
ΑΙhub.org
Diffusion beats autoregressive in data-constrained settings
TLDR:
If you are compute-constrained, use autoregressive models; if you are data-constrained, use diffusion models.
Motivation
Progress in AI over the past decade has largely been driven by scaling compute and data. The recipe from GPT-1 to GPT-5 has appeared straightforward: train a larger model on more data, and the result is a more capable system.

Yet a central question remains: will this recipe continue to hold from GPT-6 to GPT-N?
Many analysts and researchers believe the answer is no. For instance, Ilya Sutskever, in his NeurIPS 2024 Test-of-Time Award talk, remarked: “Compute is growing—better algorithms, better hardware, bigger clusters—but data is not growing. We have just one internet, the fossil fuel of AI.”
This concern is echoed by AI forecasters, who have analyzed compute and data growth more systematically and concluded that compute is outpacing data at an accelerating rate.

The above Figure, illustrates this tension by overlaying projections from EpochAI’s analysis. Their study extrapolates historical trends in compute, dataset usage, and internet-scale data availability. The forecast suggests that by around 2028, we will enter a data-constrained regime: far more compute will be available than there are training tokens to consume.
This paper addresses the challenge by asking: how can we trade off more compute for less data? Our central idea is to revisit the foundations of modern generative modeling and compare the two dominant paradigms for scaling AI.
Broadly, there have been two families of algorithms that shaped recent progress in AI:
- Autoregressive models, popularized in 2019 in the text domain with the GPT-2 paper.
- Diffusion models, popularized in 2020 in the vision domain with the DDPM paper.
Both aim to maximize the joint likelihood, but they differ fundamentally in how they factorize this joint distribution.
The success of diffusion in vision and autoregression in language has sparked both excitement and confusion—especially as each community has begun experimenting with the other’s paradigm.
For example, the language community has explored diffusion on text:
D3PM introduced discrete diffusion via random masking, while Diffusion-LM applied continuous diffusion by projecting tokens to embeddings before adding Gaussian noise. Since then, numerous works have extended this line of research.
Conversely, the vision community has experimented with doing autoregressive modeling on images. Models such as PARTI and DALLE exemplify this approach with strong results.
This cross-pollination has led to even greater uncertainty in robotics, where both diffusion-based and autoregressive approaches are widely adopted. To illustrate this, OpenAI Deep Research has compiled a list of robotics works across both paradigms, highlighting the lack of consensus in the field.

This ambiguity raises a fundamental question: should we be training diffusion models or autoregressive models?
Quick background:
Autoregressive language models:

They model data distribution in a left-to-right manner
Diffusion language models:

For a more detailed understanding, with cool animations, please refer to this video from Jia-Bin Huang – https://www.youtube.com/watch?v=8BTOoc0yDVA
Prior results with diffusion language models
Since 2021, diffusion language models have sparked significant interest, with many works focusing on improving their design and performance.

In the table above, we highlight representative results from a popular work.
The takeaways are as follows:
- Discrete diffusion performs better than continuous diffusion on text.
- Autoregressive models still achieve the strongest results overall.
Several works have also explored the scaling behavior of diffusion-based language models.

Nie et al report that discrete diffusion LLMs require roughly 16× more compute than autoregressive LLMs to match the same negative log-likelihood. Similar results have been observed in multimodal domains—for instance, UniDisc finds that discrete diffusion needs about 12× more compute than autoregression for comparable likelihoods.
However, these results conflate data and compute because they are measured in a single-epoch training regime. This raises an important ambiguity: do diffusion models truly require 16× more compute, or do they in fact require 16× more data?
In this work, we explicitly disentangle data and compute. Our goal is to study diffusion and autoregressive models specifically in data-constrained settings.
Our motivation
To understand why diffusion may behave differently, let’s revisit its training objective.

In diffusion training, tokens are randomly masked and the model learns to recover them. Importantly, left-to-right masking is a special case within this framework.

Viewed this way, diffusion can be interpreted as a form of implicit data augmentation for autoregressive training. Instead of only learning from left-to-right sequences, the model also benefits from many alternative masking strategies.
And if diffusion is essentially data augmentation, then its benefits should be most pronounced when training is data-bottlenecked.
This perspective explains why prior works have reported weaker results for diffusion: they primarily evaluated in single-epoch settings, where data is abundant. In contrast, our study focuses on scenarios where data is limited and compute can be traded off more effectively.
Our experiments
In this work, we train hundreds of models spanning multiple orders of magnitude in model size, data quantity, and number of training epochs to fit scaling laws for diffusion models in the data-constrained setting. We summarize some of our key findings below.
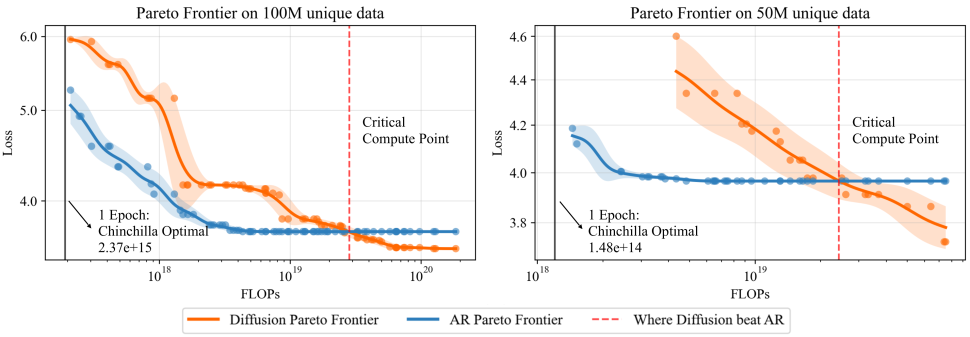
Finding #1:

Diffusion models outperform autoregressive models when trained with sufficient compute (i.e., more epochs & parameters). Across different unique data scales, we observe:
- At low compute, Autoregressive models win.
- After a certain amount of compute, performance matches—we call this the critical compute point.
- Beyond this, diffusion keeps improving, while Autoregressive plateaus or overfits.
Each point in the figure shows a model trained to convergence. The x-axis shows the total training FLOPs of that point, and the y-axis shows the best validation loss achieved by that model family under that training compute budget.
Finding #2:

Autoregressive models begin to overfit much quickly, while diffusion shows no signs of overfitting even after 10x the number of epochs. In the above figure, we showed that increasing compute eventually favors diffusion. But compute can be scaled in two ways: (i) Increasing model size (ii) Increasing the number of epochs In the following plot, we separate these axes.
The colored star marks the 1-epoch point, where Autoregressive outperforms diffusion. The star (★) denotes the best loss achieved by each model.
- Autoregressive hits its best around the middle, then overfits.
- Diffusion keeps improving and reaches its best loss at the far right.
Not only does diffusion benefit from more training—it also achieves a better final loss than Autoregressive (3.51 vs. 3.71).
Finding #3:

Diffusion models are significantly more robust to data repetition than autoregressive (AR) models.
We show training curves of models trained with the same total compute, but different trade-offs between unique data and number of epochs.
An “epoch” here means reusing a smaller subset of data more times(e.g., 4 Ep is 4 epochs while using 25% unique data, 2 Ep is 2 epochs with 50% and so on).
- AR models begin to overfit as repetition increases—their validation loss worsens and significantly diverges at higher epoch counts.
- Diffusion models remain stable across all repetition levels, showing no signs of overfitting or diverging—even at 100 epochs.
Finding #4:

Diffusion models exhibit a much higher half-life of data reuse (R_D*) —i.e., the number of epochs after which returns from repeating data begins to significantly diminish.
We adopt the data-constrained scaling framework introduced by Muennighoff et al. in their excellent NeurIPS paper to fit scaling laws for diffusion models. While Muennighoff et al. found R_D* ~ 15 for autoregressive models, we find a significantly higher value of R_D* ~ 500 for diffusion models—highlighting their ability to benefit from far more data repetition.

The above Figure studies the Decay rate of data value under repetition: left shows diffusion, middle AR, and right the average decay rate for both.
Points are empirical results (darker color = higher FLOPs, lighter color =
lower FLOPs; each line = fixed compute), we find that fitted curves (represented as lines) closely match the empirical points, indicating our scaling laws are representative. The decay rate of value for repeated data is lower for diffusion, reflecting its greater robustness to repeating. In this experiment 100% data fraction means training 1 epoch with 100% unique data, while 50% means 2 epoch epoch with only using 50% unique data and so on.
Finding #5:

Muennighoff et al. showed that repeating the dataset up to 4 epochs is nearly as effective as using fresh data for autoregressive models.
In contrast, we find that diffusion models can be trained on repeated data for up to 100 epochs, while having repeated data almost as effective as fresh data.
Finding #6:
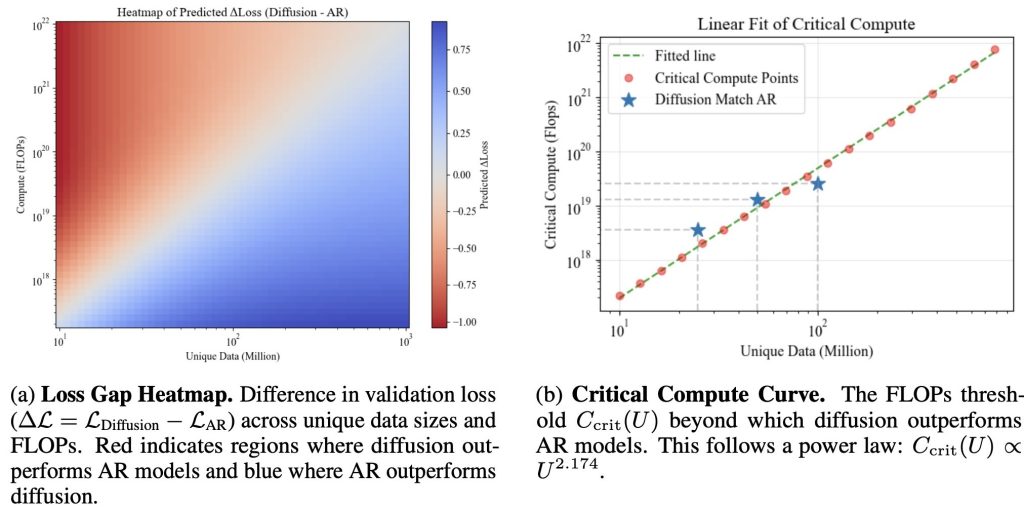
The compute required for diffusion to outperform AR follows a predictable power law. Above we defined the critical compute threshold as the amount of FLOPs where diffusion matches AR performance for a given unique dataset size.

We find that we can derive a simple closed-form analytical expression for this threshold, this allows us to predict when diffusion will surpass AR given any unique data size. In the figure we show both the fitted curve and empirical critical threshold points, which align closely.
Finding #7:

The data efficiency of diffusion models translates to better downstream performance.
Lastly we evaluate the best-performing diffusion and AR models (trained under the same data budget) on a range of language understanding tasks.
Across most benchmarks, diffusion models outperform AR models, confirming that diffusion’s lower validation loss translates to better downstream performance.
Finding #8:
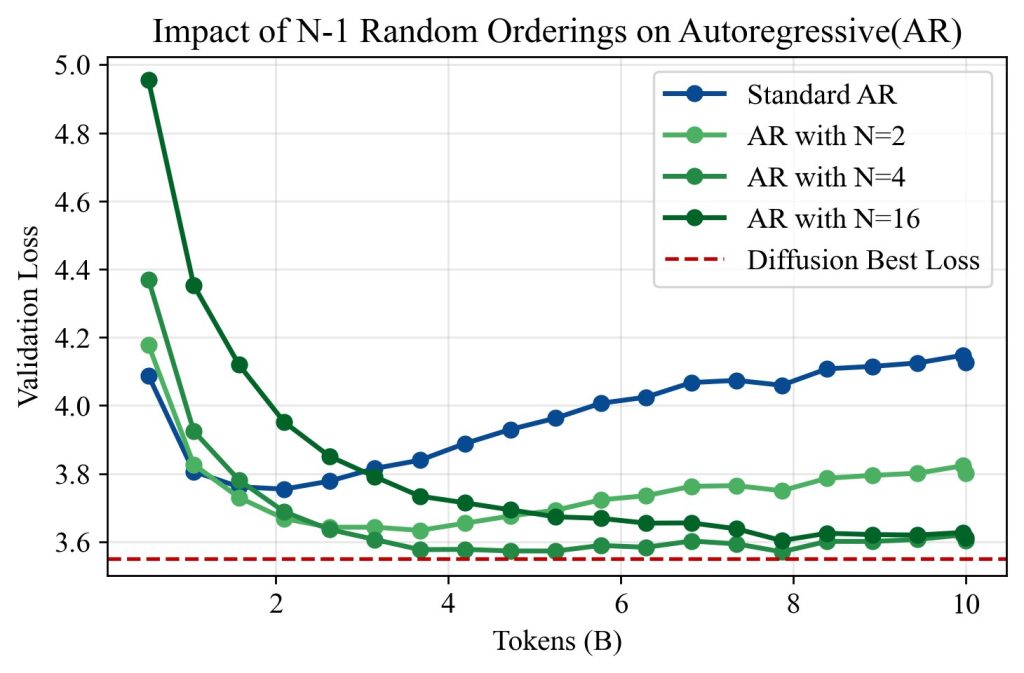
Exposure to different token orderings helps explain diffusion’s data efficiency. By adding explicit data augmentations to AR training, we find that diffusion model’s advantage arises from their exposure to a diverse set of token orderings.
As seen in the above Figure, increasing N consistently lowered validation loss and delayed overfitting. At N = 16, the 100-epoch validation loss of AR models approached that of diffusion, suggesting that diverse orderings are indeed a key driver of diffusion’s data efficiency. These results support our interpretation that diffusion models outperform AR models in low-data regimes because they are implicitly trained on a richer distribution of conditional prediction tasks.
Finally, this analysis suggests a natural continuum between the two paradigms: by controlling task diversity through masking or reordering—we could design hybrid models that interpolate between compute efficiency (AR-like) and data efficiency (diffusion-like).
For more experiments and details please refer to original paper.
Conclusion
As the availability of high-quality data plateaus, improving data efficiency becomes essential for scaling deep learning. In this work, we show that masked diffusion models consistently outperform autoregressive (AR) models in data-constrained regimes — when training involves repeated passes over a limited dataset. We establish new scaling laws for diffusion models, revealing their ability to extract value from repeated data far beyond what AR models can achieve.
These results challenge the conventional belief that AR models are universally superior and highlight diffusion models as a compelling alternative when data—not compute—is the primary bottleneck. Looking ahead, efficient use of finite data may define the next frontier in scaling deep learning models. Although the studies have been performed in the context of language models, we believe these findings should apply across any kind of sequence modeling data, such as in robotics or healthcare. For practitioners, our takeaway is simple: if you are compute-constrained, use autoregressive models; if you are data-constrained, use diffusion models.
Bibtex:
@article{prabhudesai2025diffusion,
title={Diffusion Beats Autoregressive in Data-Constrained Settings},
author={Prabhudesai, Mihir and Wu, Mengning and Zadeh, Amir and Fragkiadaki, Katerina and Pathak, Deepak},
journal={arXiv preprint arXiv:2507.15857},
year={2025}
}
This article was initially published on the ML@CMU blog and appears here with the author’s permission.
tags: deep dive

AUAI is supported by:








