royal Academy of Engineering Research Fellowship and a British Science Association Media Fellowship with BBC Future. Additionally, Jerone has been a Visiting Researcher at the National Institute of Informatics in Tokyo and Telefónica Research in Barcelona. |
tags: ICML, ICML2024

AIhub is supported by:








