
ΑΙhub.org
See, Hear, Explore: curiosity via audio-visual association
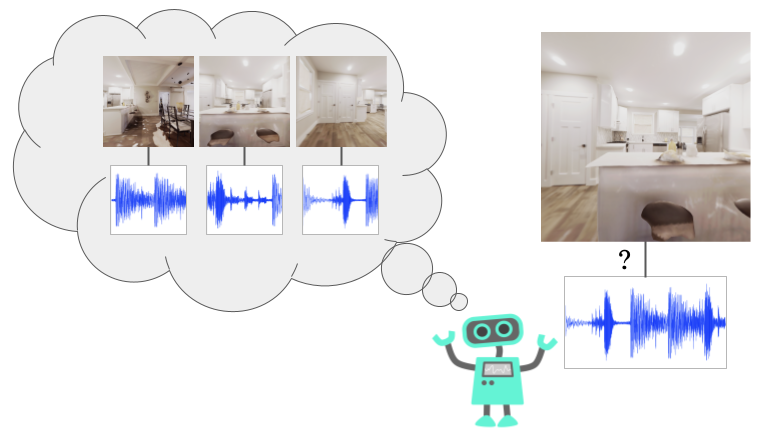
See, Hear, Explore: We propose a formulation of curiosity that encourages the agent to explore novel associations between modalities, such as audio and vision. In Habitat, the photorealistic navigation simulator shown above, our method allows for more efficient exploration than baselines.
Many successes in reinforcement learning (RL) have come from agents maximizing a provided extrinsic reward such as a game score. However, in real-world settings such as robotics or autonomous driving, reward functions are hard to formulate and require significant human engineering. On the other hand, humans explore the world driven by intrinsic motivation, such as curiosity, often in the absence of rewards. But what is curiosity and how would one formulate it?
Recent work in RL (Pathak et al. 2017, Burda et al. 2018, Pathak et al. 2019) has focused on curiosity using future prediction. In this formulation, an exploration policy receives rewards for actions that lead to differences between the real future and the future predicted by a forward dynamics model. In turn, the dynamics model improves as it learns from novel states. While the core idea behind this curiosity formulation is simple, putting it into practice is quite challenging. Learning and modeling forward dynamics is still an open research problem; it is unclear how to handle multiple possible futures, whether to explicitly incorporate physics, or even what the right prediction space is (pixel space or some latent space).
Curiosity in humans is inherently multimodal, and there is a long history of studying the use of multiple modalities in human learning. Research in psychology has suggested that humans look for incongruity (Hunt 1965). A baby might hit an object to hear what it sounds like. Have you ever found yourself curious to touch a material different from anything you have seen before? Humans are drawn towards discovering and exploring novel associations between different modalities. Dember and Earl argued that intrinsic motivation arises with discrepancy between expected sensory perception and the actual stimulus. More recent work has shown the presence of multimodal stimulation and exploration in infants (Wilcox et al. 2007, Flom et al. 2007). In cognitive development, both sight and sound guide exploration: babies are drawn towards colorful toys that squeak and rattle (Morrongiello et al. 1998).
Inspired by human exploration, we introduce See Hear Explore (SHE): a curiosity for novel associations between sensory modalities. SHE rewards actions that generate novel associations (shared information) between different sensory modalities (in our case, pixels and sounds). We first demonstrate that our formulation is useful in several Atari games: SHE allows for more exploration, is more sample-efficient, and is more robust to noise compared to existing curiosity baselines on these environments. Finally, we show experiments on area exploration in the realistic Habitat simulator. Our results demonstrate that in this setting our approach significantly outperforms baselines.
To summarize, our contributions in this work include: 1) SHE, a curiosity formulation that searches for novel associations in the world. To the best of our knowledge, multimodal associations have not been investigated in self-supervised exploration; 2) we show our approach outperforms the commonly-used curiosity approaches on standard Atari benchmark tasks; 3) most importantly, multimodality is one of the most basic facets of our rich physical world – audio and vision are generated by the same physical processes (Watanabe et al. 2001). We show experiments on realistic area exploration in which SHE significantly outperforms baselines. This work builds on efficient exploration, which will be crucial as we push agents to explore more complex unknown environments.
See, Hear, Explore
We now describe SHE, our exploration method based on associating audio and visual information. Our goal is to develop a form of curiosity that exploits the multimodal nature of the input data. Our core idea is that the SHE agent learns a model that captures associations between two modalities. We use this model to reward actions that lead to unseen associations between the modalities. By rewarding such actions, we guide the exploration policy towards discovering new combinations of sight and sound.
More formally, we consider an agent interacting with an environment that contains visual and sound features, which we call  for time
for time  where
where  is the visual feature vector and
is the visual feature vector and  is the sound feature vector. The agent explores using a policy
is the sound feature vector. The agent explores using a policy  where
where  corresponds to an action taken by the agent at time . To make for easier comparison to visual-only baselines, our agent is only given access to the visual features and not the audio features . To enable this agent to explore, we train a discriminator D that tries to determine whether an observed multimodal pair
corresponds to an action taken by the agent at time . To make for easier comparison to visual-only baselines, our agent is only given access to the visual features and not the audio features . To enable this agent to explore, we train a discriminator D that tries to determine whether an observed multimodal pair  is novel, and we reward the agent in states where the discriminator is surprised by the observed multimodal association.
is novel, and we reward the agent in states where the discriminator is surprised by the observed multimodal association.
Why Novel Associations?
The goal of an exploration policy is to perform actions that uncover states that lead to a better understanding of the world. One commonly used exploration strategy involves rewarding actions that lead to unseen or novel states (Bellemare et al. 2016). While this strategy seems intuitive, it does not handle the fact that while some states might not have been seen, we still understand them and hence they do not need to be explored. In light of this, recent approaches have used a prediction-based formulation. If a model cannot predict the future, it needs more data points to learn. However, sometimes we may have seen enough examples, and prediction is still challenging, leading a prediction-based exploration policy to get stuck. For example, consider the couch-potato issue: the random TV in the Unity environment (as described in Burda et al. 2018 and shown in the video below) yields high error for prediction models, so prediction-based curious agents receive high rewards for staring at the TV, though this is not a desirable type of exploration.
Trying to avoid these problems has shaped much of the work on intrinsic motivation; Schmidhuber 1991, Oudeyer et al. 2007, White et al. 2014, and Burda et al. 2019 all formulate intrinsic rewards with the goal of mitigating problems like the couch-potato agent. Our approach, different from this body of prior work, looks at how multimodal data can mitigate these issues.
Our underlying hypothesis is that discovering new sight and sound associations will help mitigate the shortcomings of the previously described count-based and prediction-based exploration strategies. By using an association model, we ask a simpler question: can this image co-occur with this sound? Consider another example, in which pressing a button randomly produces one among 3 distinct sounds. Our approach could learn to classify all as associated, while an agent using future prediction error would always be curious. This focus on association effectively helps ignore stochasticity, mitigating the couch-potato problem by focusing on non-random structure. Such a model can allow generalization to unseen states, and it also does not need to predict the future to provide an informative signal for exploration.
Association Novelty via Alignment
The core of our method is the ability to determine whether a given pair represents a novel association. To tackle this problem, we learn a model in an online manner. Given past trajectories, a model learns whether a certain audio-visual input comes from a seen or new phenomenon. One way to model this would be to use a generative model such as a VAE (Kingma et al. 2013) or GAN (Goodfellow et al. 2014), which could determine if the image-audio combination is within the distribution or out of distribution. However, generative models are also difficult to train, so we instead propose using a discriminator to predict if the image-audio pair is novel, which has a much smaller, binary output space.
We train this discriminator to distinguish real audio-visual pairs from ‘fake’ pairs from another distribution, with the insight that the learned model is more likely to classify novel pairs as fake. Here, the observed image-audio pairs during exploration act as positive training examples, but a critical question is how to obtain negative image-audio pairs. To this end, we reformulate the problem as whether image-audio pairs are aligned or not: we obtain ‘fake’ samples by randomly misaligning the audio and visual modalities, similar to Owens et al 2018. The positive data is then aligned image-audio pairs, and the negative data is comprised of misaligned ones. The discriminator model, shown below, outputs values between 0 and 1, with 1 representing high probability of audio-visual alignment and 0 representing misalignment. We can then leverage the misalignment likelihood as an indicator of novelty since the discriminator would be uncertain in such instances.
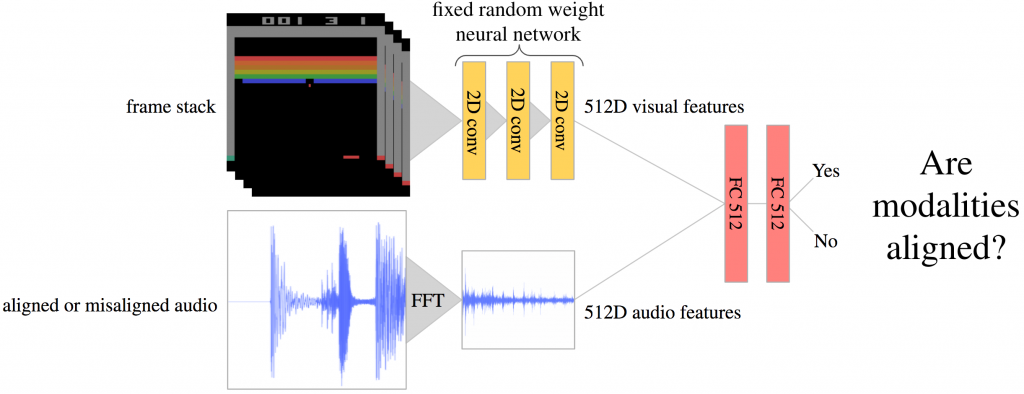
Training
Having introduced association novelty via alignment, we now describe how we implement this idea using function approximators. During training, the agent policy is rolled out in parallel environments. These yield trajectories which are each chunked into 128 time steps. A trajectory consists of pairs of preprocessed visual and sound features:  . These trajectories are used for two purposes: 1) updating the discriminator D as described below and 2) updating the exploration policy based on the intrinsic reward
. These trajectories are used for two purposes: 1) updating the discriminator D as described below and 2) updating the exploration policy based on the intrinsic reward  (computed using the discriminator), also described below.
(computed using the discriminator), also described below.
Training the Alignment Discriminator: The discriminator D is a neural network that takes a visual and sound feature pair as input and outputs an alignment probability. To train D, we start with positive examples from the visual and sound feature pairs . With 0.5 probability we use the true aligned pair, and with 0.5 probability we create a false pair consisting of the true visual feature vector and a sound feature vector uniformly sampled from the current trajectory. We call this false sound  . We define a binary variable
. We define a binary variable  to indicate whether the true audio was used, i.e. when we give the discriminator the true audio , we set
to indicate whether the true audio was used, i.e. when we give the discriminator the true audio , we set  , and when we give the discriminator the false audio ,
, and when we give the discriminator the false audio ,  . We use a cross-entropy loss to train the discriminator, similar to prior work (Owens et al. 2018, Aytar et al. 2018):
. We use a cross-entropy loss to train the discriminator, similar to prior work (Owens et al. 2018, Aytar et al. 2018):
![\[\mathcal{L}_t(v_t,s_t,s_t',z_t) = \begin{cases} -\log(D(v_t,s_t)), & \text{if } z_t = 1\\ -\frac{||s_t - s_t'||_2}{\mathbb{E}_{\text{batch}}||s_t - s_t'||_2}\log(1-D(v_t,s_t')), & \text{if } z_t = 0 \end{cases}\]](https://aihub.org/wp-content/ql-cache/quicklatex.com-e0ecd884f37331eefa544e1d130953e1_l3.png "Rendered by QuickLaTeX.com")
In the case above, we weight the cross-entropy loss to prevent the discriminator from being penalized in cases where the true and false audio are similar. We weight by the L2 difference between the true and false audio feature vectors and normalize by dividing by the mean difference across samples in the batch of 128 trajectories. This loss is used for updating the discriminator and is not used in computing the agent’s intrinsic reward.
Training the Agent via Intrinsic Reward: We want to reward actions that lead to unseen image-audio pairs. For a given image-audio pair, if the discriminator predicts 0 (unseen or unaligned), we want to reward the agent. On the other hand, if the discriminator correctly outputs 1 on a true pair, the agent receives no reward. Mathematically, the agent’s intrinsic reward is the negative log-likelihood of the discriminator evaluated on the true pairs:  , where the output of D is between 0 and 1. Audio-visual pairs that the discriminator knows to be aligned get a reward of 0, but if the discriminator is uncertain (the association surprised the discriminator) the agent receives a positive reward. The agent takes an action and receives a new observation and intrinsic reward (note that the agent does not have access to the sound ). The agent is trained using PPO (Schulman et al. 2017) to maximize the expected reward:
, where the output of D is between 0 and 1. Audio-visual pairs that the discriminator knows to be aligned get a reward of 0, but if the discriminator is uncertain (the association surprised the discriminator) the agent receives a positive reward. The agent takes an action and receives a new observation and intrinsic reward (note that the agent does not have access to the sound ). The agent is trained using PPO (Schulman et al. 2017) to maximize the expected reward: ![\max_{\theta}\mathbb{E}_{\pi(v_t;\theta)}\left[\sum_t \gamma^t r_t^i\right]](https://aihub.org/wp-content/ql-cache/quicklatex.com-f1e77601890076cc0e9a4524e3008035_l3.png "Rendered by QuickLaTeX.com") . The agent does not have access to the extrinsic reward. Extrinsic reward is used only for evaluation. This will enable the use of our method on future tasks for which we cannot easily obtain a reward function. See Burda et al. 2018 for further discussion on training with no extrinsic reward while using it for evaluation.
. The agent does not have access to the extrinsic reward. Extrinsic reward is used only for evaluation. This will enable the use of our method on future tasks for which we cannot easily obtain a reward function. See Burda et al. 2018 for further discussion on training with no extrinsic reward while using it for evaluation.
Experiments
We test our method in two exploration settings (Atari and Habitat) and compare it with commonly-used curiosity formulations: future prediction curiosity (Burda et al. 2018), exploration via disagreement (Pathak et al. 2019), and Random Network Distillation (RND) (Burda et al. 2019).
Atari Environment Setup
Similar to prior work, we demonstrate the effectiveness of our approach on 12 Atari games. We chose a subset of the Atari games to represent environments used in prior work and a range of difficulty levels. We excluded some games due to lack of audio (e.g. Amidar, Pong) or the presence of background music (e.g. RoadRunner, Super Mario Bros). To compute audio features, we take an audio clip spanning 4 time steps ( th of a second for these 60 frame per second environments) and apply a Fast Fourier Transform (FFT). The FFT output is downsampled using max pooling to a 512-dimensional feature vector, which is used as input to the discriminator along with a 512-dimensional visual feature vector.
th of a second for these 60 frame per second environments) and apply a Fast Fourier Transform (FFT). The FFT output is downsampled using max pooling to a 512-dimensional feature vector, which is used as input to the discriminator along with a 512-dimensional visual feature vector.
Atari Experimental Results
We trained our approach and baselines for 200 million frames using the intrinsic reward and measure performance by the extrinsic reward throughout learning. The figure below shows these results. Each method was run with three random seeds, and the plots show the mean and standard error for each method. Across many environments, our method enables better exploration (as judged by the extrinsic reward) and is more sample efficient than the baselines. Of the 12 environments, SHE outperforms the disagreement baseline in 9 and the future prediction baseline in 8. We hypothesize that states leading to novel audio-visual associations, such as a new sound when killing an enemy, are more indicative of a significant event than ones inducing high prediction error (which can happen due to inaccurate modeling or stochasticity) and this is why our approach is more efficient across these environments.
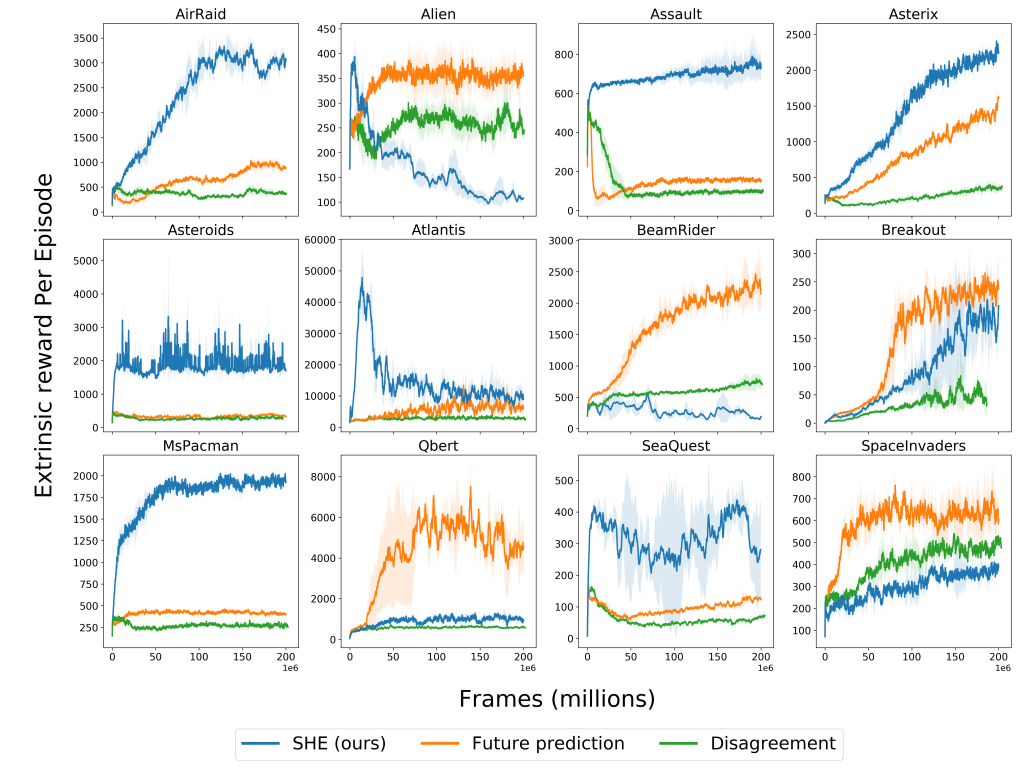
Understanding Failure Cases: While our approach generally exceeds the performance of or is comparable to the curiosity baselines, there are some environments where SHE underperforms. We have analyzed these games and found common failure cases:
- Audio-visual association is trivial. For example in Qbert, the discriminator easily learns the associations: every time the Qbert agent jumps to any cube the same sound is made, thus making the discriminator’s job easy, leading to a low agent reward. Visiting states with already learned audio-visual pairs is necessary for achieving a high score, even though they may not be crucial for exploration. The game Atlantis had similarly high discriminator performance and low agent rewards.
- The game has repetitive background sounds. Games like SpaceInvaders and BeamRider have background sounds at a fixed time interval, but it is hard to visually associate these sounds. Here the discriminator has trouble learning basic cases, so the agent is unmotivated to further explore.
- In Alien, the agent quickly learns that by quickly passing from one side of the screen to the other, a sound occurs with a slight delay that makes it hard to align with the frame. The agent learns to repeat this trick continuously, putting the discriminator in a situation similar to 2.
Below are qualitative results showing the SHE agent and the future prediction agent during training in two of the Atari environments. These videos contain game audio, demonstrating the kinds of audio-visual associations motivating the SHE agent to explore.
Habitat Environment Setup
We also test our method in a navigation setting using Habitat. In this environment, the agent moves around a photorealistic Replica scene. We use the largest Replica scene, Apartment 0, which has 211 discrete locations. In each location, the agent can face in 4 directions. At each timestep, the agent takes one of 3 discrete actions: turn left, turn right, or move forward. As in our Atari experiments, the agent is not given any extrinsic reward; we simply want to see how well it can explore the area without supervision.
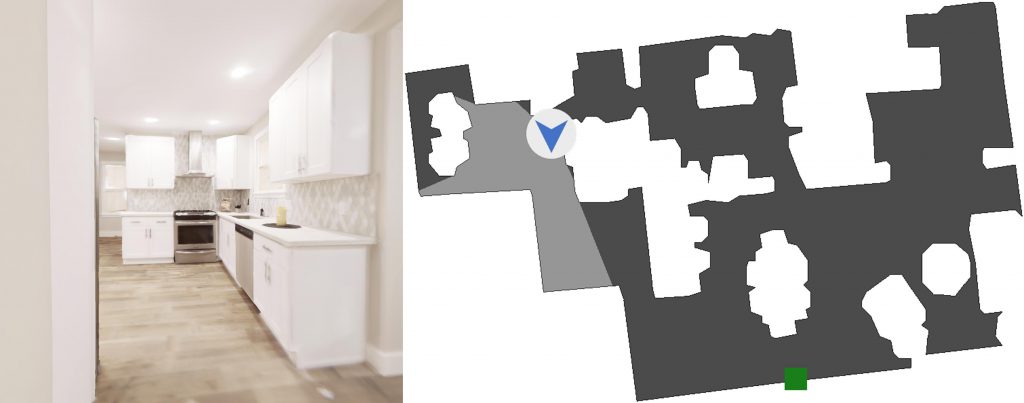
To generate audio in Habitat, we use the audio-visual navigation extension from SoundSpaces, which emits a fixed audio clip from a fixed location and allows our agent to hear the sound after simulating room acoustics. A demo of this extension is shown in the video below. The perceived sound at each time step is less than 1 second long, and we zero pad this audio to 1 second to make each sound equal length for feature computation. We apply FFT and downsample to a 512-dimensional feature vector, the same as done in Atari, described above.
Habitat Experimental Results
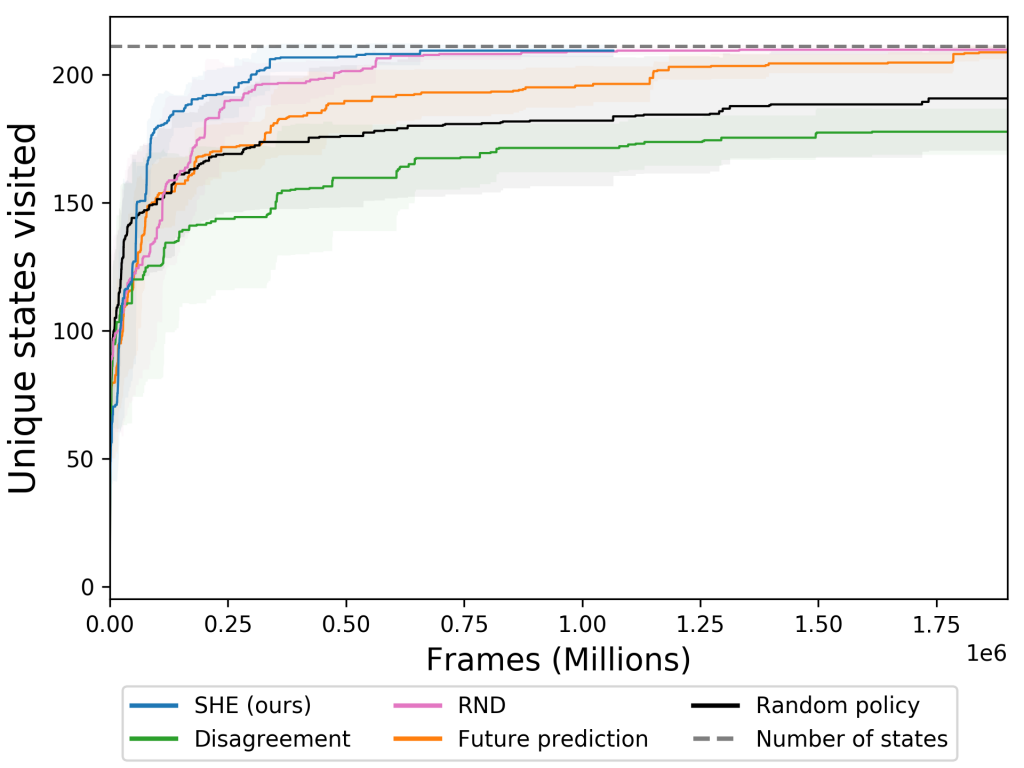
We present qualitative results from unsupervised area exploration in Habitat. There is no goal location; as a proxy for exploration success, we examine state coverage. Each method is run with three different seeds and each seed uses a different start location. On the right, we see that SHE (blue) has similar coverage to RND and reaches full state coverage 3 times faster than future prediction curiosity.
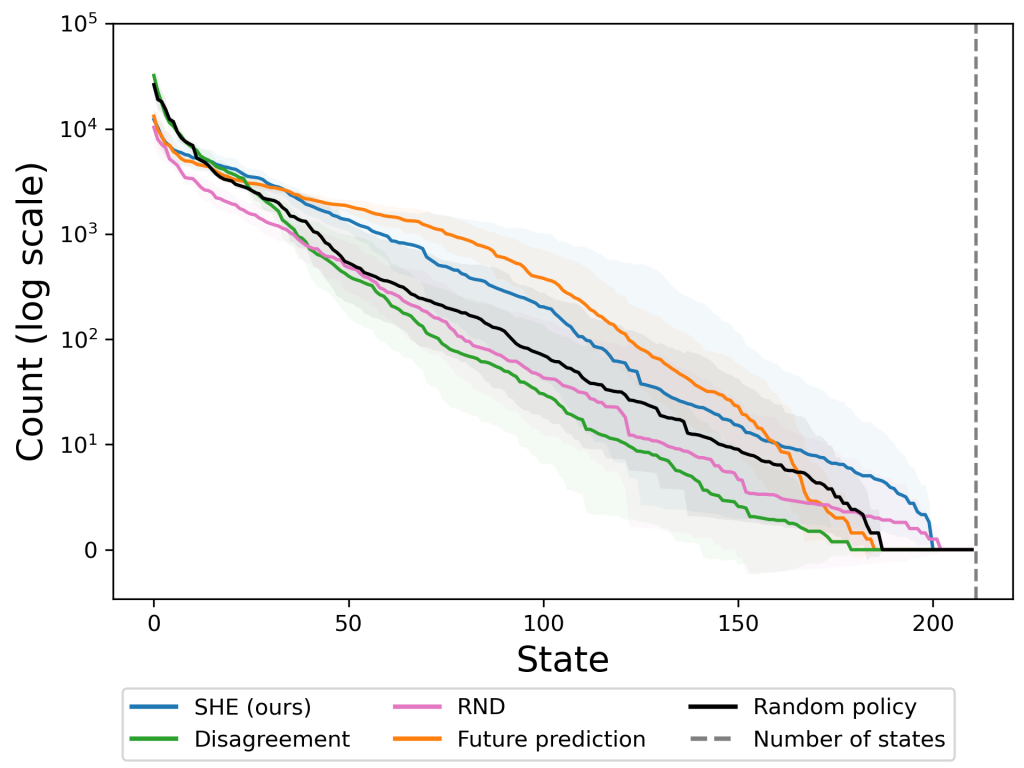
We can also look at how much each state is visited, shown in the plot below. A good exploration method will have a more even distribution over states, with higher counts in the rare states. Our method has a wider tail, visiting rare states about 8 times more frequently than the next-best baseline. It does so by visiting common states less frequently. SHE’s strong performance on this more realistic audio-visual task holds promise for future work exploring the real world.
Conclusion
Multimodality is one of the most basic facets of our rich physical world. Our formulation of curiosity enables an autonomous agent to efficiently explore a new environment by exploiting relationships between sensory modalities. With results on Atari games, we demonstrated the benefit of using audio-visual association to compute the intrinsic reward. Our method showed improved exploration over baselines in several environments. The most promise lies in our approach’s significant gains when used on a more realistic task, exploration in the Habitat environment, where audio and visual are governed by the same physical processes. We anticipate multimodal agents exploring in the real world and discovering even more interesting associations. Instead of building robots that perform like adults, we should build robots that can learn the way babies do. These robots will be able to explore autonomously in real-world, unstructured environments.
Please see our website for the paper, code, and video.
This article was initially published on the ML@CMU blog and appears here with the authors’ permission.

AUAI is supported by:








