
ΑΙhub.org
‘Probably’ doesn’t mean the same thing to your AI as it does to you
 IceMing & Digit / Stochastic Parrots at Work / Licenced by CC-BY 4.0
IceMing & Digit / Stochastic Parrots at Work / Licenced by CC-BY 4.0
By Mayank Kejriwal, University of Southern California
When a human says an event is “probable” or “likely,” people generally have a shared, if fuzzy, understanding of what that means. But when an AI chatbot like ChatGPT uses the same word, it’s not assessing the odds the way we do, my colleagues and I found.
We recently published a study in the journal NPJ Complexity that suggests that, while large language model AIs excel at conversation, they often fail to align with humans when communicating uncertainty. The research focused on words of estimative probability, which include terms like “maybe,” “probably” and “almost certain.”
By comparing how AI models and humans map these words to numerical percentages, we uncovered significant gaps between humans and large language models. While the models do tend to agree with humans on extremes like “impossible,” they diverge sharply on hedge words like “maybe.” For example, a model might use the word “likely” to represent an 80% probability, while a human reader assumes it means closer to 65%.
This could be because humans can interpret words such as “likely” and “probable” based more on contextual cues and personal experiences. In contrast, large language models may be averaging over conflicting usages of those words in their training data, leading to divergences with human interpretations.
Our study also found that large language models are sensitive to gendered language and the specific language used for prompting. When a prompt changed from “he” to “she,” the AI’s probability estimates often became more rigid, reflecting biases embedded in its training data. When a prompt changed from English to Chinese, the AI’s probability estimates often shifted, possibly due to differences between English and Chinese in how people express and understand uncertainty.
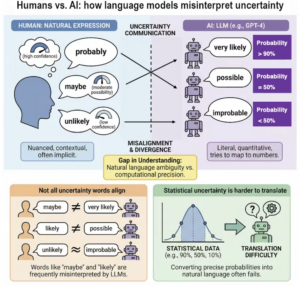 AI chatbots don’t interpret ‘probably’ and ‘maybe’ the same way you do. Mayank Kejriwal.
AI chatbots don’t interpret ‘probably’ and ‘maybe’ the same way you do. Mayank Kejriwal.
Why it matters
Far from being a linguistic quirk, this misalignment is a fundamental challenge for AI safety and human-AI interaction. As large language models are increasingly used in high-stakes fields like health care, government policy and scientific reporting, the way they communicate risk becomes a matter of public trust.
If an AI assistant helping a doctor, for instance, describes a side effect as “unlikely,” but the model’s internal calculation of “unlikely” is much higher than the doctor’s interpretation, the resulting decision could be flawed.
What other research is being done
Scientists have studied how humans quantify uncertainty since the 1960s, a field pioneered by CIA analysts to improve intelligence reporting. More recently, there has been an explosion in large language model literature seeking to look under the hood of neural networks to better understand their “behaviors” and linguistic patterns.
Our study adds a layer of complexity by treating the interaction between humans and artificial intelligence as a biological-like system where meaning can degrade. It moves beyond simply measuring if an AI is “smart” and instead asks if it is aligned.
Other researchers are currently exploring whether so-called chain-of-thought prompting – asking the AI to show its work – can fix these errors. However, our study found that even advanced reasoning doesn’t always bridge the gap between statistical data and verbal labels.
What’s next
A goal for future AI development is to create models that don’t just predict the next likely word but actually understand the weight of the uncertainty they are conveying. Researchers are calling for more robust consistency metrics to ensure that if a model sees a 10% chance in the data, it chooses the same word every time.
As we move toward a world where AI summarizes scientific papers and manages people’s schedules, making sure that “probably” means “probably” is a vital step in making these systems reliable partners rather than just sophisticated parrots.
Mayank Kejriwal, Research Assistant Professor of Industrial & Systems Engineering, University of Southern California
This article is republished from The Conversation under a Creative Commons license. Read the original article here.
AUAI is supported by:








