
ΑΙhub.org
Policy design for two-sided platforms with participation dynamics: interview with Haruka Kiyohara
In their paper Policy Design for Two-sided Platforms with Participation Dynamics, which was presented at ICML 2025, Haruka Kiyohara, Fan Yao and Sarah Dean investigated the participation dynamics in two-sided markets. In this interview, Haruka tells us more about such two-sided platforms, the main contributions of the work, and the experiments carried out to test the method.
What is the topic of the research in your paper and why is it an interesting area for study?
Our paper studied the long-term impacts of decision-making algorithms on two-sided platforms like e-commerce or music streaming applications. In two-sided platforms, multiple stakeholders, such as viewers and content creators, are involved. Conventionally, research papers on such problems assumed that both stakeholders are static, or at best, considered only the dynamics of one of the participants. This tendency was typical, especially regarding population or engagement level, to simplify the evaluation framework. However, these assumptions may not be the case in practice, and highlighting the missing points is crucial to make the research findings more practically applicable. We were interested in how the preferred algorithm design changes in practical situations where both viewers and providers co-evolve depending on the algorithms’ decisions.
What aspect of the problem do you study in your work?
We specifically studied the participation dynamics in two-sided markets. In a practical situation, it is common that viewers and providers can change their engagement level based on their payoffs. For example, if a user is satisfied with the service, they may refer their friends to the service, or if they are unsatisfied, they may cancel their subscription. Similarly, we have content creator side dynamics as well, and they will change their efforts on content production, or may withdraw the online resources if their content does not gain enough attention from viewers. We modeled such population growth and shrinkage per viewer and provider subgroups (e.g., clustering viewers and providers based on their interests or features), and studied their dynamics and long-term impacts.
Could you talk about how you went about studying the population dynamics – what was your methodology?
We used control- and game-theoretical approaches to investigate the dynamics. To model a simple yet generalizable dynamics, we first assumed that the subgroup population gradually moves towards the “reference population” that depends on their payoffs. Specifically, we introduce an arbitrary monotonic (and concave) function as the “reference population” function to map from the viewer satisfaction and content exposure. This means that the “reference population” becomes large when the viewer and provider payoffs increase. We can justify the existence of such a function by the viewers’ and providers’ (inner) payoff seeking behavior that tries to maximize their payoff considering some costs for platform participation. Because viewer satisfaction and content exposure can depend on the content-allocation algorithm in the platform, the design of the algorithm (or “policy” in other words) is impactful to the long-term dynamics. A key additional consideration is that the viewer’s satisfaction not only depends on the allocation policy, but also depends on the content creator population. This is quite reasonable in a practical situation where viewer satisfaction is determined by both the viewer’s preferences and the quality of the content, where the competition among a large population of content providers often improves the overall quality of content.
What were your main findings?
There are a few takeaways from our theoretical analysis. One of the most important research questions in our study is whether the default approach to recommendation, which greedily optimizes the algorithm based on the current utility (and current population), remains the preferable strategy or not in a practical situation with population dynamics. The short answer is “No” – or not always. Our analysis revealed that the default, greedy approach is guaranteed to be long-term optimal only when the “population effect” functions, which measures how the content population affects the quality of content, is linear and homogeneous. In other words, when the “population effect” is heterogeneous, the greedy policy fails by introducing richer-gets-richer dynamics. This is because the “cross-over” effects, where content group A that initially had a higher reward than B may become less important after the population change can happen under heterogenuous population effects. Similarly, when there are some saturations after growing the population to some extent, it is possible that a myopic greedy policy falls short by failing to grow the pie (i.e., grow the total population) of the platform. Moreover, our analysis revealed that the exposure-distributing policy, which allocates content exposure to even myopically sub-optimal content groups, may improve the long-term social welfare in the long run by effectively growing the pie of the total population. These findings especially highlight the importance of allocating exposure to items that currently have low quality but have potential for future growth, such as a new category of products or a new technology.
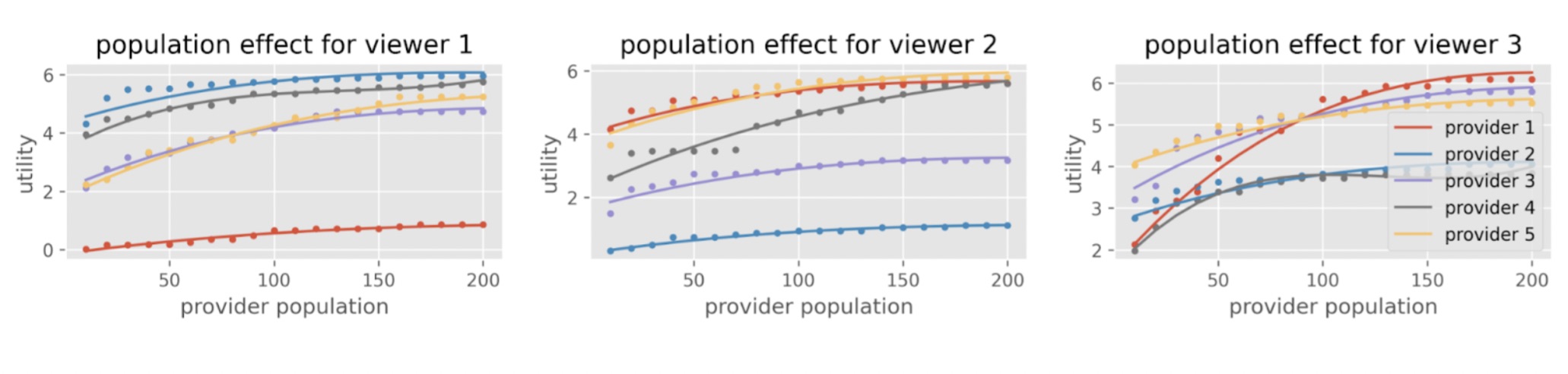 Figure 1: Examples of heterogeneous population effects with saturation in the KuaiRec dataset [1]. We can see that, while the utility (a.k.a. content quality) grows as the content population increases, its growth is different among content subgroups and there is “cross-over” at some points. Also, after increasing the content population to some extent, we see the “saturation” for the population growth.
Figure 1: Examples of heterogeneous population effects with saturation in the KuaiRec dataset [1]. We can see that, while the utility (a.k.a. content quality) grows as the content population increases, its growth is different among content subgroups and there is “cross-over” at some points. Also, after increasing the content population to some extent, we see the “saturation” for the population growth.
Could you say a bit about the algorithm that you’ve proposed to optimize long-term social welfare?
Based on the aforementioned findings, we proposed a simple algorithm that accounts for the long-term dynamics. The proposed algorithm is called the “look-ahead” policy, and the key point is to optimize the policy at the reference point (i.e., the target point the viewer and provider populations move toward, which can be estimated via regression using online data) instead of the myopic population.
We tested the proposed method in two representative cases where the myopic policy can fail (case 1, synthetic data) and can be long-term optimal (case 2, public data [1]). The results demonstrate that, in case 1, the proposed method achieves much higher performance than both the greedy policy and the fully exposure-distributing policy (called uniform), and improves both the viewer and provider populations at convergence compared to these baselines. Moreover, even in the case where the myopic-greedy policy can be long-term optimal, the proposed method achieves almost the same performance, while greatly improving the content provider population in the long run.
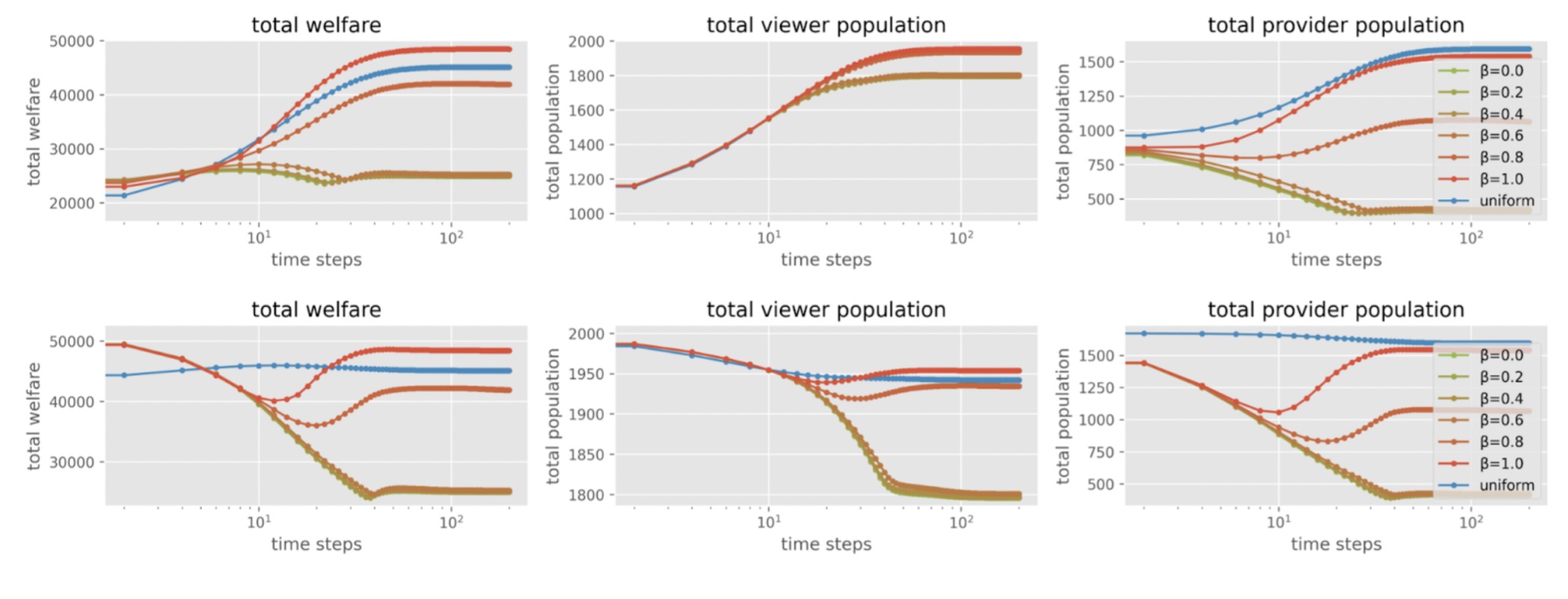 Figure 2: Experiment results in case 1 (where myopic-greedy falls short). β = 0.0 is the myopic greedy policy and β = 1.0 is the proposed look-ahead policy. Other values of β is the linear interpolation between myopic greedy and the look-ahead. The top figure starts from a small initial population, while the bottom figure starts from a large initial population. These results are from the synthetic data experiments.
Figure 2: Experiment results in case 1 (where myopic-greedy falls short). β = 0.0 is the myopic greedy policy and β = 1.0 is the proposed look-ahead policy. Other values of β is the linear interpolation between myopic greedy and the look-ahead. The top figure starts from a small initial population, while the bottom figure starts from a large initial population. These results are from the synthetic data experiments.
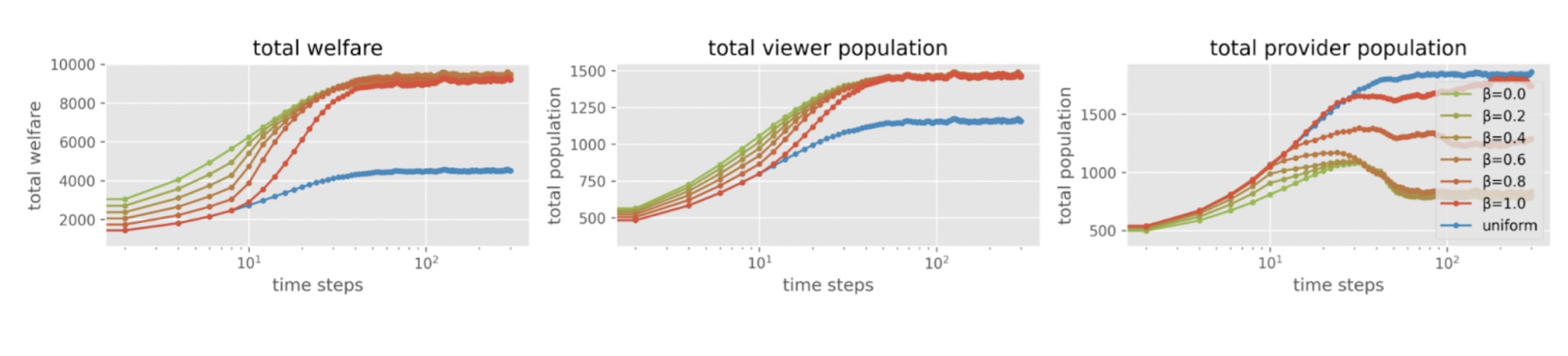 Figure 3: Experiment results in case 2 (where myopic-greedy is long-term optimal). β = 0.0 is the myopic greedy policy and β = 1.0 is the proposed look-ahead policy. Other values of β is the linear interpolation between myopic greedy and the look-ahead. These results are from the KuaiRec [1] data semi-synthetic experiments.
Figure 3: Experiment results in case 2 (where myopic-greedy is long-term optimal). β = 0.0 is the myopic greedy policy and β = 1.0 is the proposed look-ahead policy. Other values of β is the linear interpolation between myopic greedy and the look-ahead. These results are from the KuaiRec [1] data semi-synthetic experiments.
Are you planning any further research in this area?
This is a really exciting research area, and there are many interesting future works. One thing is, while we have gone through the analysis at the sub-group level in this paper, it would be great to see how we can extend the analysis to the individual level or consider more complex dynamics of the overall population distribution in continuous feature spaces. Diffusion models may be beneficial for this type of analysis.
Another interesting direction is to think about how to give external incentives (such as monetary award) to content creators. It would be worth thinking about the way of promoting “niche” content or new technologies for long-term social welfare, instead promoting a currently succeeding actions and cause “richer-gets-richer” dynamics.
Reference
[1] KuaiRec dataset
About Haruka
 |
Haruka Kiyohara is a third-year Computer Science Ph.D. student at Cornell University. Her research interest lies in evaluating and optimizing decision-making systems using causal inference and machine learning, particularly learning from logged data and optimizing for long-term social goods in recommender systems. Her work has been published at machine learning and data mining conferences, including ICML, NeurIPS, ICLR, KDD, WSDM, and RecSys. Prior to Cornell, she received a B.E. in Industrial Engineering and Economics from Tokyo Institute of Technology. She is supported by the Funai Overseas Scholarship and the Quad Fellowship for her graduate study at Cornell. |
Find out more
ICML paper page
arXiv preprint
Slides
tags: ICML, ICML2025

AUAI is supported by:








