
ΑΙhub.org
Interview with Deepika Vemuri: interpretability and concept-based learning

The latest interview in our series with the AAAI/SIGAI Doctoral Consortium participants features Deepika Vemuri who is working on interpretability and concept-based learning. We found out more about the two aspects of concept-based models that she’s been researching.
Could you tell us a bit about your PhD – where are you studying, and what is the topic of your research?
I’m a PhD student from IIT Hyderabad working with Dr Vineeth N Balasubramanian, supported by the PMRF Fellowship. Most current state-of-the-art models are black boxes, which is especially problematic when these models are used in high-stakes applications like criminal justice and healthcare, where people’s lives depend on the decisions of these models. Interpretability is imperative. I approach this from a Concept-Based Learning perspective, a paradigm that aims to guide the learning process of models through high-level, human-understandable concepts. For example, in an image classification setting, the model could learn to look for concepts like fur, whiskers and mammal to classify an input as a cat. I like to think of this as akin to human conceptual learning. Say a child were learning what the idea of a bird is, they would probably look at multiple types of birds and over time learn that they possess a shared set of features – of concepts – like wings, beak, can fly, and so on using which they could recognize something as a bird. The goal of my PhD is to imbue vision models with a similar capability. Concepts, as a consequence, serve as a looking glass into the model, capturing semantic abstractions.
Can you give us an overview of the research you’ve carried out so far during your PhD?
There are two aspects of these models that I’ve studied so far. First, most current concept-based models are limited by the modelling capacity of the concepts. This is because most concept-to-class associations are modelled via a linear layer. This is for interpretability purposes – so that we can infer the importance of each concept for a particular class by simply looking at the weights learned by the linear layer. However, it is inherently limiting. For example, consider a model learning to recognize an arctic fox. Arctic foxes have either white fur or brown fur depending on the environmental conditions. A linear layer cannot capture such nuance. So, the question we ask in this work is: How can we go beyond a linear concept-to-class mapping while retaining interpretability? Logic operations present a natural way to model such relations in a structured manner (white fur XOR brown fur). To this end, we introduce a logic module comprising differentiable fuzzy logic gates that learn predicates (logical combinations of concepts) for each class. We experimentally observe that logic improves multiple aspects of a model’s behavior leading to better accuracy, more effective interventions and improved interpretability (Fig 1(a) shows an example of a predicate captured for the class Ringed Kingfisher from the CUB200 dataset). This work led to a publication in WACV 2026.
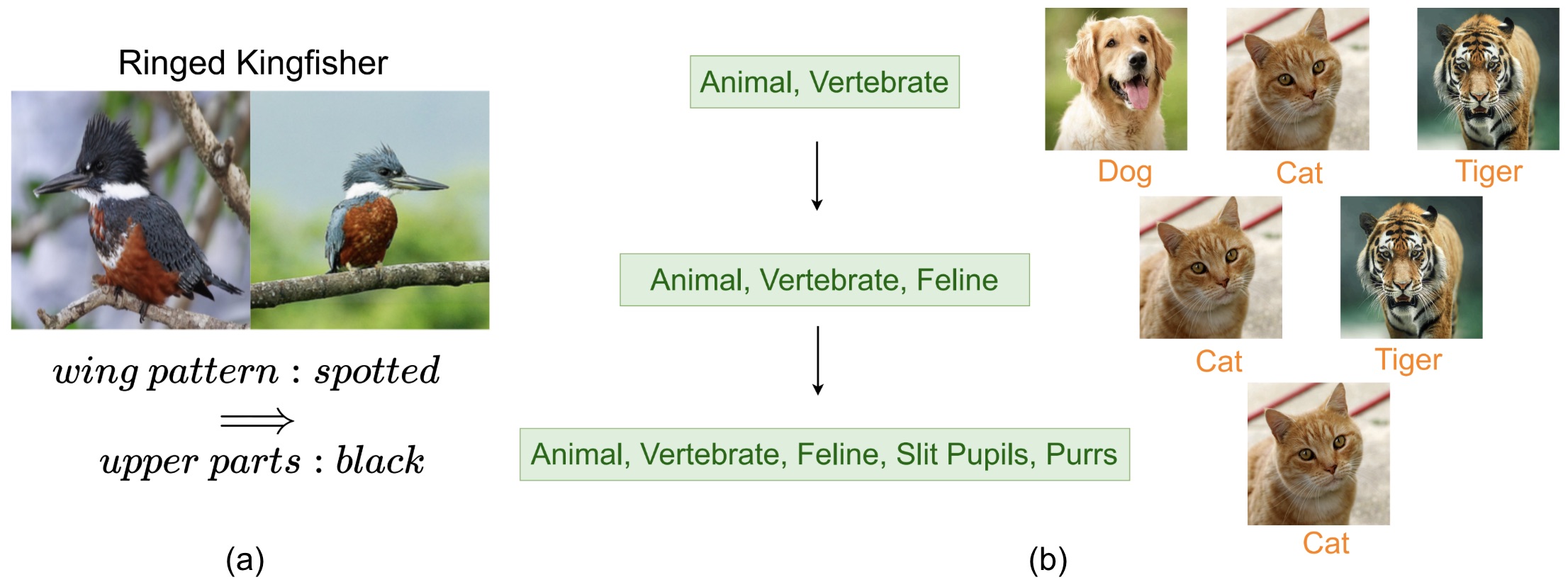 Figure 1: (a) Sample predicate captured by our method on the CUB200 dataset. A Ringed Kingfisher has black upper parts if it has a spotted wing pattern. (b) Attributes shared by more classes are more general.
Figure 1: (a) Sample predicate captured by our method on the CUB200 dataset. A Ringed Kingfisher has black upper parts if it has a spotted wing pattern. (b) Attributes shared by more classes are more general.
Second, from another perspective, most current CBMs do not impose much structure over concepts. It is known that deep neural networks learn hierarchical representations – early layers capture general properties like texture and later layers more class specific information. The exact nature of these representations remains opaque, necessitating the need for more interpretable models. Existing CBMs typically learn all concepts at a single layer, overlooking the inherent hierarchical structure in neural network representations across multiple layers. So the question we ask in this work is: Can we align a neural network’s depth-wise representation with a semantic hierarchy? To this end, we explicitly guide the network to learn general concepts in early layers and specific ones in deeper layers. In our concept-based classification setting, a natural semantic hierarchy emerges from the pattern of concept sharing. Concepts shared by many classes are general, while those shared by a few are specific. For instance, a cat and tiger are an animal, vertebrate and are feline; while a dog, cat and tiger are an animal and are a vertebrate (Fig 1(b)). Here, the latter group {animal, vertebrate} is more general as it spans more classes. To model such a semantic structure, we draw on Formal Concept Analysis (FCA) to construct a concept lattice from binary concept-class associations. We then show how to provide supervisory signals from the lattice to learn concepts at different layers in the network according to their level of generality – each deeper group being more specific. We empirically observe that our models learn more interpretable embeddings, support more effective interventions, and learn concept representations that are hierarchically structured. This work is currently under review at an A* conference.
Is there an aspect of your research that has been particularly interesting?
I’d say the most intellectually stimulating part of my research has been the fundamental questions it raises. Questions like what exactly does a concept mean? This is very domain and task specific and thinking of ways to rigorously define them has been quite interesting. The Formal Concept Analysis work that I spoke about earlier was in part a step towards this. In some current work that I’m doing, we’ve been working with videos and thinking about what concepts mean in this setting.
Another interesting aspect has been about metrics. When we think about Concept-Based Learning and interpretability in general, final task accuracy is no longer the only metric we want to optimize for. So a big part of my research is thinking about other aspects of these models to measure. In my logic-based CBMs work, we propose a worst-case metric for CBMs where we measure how much the confidence of a concept-based model improves when some misleading information is removed. For example, certain species of dogs have pointy ears, although it is more common in cats. If a model incorrectly predicts cat for such an image, our metric measures whether turning off the misleading concept pointy ears increases the model’s confidence in the correct class (dog). We observed that a lot of concept-based models actually don’t do that well on this metric, whereas LogicCBMs do, which was interesting.
You’ve recently started an internship in Canada. How is that going so far, and what research project are you working on?
Yes, I’ve recently started an internship at the Vector Institute, where I’m working with Dr Kelsey Allen from UBC. The problem that we’re studying is how to meaningfully represent context in VLMs for VideoQA tasks. Now, typically the way that videos are processed by these models is that some sort of sampling is first done to get some frames, the frames are broken down into patches and are subsequently encoded to get attended to by the input tokens. Patches of a frame of a video didn’t seem like a meaningful unit to learn in terms of, especially in the case of a long video where long range dependencies could entirely get missed. We instead propose representing the video as a concept graph.
What are your plans for building on your research? Are there any other aspects of the topic you’d like to explore?
Oh yes! I think there’s a lot to do in this space. One direction that I’ve been actively thinking about is extending this paradigm of learning to an embodied AI setting. This would give a way of doing causal analysis on agents – examining how they would react to concept-based changes.
Another direction that I’ve been thinking about is this idea of unified concept spaces – in the context of multimodal concepts. Concepts are abstractions and each modality could give us different view points of the same concept. For example, the concept graspability could be captured through object shape and orientation in the vision modality, its relation to the environment in the language modality and the steps the agent would take to pick it up in the action modality. Yet, these are all expressions of the same underlying concept. This raises the question of whether we can find or learn a unified concept space that is shared across these encoders.
I’m interested in what inspired you to go into the field of AI. Could you tell us a bit about that?
My first foray into the field was during my undergrad. I got selected for a program at a company during my 2nd year and our mentor over there happened to be giving a series of talks on An Introduction to AI. Having always had a fascination for how the brain works and having read a fair share of sci-fi, I was intrigued. A couple of us were offered the chance to attend these talks. These talks were happening during our semester, so I remember having to go to college and after classes having to take a bus with a friend for about an hour to get to the company to attend the talks. But it was totally worth it. I distinctly remember my mind being blown when I first understood the concept of “fitting” in machine learning and excitedly calling a friend to explain what I had learned. One thing led to another. I did a couple of machine learning projects during my undergrad and decided to do a Master’s in AI to see whether I wanted to pursue research in this field, and I did. So here I am.
And finally, how did you find the Doctoral Consortium experience at AAAI?
It was a great experience! Meeting other PhD students and learning about their research was very inspiring. I enjoyed presenting my research and got some nice feedback and suggestions.
The invited talks were also very helpful – especially the advice on transitioning into academia/industry post PhD.
About Deepika

|
Deepika Vemuri is a PhD student from the department of AI at IIT Hyderabad. She is a part of the Machine Learning and Vision Group supervised by Dr Vineeth N Balasubramanian and is supported by the PMRF Fellowship. Broadly, she is interested in bridging the gap between data-driven models and symbolic learning which she explores through the lens of Concept-Based Learning with a focus, also, on the interpretability of these models. She is always eager to explore new things and has lots of other interests including music, art, literature and writing. |
tags: AAAI, AAAI Doctoral Consortium, AAAI2026, ACM SIGAI

AUAI is supported by:








