
ΑΙhub.org
Will AI write the scientific papers of the future? – Yolanda Gil’s presidential address at #AAAI20

The Presidential Address at the AAAI conferences is always a much-anticipated event with the new President giving their take on an aspect of the field of artificial intelligence. This year it was the turn of Yolanda Gil and she opened with a question that she had been pondering for some time: will AI write the scientific papers of the future?
You can watch the talk in full in the live-streamed video provided by AAAI:
To begin the talk Gil provided a bit of a personal perspective on AI and the community, which she believes to be visionary, broad, inclusive, interdisciplinary and determined. There was an interesting history of some of the main achievements and milestones in the field that have stood out to Gil during her career. Here are just some of them:
1980s
- SOAR: An architecture for general intelligence
- Learning representations by back-propagating errors
- Elephants don’t play chess
- Theo: a framework for self-improving systems
1990s
- Integrating Planning and Learning: The PRODIGY Architecture
- Sphinx shows speaker-independent large vocabulary continuous speech recognition
- SKICAT identifies five new quasars
- Navlab is the first trained car to drive autonomously on highways across the USA
- Deep Blue defeats world chess champion
2000s
- Gene Ontology is shown to describe over 15,000 gene products
- Kismet demonstrates and recognises emotion
- First robot football team against human players at Robocup
- Pragmatic Chaos ensemble learning wins $1 prize in competition to predict film ratings
2010s
- Watson takes first place in Jeopardy question and answer game defeating two human champions
- AlexNet outperforms rivals by 11% in ImageNet challenge in 2012
- Knowledge Graph is used as the backbone in one third of 100 billion monthly internet searches
- Wikidata surpasses Wikipedia as the most edited Wikimedia site
The next part of the talk focussed on some of the research that Yolanda Gil and her collaborators have carried out. The team have worked, and are working, on many projects that focus on capturing and representing scientific knowledge in AI systems. The projects outlined in the talk were:
Crowdsourcing vocabulary
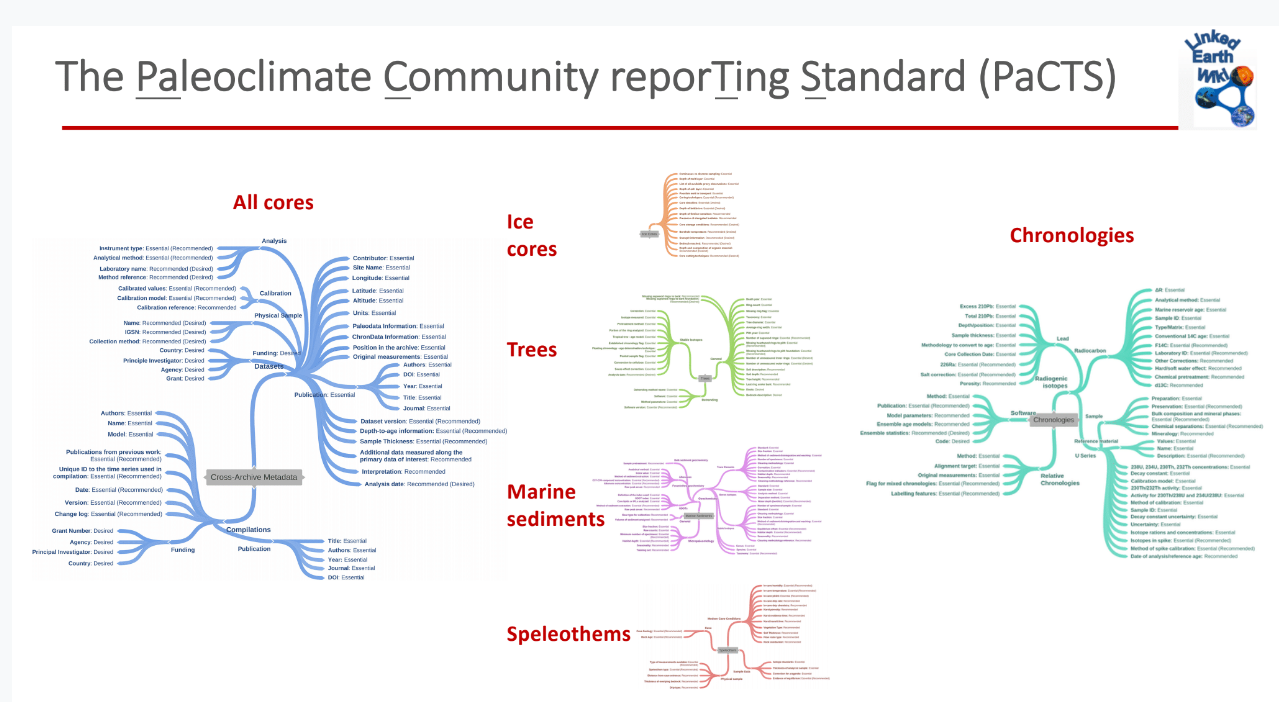
In many fields it takes a lot of effort for the practitioners to come up with a standard scientific vocabulary to describe scientific objects. Gil and collaborators looked into this problem and their project culminated in development of a controlled crowdsourcing approach for practical ontology extensions and metadata annotations. Their approach enables users to add new metadata properties on the fly as they describe their datasets, creating terms that can be immediately adopted by others and eventually become standardized. Further work, and a large collaboration, led to PaCTS: the paleoclimate community reporting standard.
Data analysis processes
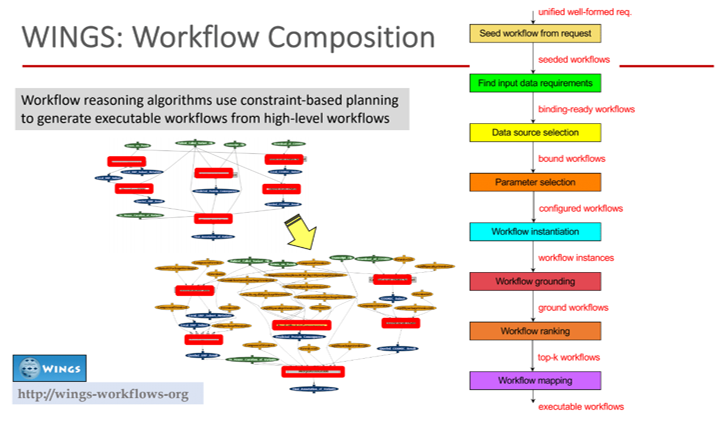
The next topic covered was data analysis processes. Here, the team use workflows to represent these processes, capturing computational steps and data that are ingested and result from those steps. This is a very powerful structure that captures how a lot of methods in science are repeated and re-used very often. The workflows are treated as objects of science that have a meaning, and the team attach semantics and constraints to the items in them. Using AI the team are able to carry out powerful composition and exploration of these workflows. In fact they were able to reproduce papers (where the data was available) and get the same significant results just by reusing the methods.
Provenance
Once the plans described above have been executed, they leave a trail of the provenance of any results they generate. Gil and her collaborators introduced W3C PROV in 2013. This is a generic way of looking at provenance which has become widely adopted.
Open reproducible publications
To close this section of the talk Gil encouraged researchers to write better papers. Well-written articles are not only better for readers but they are also far easier for text-extraction systems to work with. She mentioned the initiative Scientific Paper of the Future where geoscientists are encouraged to publish papers together with the associated digital products of their research. This includes documentation of datasets, software, provenance and workflow for each figure and result.
Following this whistle-stop tour through some of the ways scientific knowledge can be captured, the next part of the talk focussed on two ways in which this knowledge is used:
Systematic scientific data analysis
Gil is leading the DISK project, where the aim is to automate discovery based on hypothesis. The team have put a framework in place that allows them to test and revise hypotheses based on automatic analysis of scientific data repositories that grow over time. Given an input hypothesis, DISK is able to search for appropriate data to test it and then revise the hypothesis accordingly. The provenance of the revised hypotheses is recorded along with all the details of the analyses.
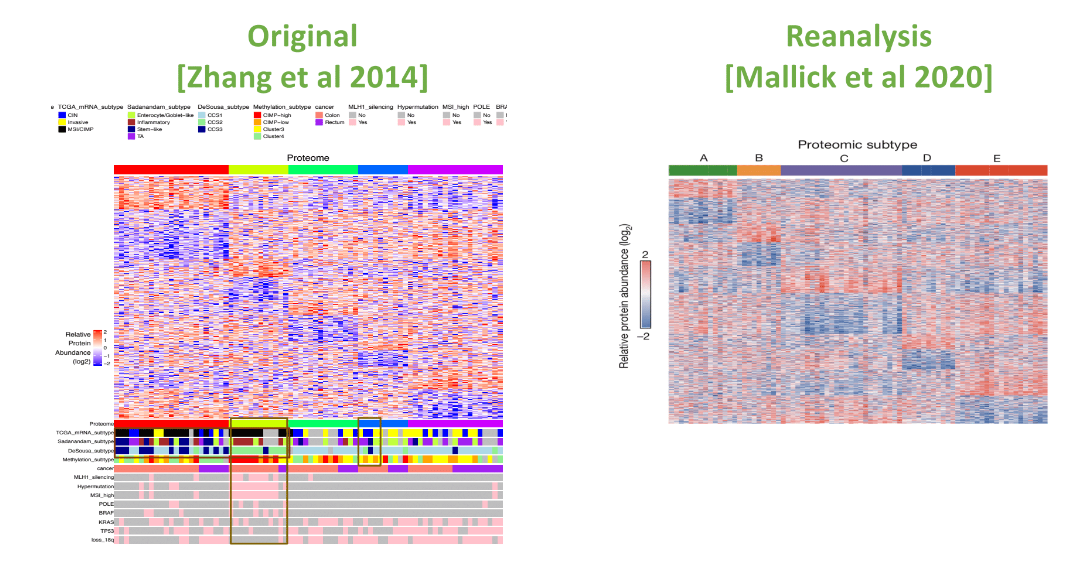
Using the methodologies described, Gil and her collaborators set about reproducing a seminal paper published in 2014: “Proteogenomic characterization of human colon and rectal cancer”. This was a huge collaborative effort that took several years and the team were able to reproduce the results. However, when they started recreating the figures one-by-one they found quite a large difference between the original and the reproduced results. For example, in one peptide detection there was a 10% difference. In reproducing the results the team tried a number of different algorithms and found that there were significant differences in the way these performed – some algorithms missed certain proteins for example. The results also varied depending on which reference database was used. This all showed that AI could play a big role in making scientific research more systematic and comprehensive.
AI for interdisciplinary science frontiers
Gil described another project she is working on, MINT – Model INTegration. There are a large number of collaborators involved and the team is working with data from Ethiopia, Texas and California to study how changes in climate affect water availability, agriculture, food production and cause flooding and drought. Studying these problems involves bringing together many different kinds of models and it can takes months and years to assemble these different models to study a certain region. The MINT team are trying to reduce this time to days by using AI techniques to create a system that can act as a mediator for all of these models. You can find out more about MINT here.
So, will AI write the scientific papers of the future?
To end her talk, Gil returned to the question she posed at the beginning. She certainly described a number of projects that may help things to move in that direction. Based on the current trajectory of progress Gil can see a future whereby AI is reproducing articles by 2030, acting as a research assistants by 2035, and being a co-author by 2040.
When it comes to research and writing papers AI could help address some common traits in humans, such as biases, poor-reporting and errors. However, it is often these traits that lead to discoveries – for example, the penicillin discovery resulting from human error. Gil noted that remarkable things can be achieved when humans and machines work together. As to whether AI will eventually write the scientific papers of the future, Gil said: “I don’t know the answer to this question but I’m excited to find out, together with all of you”.
To access the slides for the talk:
Slides from my AAAI 2020 Presidential Address are available here: https://t.co/9jDtHEuOGa #AAAI2020 @RealAAAI https://t.co/Uzq0o8YRWt
— Yolanda Gil (@yolandagil) February 9, 2020
tags: AAAI, AAAI2020

AUAI is supported by:








