
ΑΙhub.org
#AAAI2025 outstanding paper – DivShift: Exploring domain-specific distribution shift in large-scale, volunteer-collected biodiversity datasets
Citizen science platforms like iNaturalist have increased in popularity, fueling the rapid development of biodiversity foundation models. However, such data are inherently biased, and are collected in an opportunistic manner that often skews toward certain locations, times, species, observer experience levels, and states.
Our work, titled “DivShift: Exploring Domain-Specific Distribution Shifts in Large-Scale, Volunteer-Collected Biodiversity Datasets,” tackles the challenge of quantifying the impacts of these biases on deep learning model performance.
Biases in citizen science data
 Biases present in biodiversity data include spatial bias, temporal bias, taxonomic bias, observer behavior bias, and sociopolitical bias.
Biases present in biodiversity data include spatial bias, temporal bias, taxonomic bias, observer behavior bias, and sociopolitical bias.
AI models typically assume training data to be independent and identically distributed (i.i.d.). But biodiversity data collected by volunteers defies these assumptions. For instance, urban areas or charismatic species like blooming flowers receive disproportionate attention. These biases have been well-documented in ecology literature but are often underlooked or ignored in the development of deep learning models from these data. Such uneven sampling can limit a model’s accuracy in less-visited regions and for less charismatic species. Furthermore, without addressing these biases, models trained on citizen science data risk misleading conservation efforts and failing where they’re most needed.
The DivShift framework and DivShift-NAWC dataset
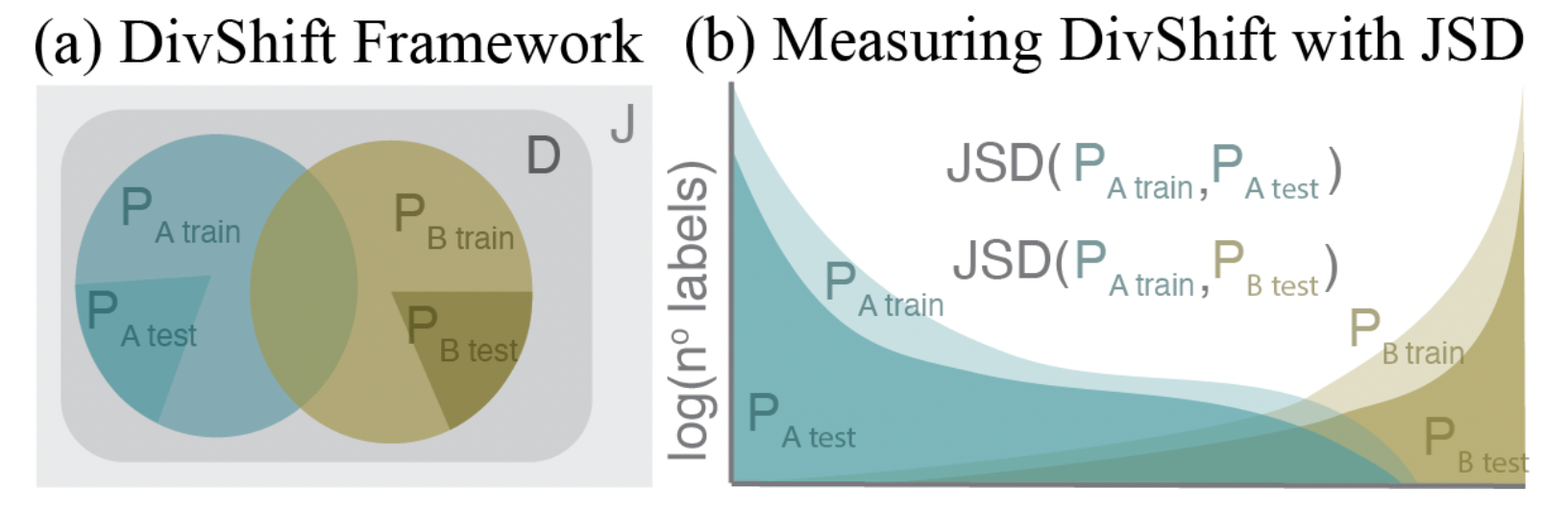 The Diversity Shift (DivShift) Framework (a) quantifies impacts of domain-specific biases by first partitioning data into partitions PA and PB using expert-verified types of bias. Bias impacts are then quantified by measuring the accuracy of models trained on PA train using PA test and PB test which is further compared to (b) the distribution shift between labels in PA train to labels in PA test and PB test using the Jensen-Shannon Divergence (JSD).
The Diversity Shift (DivShift) Framework (a) quantifies impacts of domain-specific biases by first partitioning data into partitions PA and PB using expert-verified types of bias. Bias impacts are then quantified by measuring the accuracy of models trained on PA train using PA test and PB test which is further compared to (b) the distribution shift between labels in PA train to labels in PA test and PB test using the Jensen-Shannon Divergence (JSD).
We introduce DivShift, a framework that casts biases as “domain-specific distribution shifts” to analyze the impacts of data biases on AI model performance. From the true distribution of biodiversity, J, our data, D of observations from volunteer observers has a biased sampling process. We partition D into PA and PB by some known bias in the data, and we measure the difference between the partitions via the Jensen-Shannon divergence (in this case, we use the species label distribution). Then, we compare this measure to deep learning model performance. This framework gives insight into how models generalize when moving from data‑rich to data‑sparse regions, plus in-domain to out-domain applications, and helps quantify how sampling bias skews accuracy, especially across sensitive taxa or geographic subgroups.
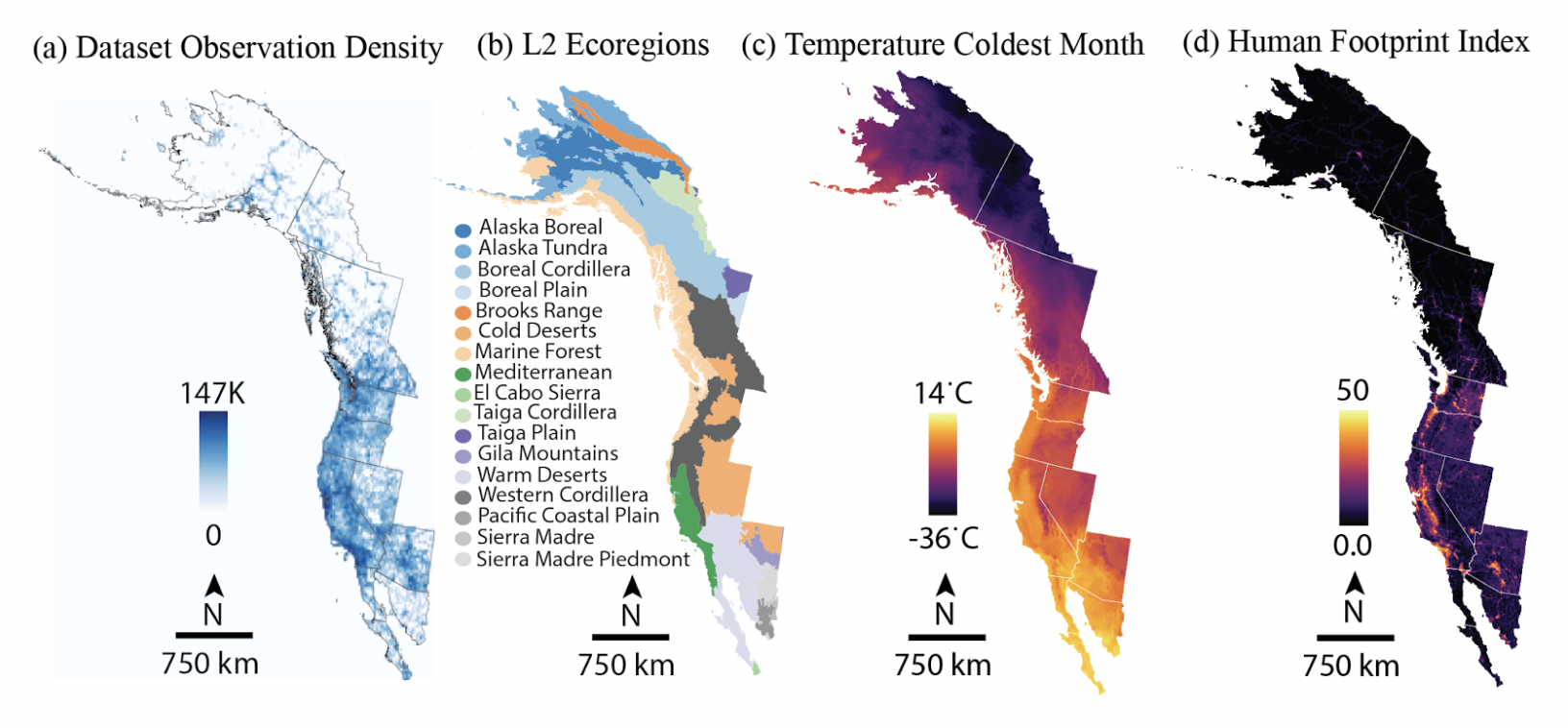 (a) Density plot of the DivShift-NAWC’s iNaturalist observations. Observations are skewed to U.S. and coastal states. (b) DivShift-NAWC spans a diverse set of habitats and ecosystems, (c) along with climates.(d) DivShift-NAWC observations are concentrated in human-modified areas [2].
(a) Density plot of the DivShift-NAWC’s iNaturalist observations. Observations are skewed to U.S. and coastal states. (b) DivShift-NAWC spans a diverse set of habitats and ecosystems, (c) along with climates.(d) DivShift-NAWC observations are concentrated in human-modified areas [2].
We pair this framework with the DivShift- North American West Coast (NAWC) dataset. It comprises nearly 7.5 million plant images from iNaturalist spanning the North American West Coast. Critically, DivShift-NAWC partitions these images along five axes of documented bias:
- Spatial: Urban vs. wilderness areas using the Human Footprint Index
- Temporal: Year-round collection vs. episodic events (e.g., bioblitzes) using the City Nature Challenge
- Taxonomic: Long-tailed vs. balanced training data
- Observer engagement: Engaged vs. casual observers using observation quantities
- Sociopolitical: State boundaries.
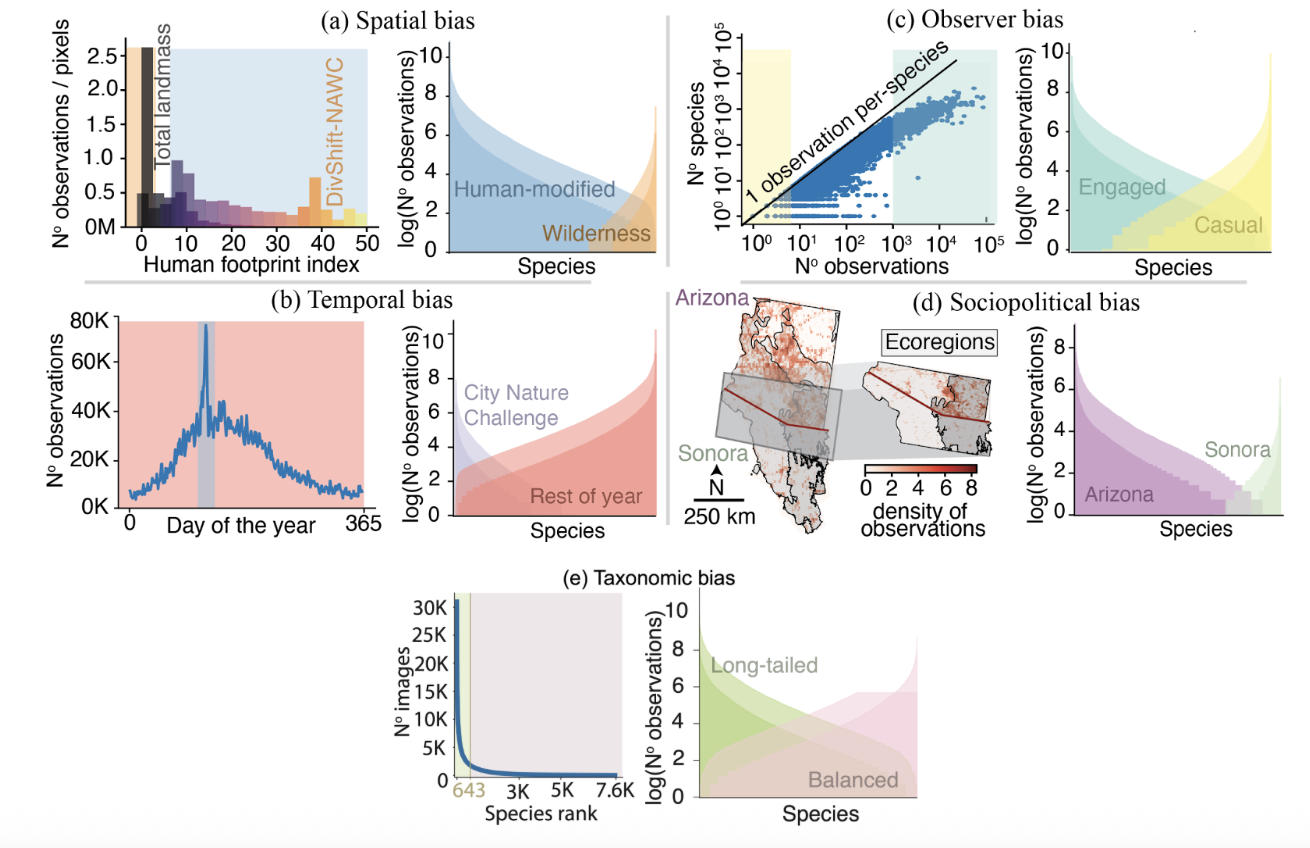
This careful partitioning allows a detailed exploration of biases across key ecological and societal dimensions.
Key insights from our case study
We apply the DivShift framework to the DivShift-NAWC dataset for fine-grained visual classification of plant species. We run supervised learning on a ResNet-18 with standard training parameters and measure Top-1 accuracy for eight different categories.
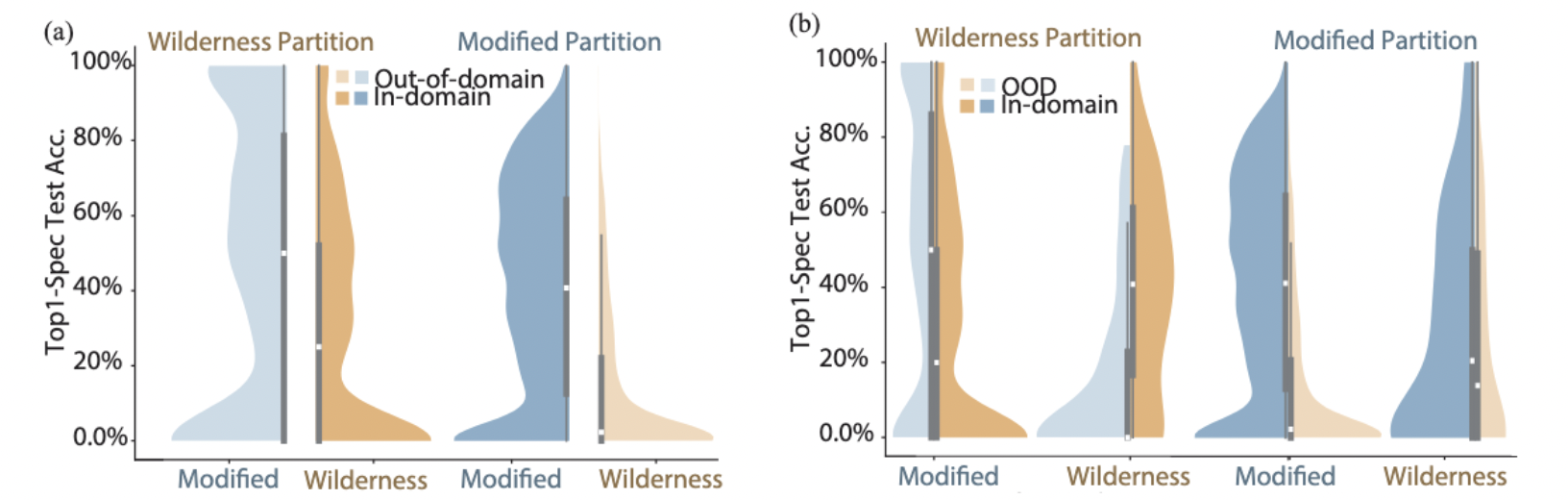 (a) Performance skews to habited areas, but (b) the wildest species are left behind
(a) Performance skews to habited areas, but (b) the wildest species are left behind
Spatial Bias: Models performed best in urban, densely-observed environments but struggled significantly in wilderness areas due to lack of training data.
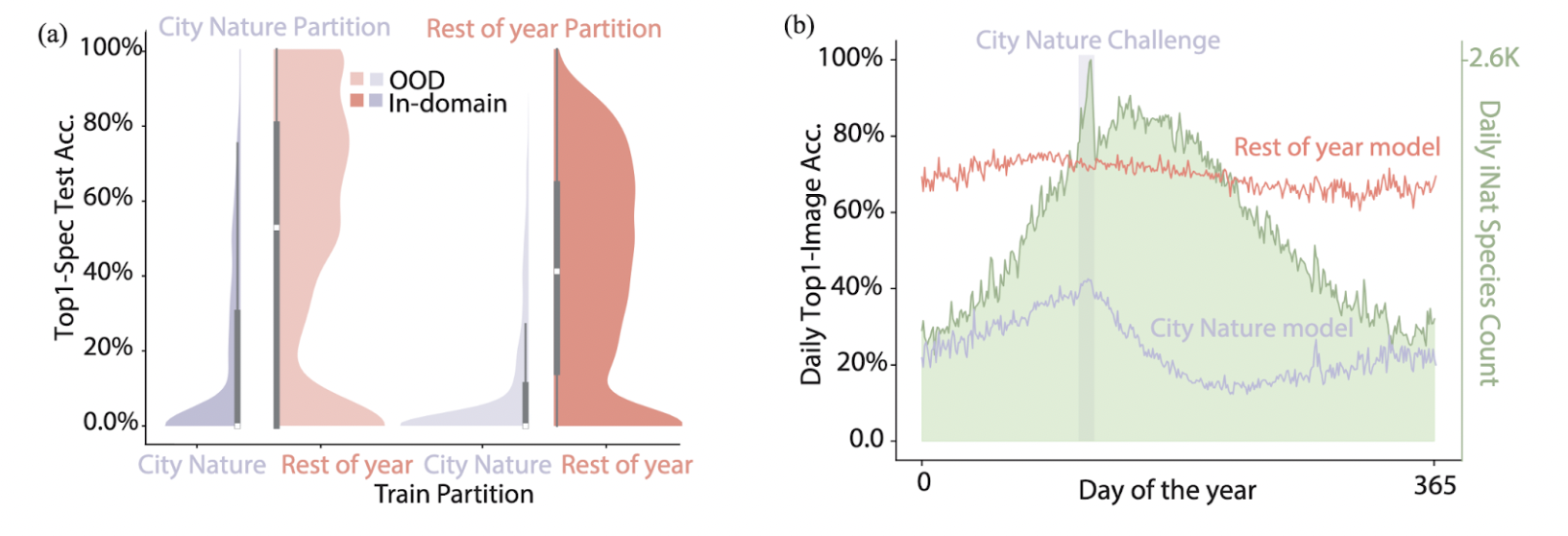
Temporal Bias: Continuous year-round observations led to stronger model performance than data from focused, short-term bioblitzes.
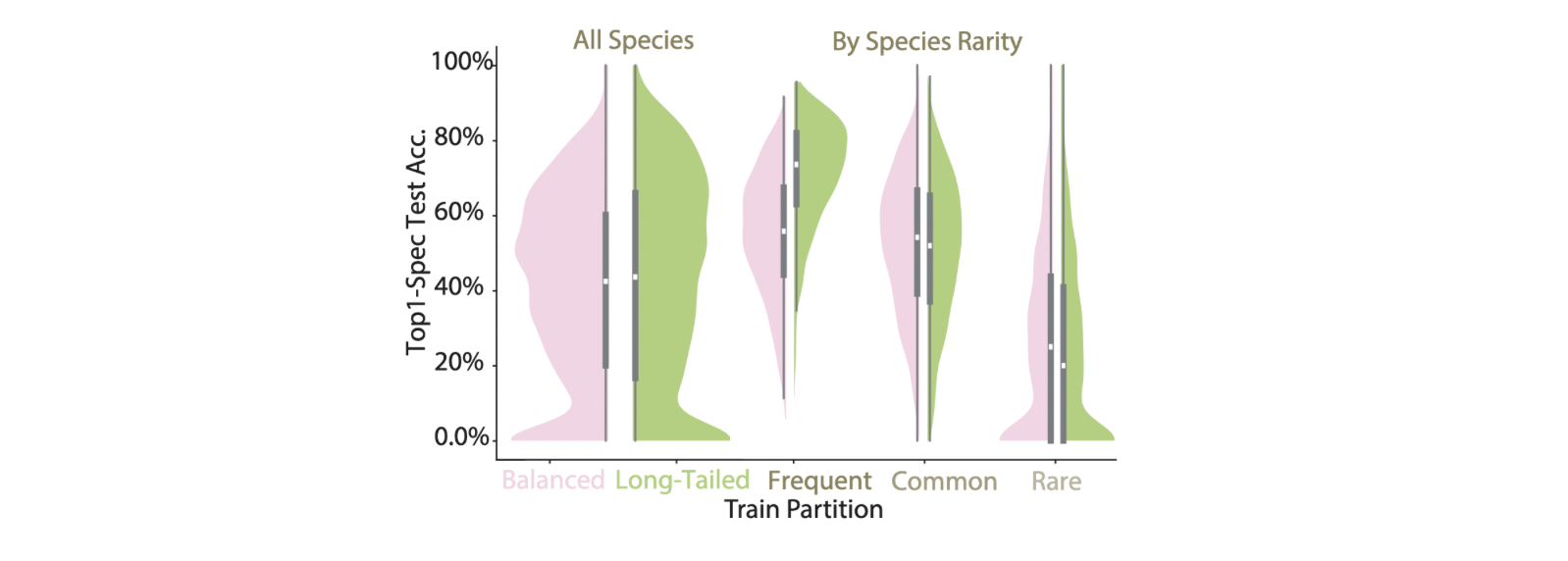
Taxonomic Bias: Balancing datasets improved detection of rare species but degraded performance for common species, highlighting a trade-off depending on conservation goals.

Observer Engagement: Data from highly engaged, frequent observers increased model accuracy. Conversely, contributions from occasional users negatively affected performance.
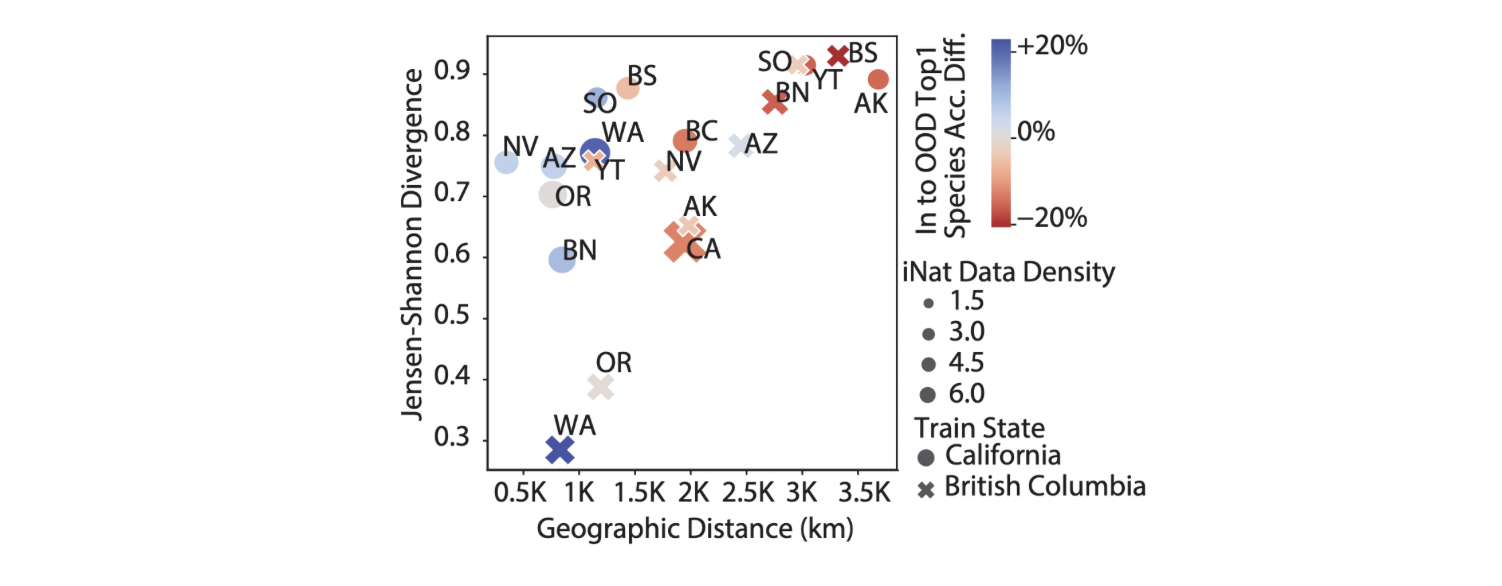
Sociopolitical Bias: Geographical and ecological distance correlated along with accuracy. However, this correlation differed depending on training state and data density.
Recommendations
Our findings translate into recommendations for training biodiversity models:
- Spatial: Augment citizen data in wilderness areas with targeted, expert-led surveys.
- Temporal: Encourage continuous data collection rather than relying solely on periodic collection events.
- Taxonomic: Choose training data curation strategies based on whether to prioritize rare or common species.
- Observer: Prioritize data from frequent contributors and consider filtering out sporadic observers.
- Sociopolitical: Implement additional validation processes or targeted sampling in low-data-density areas to ensure robust generalization.
Limitations, future directions, and conclusion
DivShift-NAWC doesn’t capture all possible biases (such as fine-scale geographic or intersectional biases), and does not not dive deeply into confounding variables in the bias partitions. Future work aims to incorporate unsupervised learning and additional environmental metadata to further refine bias detection and mitigation strategies, as well as address label availability and quality.
With biodiversity loss accelerating globally, accurate and equitable AI tools are urgently needed. Our DivShift framework offers a practical way to understand and counteract biases in volunteer-collected biodiversity datasets, enabling more reliable ecological models. We believe these insights and tools will help maximize the enormous potential of citizen science and machine learning in biodiversity conservation.
AAAI proceedings | Extended paper | Dataset | Code
This work won the AAAI-25 outstanding paper award – AI for social alignment track.
tags: AAAI, AAAI2025


AIhub is supported by:








