
ΑΙhub.org
Back to the future: towards a reasoning and learning architecture for ad hoc teamwork
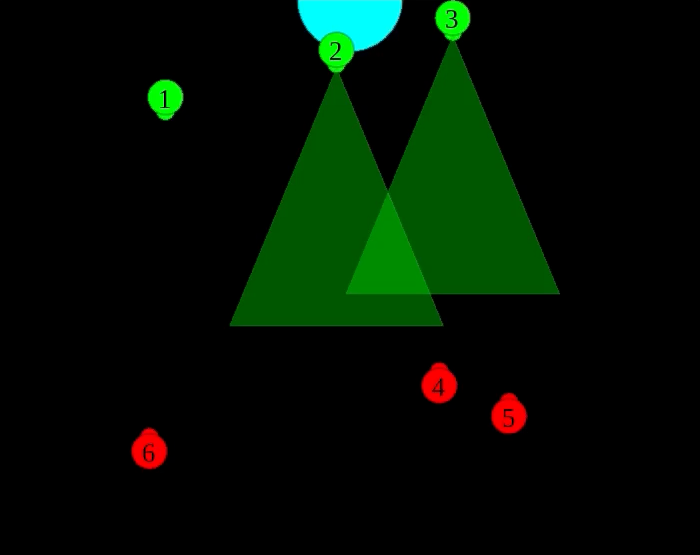 Figure 1: Screenshot from the Fort Attack environment.
Figure 1: Screenshot from the Fort Attack environment.
Consider a team of three guards (in green) trying to defend a fort from a team of three attackers (in red) in Figure 1. In this “Fort Attack” (FA) domain, each agent can move in one of four cardinal directions with a particular velocity, rotate clockwise or anticlockwise, shoot at an opponent within a given range, or do nothing. Each agent may have partial or full knowledge of the state of the world (e.g., location, status of each agent) at each step, but it has no prior experience of working with the other agents. Also, each agent may have limited (or no) ability to communicate with others. An episode ends when all members of a team are eliminated, an attacker reaches the fort, or the guards protect the fort for a sufficient time period.
Ad hoc teamwork (AHT) refers to this problem of enabling an “ad hoc agent” to collaborate with others without prior coordination. It is representative of many real-world applications, e.g., a team of robots and software systems assisting humans in a search and rescue operation after a natural disaster. It requires the ad hoc agent to reason with different descriptions of prior knowledge and uncertainty. For example, the agent may possess qualitative commonsense knowledge of the typical location or behavior of certain agents or objects (“attackers typically spread and attack the fort”), and it may have quantitative (probabilistic) models of the uncertainty in its perception and action outcomes. It will also have to revise its knowledge, inferred beliefs, and action choices in response to dynamic changes, e.g., in the attributes of other agents or in the composition of the team. Furthermore, collaboration will be more effective if the ad hoc agent can justify its decisions and beliefs.
Early work in AHT determined an ad hoc agent’s actions by choosing from predefined protocols that defined suitable actions for specific states. Given the current proliferation of data-driven methods, the state of the art in AHT corresponds to methods that determine the ad hoc agent’s actions based on data-driven (probabilistic, deep network) models and policies learned from a long history of past experiences of the other agents or agent types. However, these methods do not fully leverage the available domain knowledge, require large amounts of labeled training data, and make it difficult to understand and justify the ad hoc agent’s decisions.
In a departure from existing work, our architecture formulates AHT as a joint reasoning and learning problem. We draw on findings in cognitive systems, particularly the principles of step-wise iterative refinement and ecological rationality, for reliable and efficient reasoning and learning. Specifically, the ad hoc agent represents prior knowledge of the domain, e.g., knowledge of some agent and domain attributes, and some rules governing action outcomes, at different resolutions. The finer-granularity description is defined formally as a refinement of the coarser-granularity description [3]. For any given goal, this formal coupling allows the agent to automatically identify and reason with the relevant knowledge at the appropriate resolution. It also enables the agent to use different mechanisms to reason with its knowledge, e.g., efficiently combine the complementary strengths of non-monotonic logical reasoning and stochastic reasoning for elegant revision of previously held beliefs as needed.
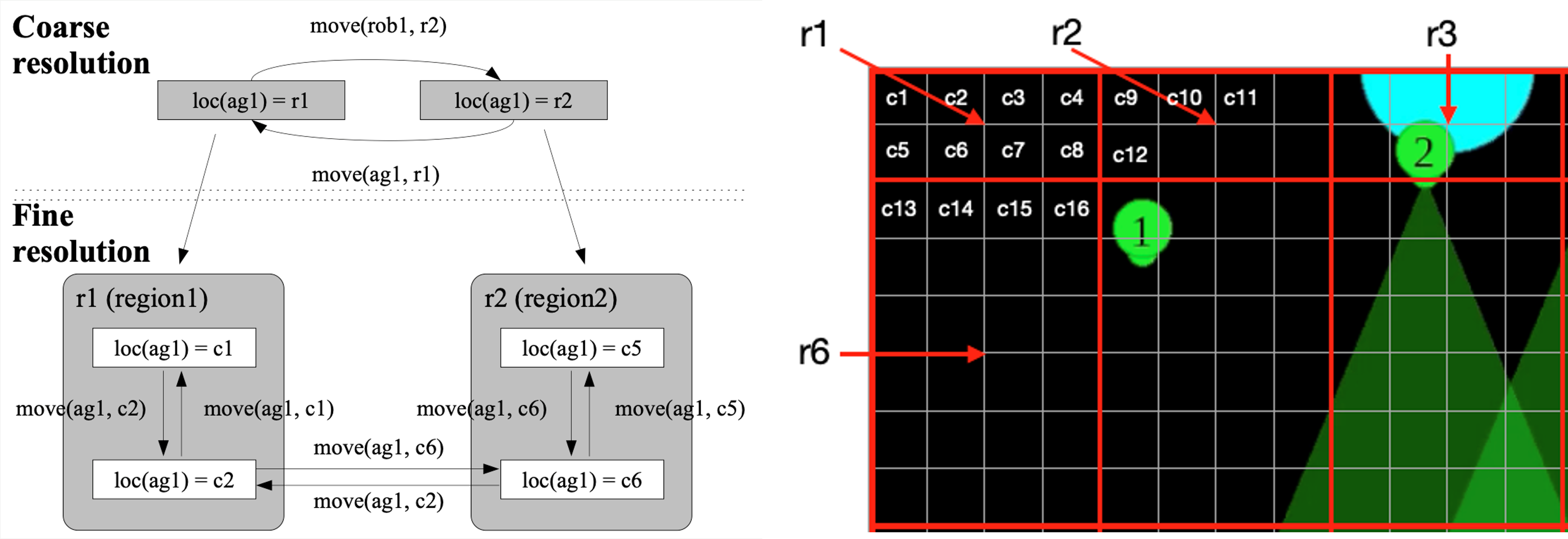 Figure 2: State transitions for a move action in coarse resolution and fine resolution; the places are further divided in to smaller grid cells in finer resolution.
Figure 2: State transitions for a move action in coarse resolution and fine resolution; the places are further divided in to smaller grid cells in finer resolution.
The other key advantage of our architecture is that it enables the ad hoc agent to rapidly and incrementally learn models of the behaviour of other agents from limited examples. This learning is based on the principle of ecological rationality (ER), which in turn builds on Herb Simon’s definition of bounded rationality. ER explores decision making under uncertainty, characterizes behavior as a function of the environment and the internal (cognitive) processes of the agent, and focuses on adaptive satisficing [2]. It advocates the design of: (i) heuristic methods to make decisions more quickly, frugally, and/or accurately than complex methods; and (ii) an adaptive toolbox of classes of simple heuristic methods (e.g., one-reason, sequential search, lexicographic), using statistical testing to select methods that leverage the domain’s structure. This approach has provided good performance in many practical applications that require rapid decisions under resource constraints. In our architecture, the ad hoc agent to use an ensemble of “fast and frugal” (FF) decision trees to learn predictive models of the action choices of other agents in specific states. Each tree in this ensemble provides a binary class label and has its number of leaves limited by the number of attributes. Also, the ensemble can be revised incrementally, with consistent agreement (disagreement) with an existing model’s predictions triggering model choice (revision).
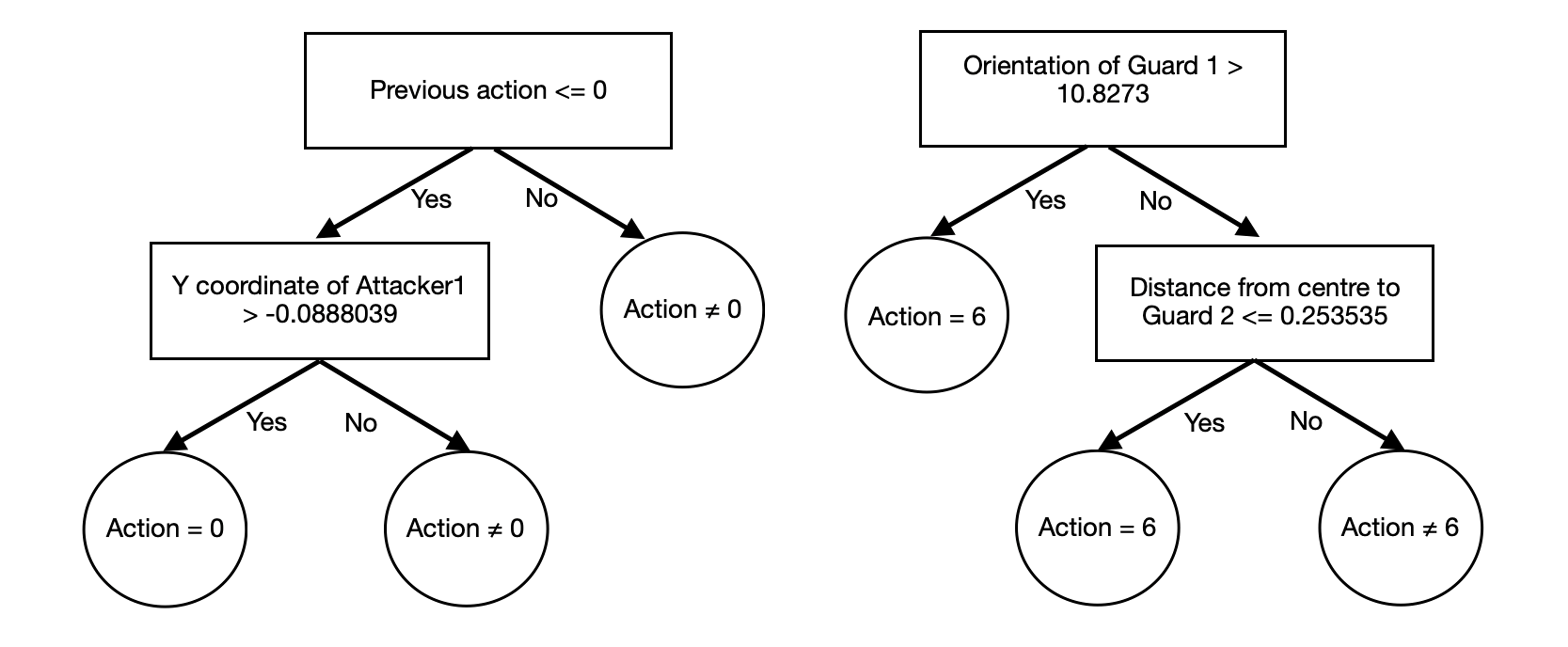 Figure 3: Fast and frugal trees created for an attacker type and guard type agent respectively.
Figure 3: Fast and frugal trees created for an attacker type and guard type agent respectively.
We experimentally evaluated our architecture in the FA domain with one of the guards as our ad hoc agent. We set up some simple hand-crafted policies (e.g., “attackers spread and approach the fort”. “guards spread and protect the fort”) and used only 10000 state-action observations obtained from the use of these policies to train the initial FF trees. We then evaluated the ad hoc agent in episodes in which actions of other agents (teammates and opponents) were based on sophisticated deep (graph) neural networks that needed order of magnitude more training examples. The ad hoc agent computed plans to achieve its goal (e.g., eliminate all attackers) by reasoning with prior knowledge of the domain and the predicted actions of other agents. It also revised the predictive models as appropriate. We experimentally demonstrated that our architecture:
- enabled adaptation to different teammate and opponent types;
- supported incremental learning of models of other agents’ behavior from limited examples;
- provided better performance than a state of the art data-driven method for AHT; and
- supported the generation of relational descriptions of the ad hoc agent’s decisions and beliefs.
In particular, the ad hoc agent increased the number of episodes won and the fraction of times when shooting eliminated an opponent (i.e., shooting accuracy), in comparison with a baseline that used several million examples to train a deep (graph) neural network that determines the ad hoc agent’s actions.
Video 1: Adapting to unexpected domain and team composition changes.As an illustrative example, in Video 1, agent “1” is the ad hoc guard agent controlled by our architecture. It successfully prevents a sneak attack attempt from attacker “6” which stays outside the shooting range of guard “3” while approaching the fort. Also, in Video 2 the ad hoc agent only shoots when required and chooses its actions by anticipating the moves of the other agents. For additional experimental results, link to videos, and examples of the ad hoc agent’s ability to answer different types of questions about its decisions and beliefs, please see [1].
Video 2: Efficient shooting only when necessary.References
[1] Hasra Dodampegama and Mohan Sridharan. Back to the Future: Toward a Hybrid Architecture for Ad Hoc Teamwork, AAAI Conference on Artificial Intelligence. Feb. 2023.
[2] Gerd Gigerenzer. “What is Bounded Rationality?” In: Routledge Handbook of Bounded Rationality, 2020.
[3] Mohan Sridharan et al. REBA: A Refinement-Based Architecture for Knowledge Representation and Reasoning in Robotics, Journal of Artificial Intelligence Research, 2019.
tags: AAAI, AAAI2023

AUAI is supported by:








