
ΑΙhub.org
Reinforcement learning applied to autonomous vehicles: an interview with Oliver Chang

In this interview series, we’re meeting some of the AAAI/SIGAI Doctoral Consortium participants to find out more about their research. We caught up with Oliver Chang whose research interests span deep reinforcement learning, autonomous vehicles, and explainable AI. We found out more about some of the projects he’s worked on so far, what drew him to the field, and what future AI directions he’s excited about.
Could you give us a quick introduction to who you are, where you’re studying, and the topic of your research?
I’m a fourth year computer science PhD candidate at UC Santa Cruz. I’m specializing in reinforcement learning applied to autonomous vehicles and UAVs. I’m at the stage where I am, one, excited for working towards my dissertation, and two, really robustifying the state of autonomous vehicles through adversarial agents.
Could you tell us about one of your recent projects?
So I’ll highlight my flagship paper, which is on using adversarial reinforcement learning agents to find vulnerabilities in cyber physical systems. You can basically think about a cyber physical system (CPS) as a computer system that interacts with physical hardware. And so my research involved developing adversarial agents.
Typically, a lot of people use AI models for task-driven things. LLMs can answer prompts, computer vision models can recognize images. Well, my work takes a different approach by developing agents that actually do the opposite. Can we develop agents that cause harm? Now, it sounds a bit counterintuitive, but the reason why we would want such a thing is so we can exploit and find safety concerns in the systems that we deploy. And so I use reinforcement learning to develop these adversarial agents. For our experiment, we set up a bunch of cars with our main adversary at the front of the traffic, and the adversary was to find the ideal brake patterns, and it’s supposed to swerve around. And through developing and experimenting with our adversarial agent, we were able to discover vulnerabilities inside of a particular CPS called Adaptive Cruise Control. We further extended this by including lane changing maneuvers, which is something that hasn’t been looked at before.
Is there a project or a piece of work that you’re particularly proud of?
Yeah, so this work I did during my third year of the PhD, and it’s heavily involved with interpretable reinforcement learning. The work was looking at the teacher-student paradigm, where you have a teacher model that’s already an expert in one task, but it’s also giving advice to a student model trying to solve another task. This research builds directly off a prior work that has used interpretability and reinforcement learning to 1) accelerate learning of novelty tasks, and 2) highlight which actions an agent was deemed as relevant or useful for a student. And so, while it was interpretable, and it did a good job of revealing which actions the teacher showed were useful, it was very inefficient. This methodology involved a lot of computational overhead, and it just wasn’t really practical to deploy in real life outside of toy-ish AI tasks.
And so this work that I did, that I was proud of, really accelerated the transfer learning process. I’m a big believer in Occam’s razor, where the simplest solutions are usually the best solutions. And so taking that idea, I kind of stripped away stuff that wasn’t necessary, like bottlenecks in the algorithms. I was looking at what we could remove while still maintaining the integrity of interpretability inside of these AI algorithms. And so, a big challenge was finding the trade-offs in doing that. Basically the prior work used a completely separate neural network model to determine the helpfulness of a teacher. What I did was a bit more of a bootstrap method where the student instead decides whether the teacher is useful or not. And by doing that, we removed a completely whole other neural network to fine-tune in the process and accelerated the students’ learning as well.
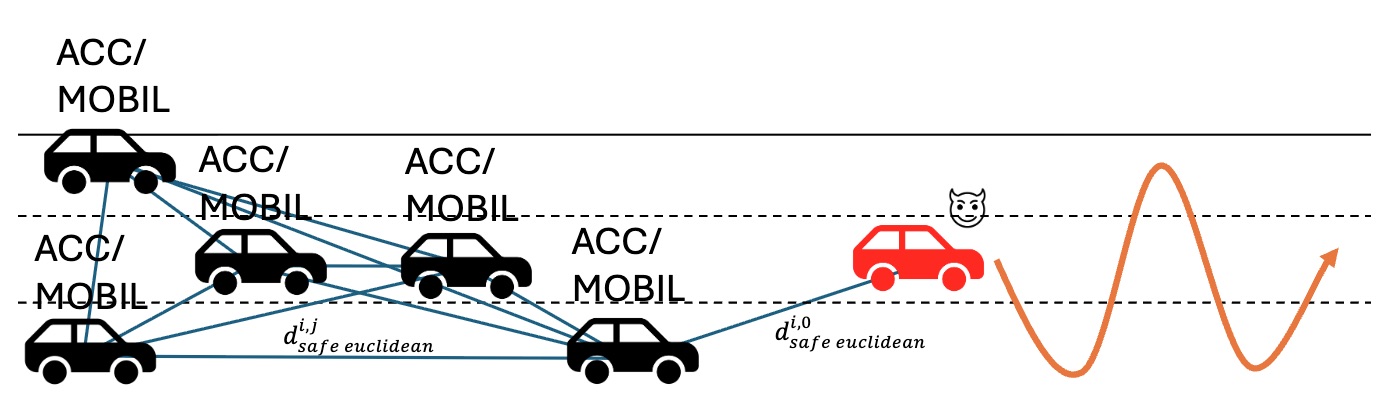 This image demonstrates one of Oliver’s experiments where he trained an adversary with RL to swerve and brake so that any vehicle behind it collides. The black vehicles are controlled through adaptive cruise control with a lane changing protocol (MOBIL).
This image demonstrates one of Oliver’s experiments where he trained an adversary with RL to swerve and brake so that any vehicle behind it collides. The black vehicles are controlled through adaptive cruise control with a lane changing protocol (MOBIL).
The AI landscape has changed quite a lot since you started your PhD. How has that affected your area of research?
I started my PhD in the fall of 2022, and ChatGPT really made its big introduction in the winter of 2023. And that really changed the whole landscape because now everyone was trying to figure out how we can leverage a large language model in some capacity in research. I’ve also dealt with large language models and incorporated them into my research. That being said, though, it needs to be used with caution. It’s not a one-catch-all solution for every problem in the scope of AI. I really see it as just a new tool that was introduced, that we can use to programmatically generate novel text, ideas, and images through natural languages. It can be helpful when used tastefully.
And what are you excited about for the future of your branch of AI?
There’s been a lot of hype lately about agentic AI. And that involves taking a large language model and doing a zero-shot task completion. But I think what people are realizing is that this is awfully a lot like reinforcement learning. Reinforcement learning involves an environment, it involves a Markov decision process. How do we develop an agent that can accomplish such a task? And so I think we’re going to see a resurgence in reinforcement learning, where people are going to leverage ideas that were used in reinforcement learning and adopt them into agentic AI. So I’m looking forward to that – a real agentic approach to AI, where you have some environment, you have some reward model, but you also need an agent that can be adaptable to different tasks as well. To summarize, I think a broad generalizability of agentic agents and reinforcement learning agents is a promising direction where agents can become multifaceted and learn multiple tasks seamlessly.
What was it that inspired you to study AI?
That’s a great question. So this started in my undergrad years when I was a drone hobbyist. I really like tinkering around with drones and robots. And because of that, it made me want to do research with one of my computer science professors who was big on robots and AI as well. And in doing research with them, I realized that the AI stuff is really cool. I like incorporating it with actual agents. I think in part doing research with the professor who I respected and whose work I respected as well was a big part in me wanting to pursue more research in AI.
And on top of that, in high school I interned in a neuroscience lab at Caltech, and I was working a lot with rats and mice. We were doing a lot of experiments trying to incentivize them with water to accomplish tasks while hooking up sensors and measuring their brain patterns. And I think what’s interesting is, unbeknownst to me at the time, what we were doing was really the biological inspiration for modern day AI architecture. The modern day neural network is inspired by how biological brains actually work. And to me, I just thought that was very profound. I thought it was very cool that, as futuristic as AI sounds, a lot of it has its roots in biological systems.
Would you have any advice for people who are thinking of doing a PhD in the field?
A phrase I like to say is “don’t major in the minors”. And what I mean by that is that when you’re doing a PhD, you’re going to have a lot of freedom, you’re going to have to make a lot of decisions on your own. You don’t really have a boss giving you very granular tasks. It’s going to be up to you to decide what to do and how to accomplish that. And I think what I struggled with early on, and perhaps what I still struggle with to this day, is focusing a lot on the minor details of work. For example, if I’m working on a paper, maybe I’ll spend a good half an hour deciding the layout of the paper. Or if I’m running an experiment, maybe I focus too much on writing the most perfect comment or writing the most beautiful code. But all that stuff has taken time out of your day and it’s not what’s going to really deliver results. At the end of the day, you have to focus on the big picture tasks and go out and accomplish them. By focusing too much on the granular detail, you lose sight of the big picture and important tasks that need to be accomplished. So I would say to prospective PhD students that your time is only finite, you can only make trade-offs with time – you’ve got to make the most of it.
For our final question, could you tell us an interesting (non-AI related) fact about you?
I’m an avid runner. So a couple months ago, I did my first marathon and ran a time of 2:22. So I was very happy with how that went. I ran all throughout high school and I was very competitive. I ran cross country and track, and I was fast enough, and thankfully studious enough, such that I was able to run at a Division III school and compete at a collegiate level. I ran for Pomona-Pitzer and I had a really good time there. I made a lot of friends and it was a really competitive yet academic environment which was just perfect for me. To this day, I still run for fun and it’s really just a way to keep me on a strict schedule. It keeps me regimented, and it’s a good way to de-stress after doing research all day. It’s a lifelong hobby and one that I hope to continue.
About Oliver

|
Oliver Chang is a 4th-year PhD student at UC Santa Cruz, advised by Professor Leilani Gilpin. His research interest is in applying reinforcement learning to train adversarial agents to find vulnerabilities in autonomous systems. Chang’s work has been published in RLC and AAMAS. During his PhD he interned at Lumentum. Outside of research, Oliver is an avid runner, having competed cross country and track for Pomona-Pitzer and UC Santa Cruz at a Division III level. |
tags: AAAI, AAAI Doctoral Consortium, AAAI2026, ACM SIGAI

AUAI is supported by:








