
ΑΙhub.org
Rethinking LLM memorization
Introduction
A central question in the discussion of large language models (LLMs) concerns the extent to which they memorize their training data versus how they generalize to new tasks and settings. Most practitioners seem to (at least informally) believe that LLMs do some degree of both: they clearly memorize parts of the training data—for example, they are often able to reproduce large portions of training data verbatim [Carlini et al., 2023]—but they also seem to learn from this data, allowing them to generalize to new settings. The precise extent to which they do one or the other has massive implications for the practical and legal aspects of such models [Cooper et al., 2023]. Do LLMs truly produce new content, or do they only remix their training data? Should the act of training on copyrighted data be deemed an unfair use of data, or should fair use be judged by some notion of model memorization? When dealing with humans, we distinguish plagiarizing content from learning from it, but how should this extend to LLMs? The answer inherently relates to the definition of memorization for LLMs and the extent to which they memorize their training data.
However, even defining memorization for LLMs is challenging, and many existing definitions leave much to be desired. In our recent paper (project page), we propose a new definition of memorization based on a compression argument. Our definition posits that
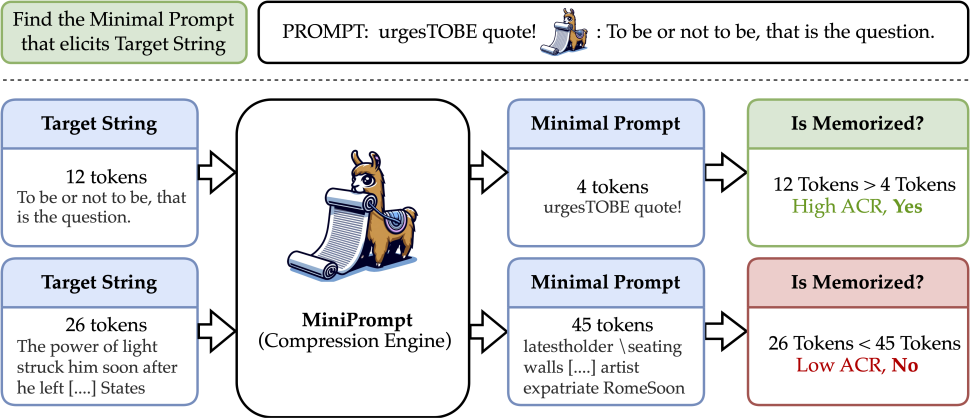
a phrase present in the training data is memorized if we can make the model reproduce the phrase using a prompt (much) shorter than the phrase itself.
Operationalizing this definition requires finding the shortest adversarial input prompt that is specifically optimized to produce a target output. We call this ratio of input-to-output tokens the Adversarial Compression Ratio (ACR). In other words, memorization is inherently tied to whether a certain output can be represented in a compressed form beyond what language models can do with typical text. We argue that such a definition provides an intuitive notion of memorization. If a certain phrase exists within the LLM training data (e.g., is not itself generated text) and it can be reproduced with fewer input tokens than output tokens, then the phrase must be stored somehow within the weights of the LLM. Although it may be more natural to consider compression in terms of the LLM-based notions of input/output perplexity, we argue that a simple compression ratio based on input/output token counts provides a more intuitive explanation to non-technical audiences and has the potential to serve as a legal basis for important questions about memorization and permissible data use. In addition to its intuitive nature, our definition has several other desirable qualities. We show that it appropriately ascribes many famous quotes as being memorized by existing LLMs (i.e., they have high ACR values). On the other hand, we find that text not in the training data of an LLM, such as samples posted on the internet after the training period, are not compressible, that is their ACR is low.
We examine several unlearning methods using ACR to show that they do not substantially affect the memorization of the model. That is, even after explicit finetuning, models asked to “forget” certain pieces of content are still able to reproduce them with a high ACR—in fact, not much smaller than with the original model. Our approach provides a simple and practical perspective on what memorization can mean, providing a useful tool for functional and legal analysis of LLMs.
Why We Need A New Definition
With LLMs ingesting more and more data, questions about their memorization are attracting attention [e.g., Carlini et al., 2019, 2023; Nasr et al., 2023; Zhang et al., 2023]. There remains a pressing need to accurately define memorization in a way that serves as a practical tool to ascertain the fair use of public data from a legal standpoint. To ground the problem, consider the court’s role in determining whether an LLM is breaching copyright. What constitutes a breach of copyright remains contentious, and prior work defines this on a spectrum from ‘training on a data point itself constitutes violation’ to ‘copyright violation only occurs if a model verbatim regurgitates training data.’ To formalize our argument for a new notion of memorization, we start with three definitions from prior work to highlight some of the gaps in the current thinking about memorization.
Discoverable memorization [Carlini et al., 2023], which says a string is memorized if the first few words elicit the rest of the quote exactly, has three particular problems. It is very permissive, easy to evade, and requires validation data to set parameters. Another notion is Extractable Memorization [Nasr et al., 2023], which says that if there exists a prompt that elicits the string in response. This falls too far on the other side of the issue by being very restrictive—what if the prompt includes the entire string in question, or worse, the instructions to repeat it? LLMs that are good at repeating will follow that instruction and output any string they are asked to. The risk is that it is possible to label any element of the training set as memorized, rendering this definition unfit in practice. Another definition is Counterfactual Memorization [Zhang et al., 2023], which aims to separate memorization from generalization and is tested through retraining many LLMs. Given the cost of training LLMs, such a definition is impractical for legal use.
In addition to these definitions from prior work on LLM memorization, several other seemingly viable approaches to memorization exist. Ultimately, we argue all of these frameworks—the definitions in existing work and the approaches described below—are each missing key elements of a good definition for assessing fair use of data.
Membership is not memorization. Perhaps if a copyrighted piece of data is in the training set at all, we might consider it a problem. However, there is a subtle but crucial difference between training set membership and memorization. In particular, the ongoing lawsuits in the field [e.g., as covered by Metz and Robertson, 2024] leave open the possibility that reproducing another’s creative work is problematic, but training on samples from that data may not be. This is common practice in the arts—consider that a copycat comedian telling someone else’s jokes is stealing, but an up-and-comer learning from tapes of the greats is doing nothing wrong. So while membership inference attacks (MIAs) [e.g. Shokri et al., 2017] may look like tests for memorization and they are even intimately related to auditing machine unlearning [Carlini et al., 2021, Pawelczyk et al., 2023, Choi et al., 2024], they have three issues as tests for memorization. Specifically, they are very restrictive, they are hard to arbitrate, and evaluation techniques are brittle.
Adversarial Compression Ratio
Our definition of memorization is based on answering the following question: Given a piece of text, how short is the minimal prompt that elicits that text exactly? In this section, we formally define and introduce our MiniPrompt algorithm that we use to answer our central question.
To begin, let a target natural text string  have a token sequence representation
have a token sequence representation  , which is a list of integer-valued indices that index a given vocabulary
, which is a list of integer-valued indices that index a given vocabulary  . We use
. We use  to count the length of a token sequence. A tokenizer
to count the length of a token sequence. A tokenizer  maps from strings to token sequences. Let
maps from strings to token sequences. Let  be an LLM that takes a list of tokens as input and outputs the next token probabilities. Consider that can perform generation by repeatedly predicting the next token from all the previous tokens with the
be an LLM that takes a list of tokens as input and outputs the next token probabilities. Consider that can perform generation by repeatedly predicting the next token from all the previous tokens with the argmax of its output appended to the sequence at each step (this process is called greedy decoding). With a slight abuse of notation, we will also call the greedy decoding result the output of . Let  be the token sequence generated by , which we call a completion or response:
be the token sequence generated by , which we call a completion or response:  ), which in natural language says that the model generates when prompted with
), which in natural language says that the model generates when prompted with  or that elicits as a response from . So our compression ratio ACR is defined for a target sequence as ACR
or that elicits as a response from . So our compression ratio ACR is defined for a target sequence as ACR , where
, where  s.t.
s.t.  .
.
Definition [
-Compressible Memorization] Given a generative model
.
The threshold  is a configurable parameter of this definition. We might choose to compare the ACR to the compression ratio of the text when run through a general-purpose compression program (explicitly assumed not to have memorized any such text) such as GZIP [Gailly and Adler, 1992] or SMAZ [Sanfilippo, 2006]. This amounts to setting equal to the SMAZ compression ratio of , for example. Alternatively, one might even use the compression ratio of the arithmetic encoding under another LLM as a comparison point, for example, if it was known with certainty that the LLM was never trained on the target output and hence could not have memorized it [Delétang et al., 2023]. In reality, copyright attribution cases are always subjective, and the goal of this work is not to argue for the right threshold function but rather to advocate for the adversarial compression framework for arbitrating fair data use. Thus, we use
is a configurable parameter of this definition. We might choose to compare the ACR to the compression ratio of the text when run through a general-purpose compression program (explicitly assumed not to have memorized any such text) such as GZIP [Gailly and Adler, 1992] or SMAZ [Sanfilippo, 2006]. This amounts to setting equal to the SMAZ compression ratio of , for example. Alternatively, one might even use the compression ratio of the arithmetic encoding under another LLM as a comparison point, for example, if it was known with certainty that the LLM was never trained on the target output and hence could not have memorized it [Delétang et al., 2023]. In reality, copyright attribution cases are always subjective, and the goal of this work is not to argue for the right threshold function but rather to advocate for the adversarial compression framework for arbitrating fair data use. Thus, we use  , which we believe has substantial practical value. 1
, which we believe has substantial practical value. 1
Our definition and the compression ratio lead to two natural ways to aggregate over a set of examples. First, we can average the ratio over all samples/test strings and report the average compression ratio (this is -independent). Second, we can label samples with a ratio greater than one as memorized and discuss the portion memorized over some set of test cases (for our choice of  ).
).
Empirical Findings
Model Size vs. Memorization: Since prior work has proposed alternative definitions of memorization that show that bigger models memorize more [Carlini et al., 2023], we ask whether our definition leads to the same finding. We find the same trends under our definition, meaning our view of memorization is consistent with existing scientific findings.
Unlearning for Privacy: We further experiment with models finetuned on synthetic data, which show that completion-based tests (i.e., the model’s ability to generate a specific output) often fail to fully reflect the model’s memorization. However, the ACR captures the persistence of memorization even after moderate attempts at unlearning.
Four Categorties of Data for Validation: We also validate the ACR as a metric using four different types of data: random sequences, famous quotes, Wikipedia sentences, and recent Associated Press (AP) articles. The goal is to ensure that the ACR aligns with intuitive expectations of memorization. Our results show that random sequences and recent AP articles, which the models were not trained on, are not compressible (i.e., not memorized). Famous quotes, which are repeated in the training data, show high compression ratios, indicating memorization. Wikipedia sentences fall between the two extremes, as some of them are memorized. These results validate that ACR meaningfully identifies memorization in data that is more common or repeated in the training set, while appropriately labelling unseen data as not-memorized.
When proposing new definitions, we are tasked with justifying why a new one is needed as well as showing its ability to capture a phenomenon of interest. This stands in contrast to developing detection/classification tools whose accuracy can easily be measured using labeled data. It is difficult by nature to define memorization as there is no set of ground truth labels that indicate which samples are memorized. Consequently, the criteria for a memorization definition should rely on how useful it is. Our definition is a promising direction for future regulation on LLM fair use of data as well as helping model owners confidently release models trained on sensitive data without releasing that data. Deploying our framework in practice may require careful thought about how to set the compression threshold but as it relates to the legal setting this is not a limitation as law suits always have some subjectivity [Downing, 2024]. Furthermore, as evidence in a court, this metric would not provide a binary test on which a suit could be decided, rather it would be a piece of a batch of evidence, in which some is more probative than others. Our hope is to provide regulators, model owners, and the courts a mechanism to measure the extent to which a model contains a particular string within its weights and make discussion about data usage more grounded and quantitative.
References
- Nicholas Carlini, Chang Liu, Úlfar Erlingsson, Jernej Kos, and Dawn Song. The secret sharer: Evaluating and testing unintended memorization in neural networks. In 28th USENIX security symposium (USENIX security 19), pages 267–284, 2019.
- Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, Andreas Terzis, and Florian Tramèr. Membership inference attacks from first principles. arXiv preprint arXiv:2112.03570, 2021.
- Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramèr, and Chiyuan Zhang. Quantifying memorization across neural language models, 2023.
- Dami Choi, Yonadav Shavit, and David K Duvenaud. Tools for verifying neural models’ training data. Advances in Neural Information Processing Systems, 36, 2024.
- A Feder Cooper, Katherine Lee, James Grimmelmann, Daphne Ippolito, Christo- pher Callison-Burch, Christopher A Choquette-Choo, Niloofar Mireshghallah, Miles Brundage, David Mimno, Madiha Zahrah Choksi, et al. Report of the 1st workshop on generative ai and law. arXiv preprint arXiv:2311.06477, 2023.
- Grégoire Delétang, Anian Ruoss, Paul-Ambroise Duquenne, Elliot Catt, Tim Genewein, Christopher Mattern, Jordi Grau-Moya, Li Kevin Wenliang, Matthew Aitchison, Laurent Orseau, et al. Language modeling is compression. arXiv preprint arXiv:2309.10668, 2023.
- Kate Downing. Copyright fundamentals for AI researchers. In Proceedings of the Twelfth International Conference on Learning Representations (ICLR), 2024. URL https://iclr.cc/media/iclr-2024/Slides/21804.pdf.
- Jean-Loup Gailly and Mark Adler. gzip. https://www.gnu.org/software/gzip/, 1992. Accessed: 2024-05-21.
- Cade Metz and Katie Robertson. Openai seeks to dismiss parts of the new york times’s lawsuit. The New York Times, 2024.
- Milad Nasr, Nicholas Carlini, Jonathan Hayase, Matthew Jagielski, A Feder Cooper, Daphne Ippolito, Christopher A Choquette-Choo, Eric Wallace, Florian Tramèr, and Katherine Lee. Scalable extraction of training data from (production) language models. arXiv preprint arXiv:2311.17035, 2023.
- Martin Pawelczyk, Seth Neel, and Himabindu Lakkaraju. In-context unlearning: Language models as few shot unlearners. arXiv preprint arXiv:2310.07579, 2023.
- Salvatore Sanfilippo. Smaz: Small strings compression library. https://github.com/ antirez/smaz, 2006. Accessed: 2024-05-21.
- Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models. In 2017 IEEE symposium on security and privacy (SP), pages 3–18. IEEE, 2017.
- Chiyuan Zhang, Daphne Ippolito, Katherine Lee, Matthew Jagielski, Florian Tramèr, and Nicholas Carlini. Counterfactual memorization in neural language models. Advances in Neural Information Processing Systems, 36:39321–39362, 2023.
Footnotes
 to
to  ,” for which a chat model is able to generate
,” for which a chat model is able to generate  ,” which results in a very high ACR. However, for copyright purposes, we argue that this category of algorithmic prompts is in the gray area where determining memorization is difficult and beyond the scope of this paper, given our primary application to creative works.
,” which results in a very high ACR. However, for copyright purposes, we argue that this category of algorithmic prompts is in the gray area where determining memorization is difficult and beyond the scope of this paper, given our primary application to creative works.This article was initially published on the ML@CMU blog and appears here with the author’s permission.
tags: deep dive

AIhub is supported by:








