
ΑΙhub.org
A unifying, game-theoretic framework for imitation learning
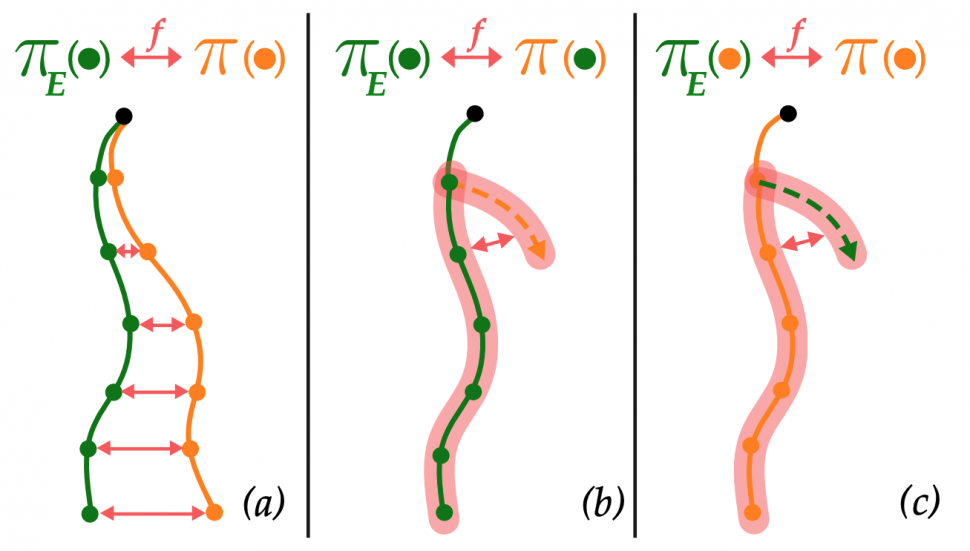
Imitation learning (IL) is the problem of finding a policy,  , that is as close as possible to an expert’s policy,
, that is as close as possible to an expert’s policy,  . IL algorithms can be grouped broadly into (a) online, (b) offline, and (c) interactive methods. We provide, for each setting, performance bounds for learned policies that apply for all algorithms, provably efficient algorithmic templates for achieving said bounds, and practical realizations that out-perform recent work.
. IL algorithms can be grouped broadly into (a) online, (b) offline, and (c) interactive methods. We provide, for each setting, performance bounds for learned policies that apply for all algorithms, provably efficient algorithmic templates for achieving said bounds, and practical realizations that out-perform recent work.
By Gokul Swamy
From beating the world champion at Go (Silver et al.) to getting cars to drive themselves (Bojarski et al.), we’ve seen unprecedented successes in learning to make sequential decisions over the last few years. When viewed from an algorithmic viewpoint, many of these accomplishments share a common paradigm: imitation learning (IL). In imitation learning, one is given access to samples of expert behavior (e.g. moves chosen by Monte-Carlo Tree Search or steering angles recorded from an expert driver) and tries to learn a policy that mimics this behavior. Unlike reinforcement learning, imitation learning does not require careful tuning of a reward function, making it easier to scale to real-world tasks where one is able to gather expert behavior (like Go or driving). As we continue to apply imitation learning algorithms to safety-critical problems, it becomes increasingly important for us to have strong guarantees on their performance: while wrong steps in Go lead to a lost game at worst, mistakes of self-driving cars could result in far worse. In our ICML’21 Paper Of Moments and Matching: A Game Theoretic Framework for Closing the Imitation Gap, we provide bounds on how well any imitation algorithm can do, as well as provably efficient algorithms for achieving these bounds.
A taxonomy of imitation learning algorithms
Let’s focus on the problem of trying to teach a car to drive around a track from expert demonstrations. We instrument the car with cameras and sensors that measure the angle of the wheel and how hard the pedals are being pushed. Then, in terms of increasing requirements, the approaches we could take are:
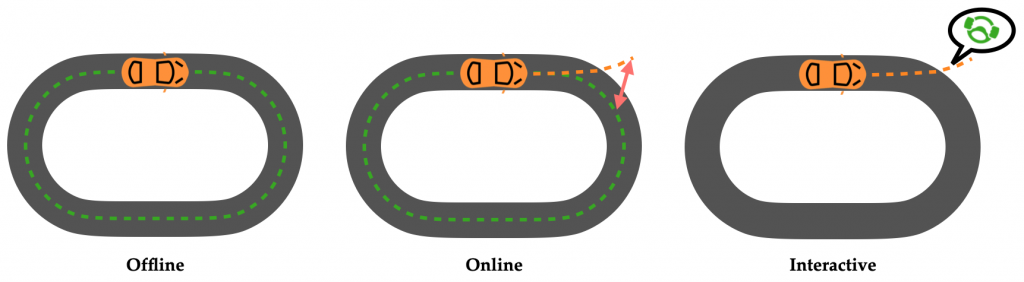
- Offline: Have the expert drive laps, recording their states (camera images) and actions (pedals/wheel). Use your favorite supervised learning algorithm to regress from states to actions. This approach is called Behavioral Cloning.
- Online: Record expert states and actions. Then, have the car try to drive around the track and measure the delta between learner and expert trajectories. Train the policy to minimize this delta. GAIL is an algorithm that uses a discriminator network to measure this delta.
- Interactive: (0) Start with an empty dataset D. (1) Record the car driving a sample lap. (2) Ask the expert driver what they would have done for each recorded image. Append this data to D. (3) Regress over data in D. (4) Go back to 1. This approach is known as DAgger.
One of our key insights is that all three of these approaches can be seen as minimizing a sort of divergence from expert behavior. Concretely,
- Offline: We measure a divergence between learner and expert actions on states from expert demonstrations.
- Online: We measure a divergence between learner and expert trajectories.
- Interactive: We measure a divergence between learner and expert actions but on states from learner rollouts.
Also notice that as we transition from Offline to Online IL, we add a requirement of access to the environment or an accurate simulator. As we move from Online to Interactive IL, we also need access to a queryable expert. Let denote the policy, denote the expert’s policy, and  denote the divergence. We can visualize our thoughts thus far as:
denote the divergence. We can visualize our thoughts thus far as:
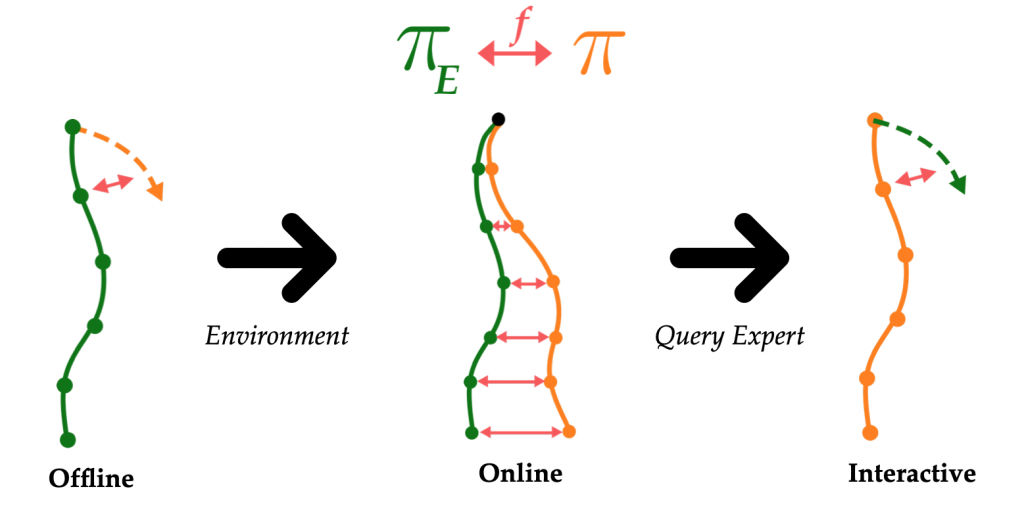
With this divergence-minimizing perspective in mind, we’re able to introduce a unifying, game-theoretic perspective.
A game-theoretic perspective on IL
A natural question at this point might be: what divergence should one use to measure the difference between learner and expert behavior? Examples abound in the literature: Kullback-Liebler? Wasserstein? Jensen-Shannon? Total Variation? Maximum Mean Discrepancy? Without prior knowledge about the problem, it’s really hard to say. For example, KL Divergence has a mode-covering effect — this means that if half the data was the expert swerving left to avoid a tree and half the data was them swerving right, the learner would learn to pick a point in the middle and drive straight into the tree!
If we’re not sure what divergence is the right choice, we can just minimize all of them, which is equivalent to minimizing a worst-case or adversarially-chosen one. Using and to denote the learner and expert policies, we can write out the optimization problem for each setting:
- Offline:
![\[\min_{\pi} \max_f \mathbb{E}_{s, a \sim \pi_E}[f(s, \pi(s)) - f(s, a)]\]](https://aihub.org/wp-content/ql-cache/quicklatex.com-968c671122f3ce6316db98ce31c86066_l3.png "Rendered by QuickLaTeX.com")
- Online:
![\[\min_{\pi} \max_f \mathbb{E}_{s, a \sim \pi}[f(s, a)] - \mathbb{E}_{s, a \sim \pi_E}[f(s, a)]\]](https://aihub.org/wp-content/ql-cache/quicklatex.com-2e26fc79be3d4eadf637e3fe2ff5ea0f_l3.png "Rendered by QuickLaTeX.com")
- Interactive:
![\[\min_{\pi} \max_f \mathbb{E}_{s, a \sim \pi}[f(s, a) - f(s, \pi_E(s))]\]](https://aihub.org/wp-content/ql-cache/quicklatex.com-6890792961116b3fbbb6960276a72b6f_l3.png "Rendered by QuickLaTeX.com")
Each of these equations is in the form of a two-player zero-sum game between a learner and a discriminator . Two-player zero-sum games have been extensively studied in game theory, allowing us to use standard tools to analyze and solve them. Notice the similarity of the forms of these games — the only real difference is which state-action distributions the divergence is calculated between. Thus, we can view all three classes of imitation learning as solving a games with different classes of discriminators. This game-theoretic perspective is extremely powerful for a few reasons:
- As we have access to more information (e.g. a simulator or a queryable expert), we’re able to evaluate more powerful discriminators. Minimizing these more powerful discriminators leads to tighter performance bounds. Specifically, we show that the difference between learner and expert performance for offline IL scales quadratically with the horizon of the problem, and linearly for online / interactive IL. Quadratically compounding errors translate to poor real-world performance. Thus, one perspective on our bounds is that they show that access to a simulator or a queryable expert is both necessary and sufficient for learning performant policies. We recommend checking out the full paper for the precise upper and lower bounds.
- These performance bounds apply for all algorithms in each class — after all, you can’t do better by considering a more restrictive class of divergences. This means our bounds apply for a lot of prior work (e.g. Behavioral Cloning, GAIL, DAgger, MaxEnt IRL, …). Importantly, these bounds also apply for all non-adversarial algorithms: they’re just optimizing over a singleton discriminator class.
- Our game-theoretic perspective also tells us that finding a policy that minimizes the worst-case divergence is equivalent to finding a Nash Equilibrium of the corresponding game, a problem we know how to solve provably efficiently for two-player zero-sum games. By solving a particular game, we inherit the performance bounds that come with the class of divergences considered.
Together, these three points tell us that a game-theoretic perspective allows us to unify imitation learning as well as efficiently find strong policies!
A practical prescription for each IL setting
Let’s dig into how we can compute Nash equilibria efficiently in theory and in practice for all three games. Intuitively, a Nash equilibrium is a strategy for each player such that no player wants to unilaterally deviate. This means that each player is playing a best-response to every other player. We can find such an equilibrium by competing two types of algorithms:
- No-Regret: slow, stable, choosing best option over history.
- Best-Response: fast, choosing best option to last iterate of other player.
Classic analysis shows that having one player follow a no-regret algorithm and the other player follow a best-response algorithm will, within a polynomial number of iterations, converge to an approximate Nash equilibrium of the game. The intuition of the proof is that if player 1 is steadily converging to a strategy that performs well even when player 2 choses their strategy adversarially, player 1 can’t have much of an incentive to deviate, meaning their strategy must be half of a Nash equilibrium.
We’d like to emphasize the generality of this approach to imitation learning: you can plug in any no-regret algorithm and both our policy performance and efficiency results still hold. There’s a plethora of algorithms that can be developed from this no-regret reduction perspective!
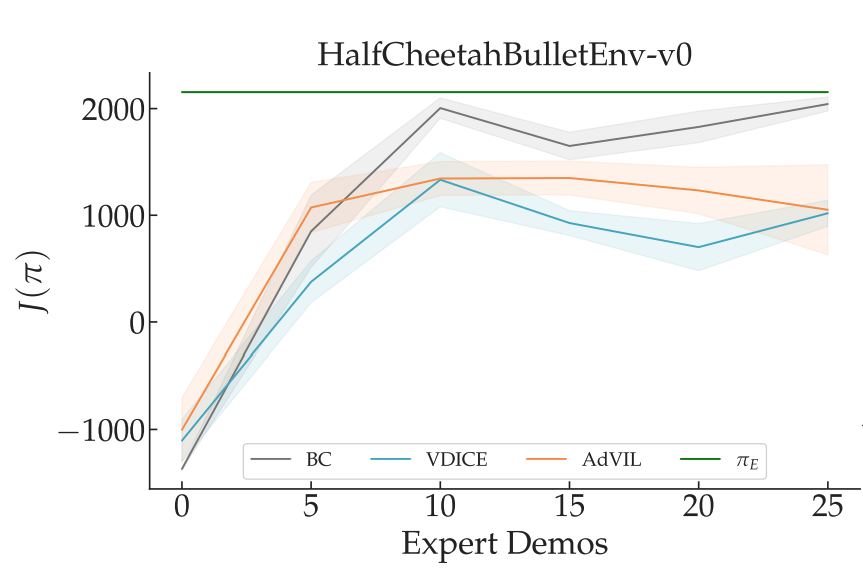
We instantiate this general template into an implementable procedure for each setting. We compare our approaches against similar recent work. We plot the performance of our methods in orange.  refers to learner’s expected cumulative reward while in green is the expert’s performance. As stated above, our goal is for the learner to match expert performance.
refers to learner’s expected cumulative reward while in green is the expert’s performance. As stated above, our goal is for the learner to match expert performance.
Offline: We adopt a model similar to a Wasserstein GAN where the learner acts as the generator and the discriminator tries to distinguish between learner and expert actions on expert states. We set the learner’s learning rate to be much lower than that of the discriminator, simulating no-regret on policy vs. best response on divergence. We term this approach Adversarial Value-moment IL, or AdVIL. We find it to be competitive with recent work:
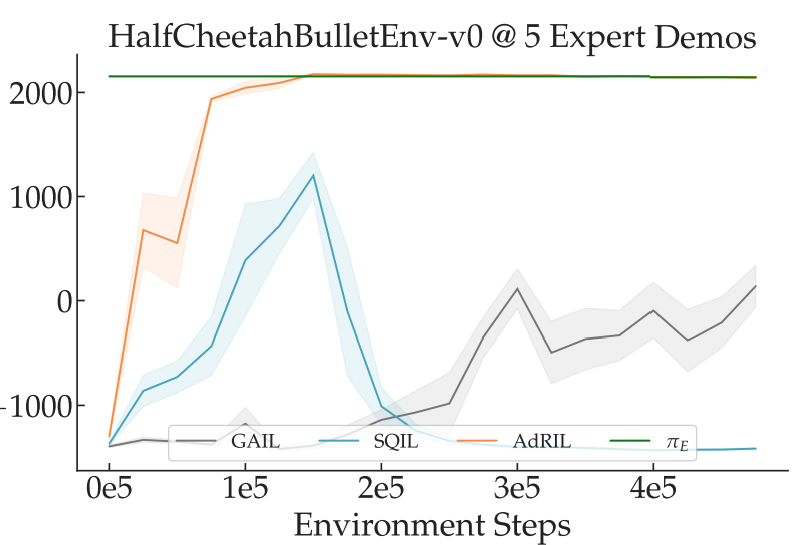
Online: We repurpose the replay buffer of an off-policy RL algorithm as the discriminator by assigning negative rewards to actions that don’t directly match the expert. We impute a reward of +1 for expert behavior and -1/k for learner behavior from a past round, where k is the round number. The slow-moving append-only replay buffer implements a no-regret algorithm against a policy that best-responds via RL at each round. We term this approach Adversarial Reward-moment IL, or AdRIL, and find that it can significantly outperform other online IL algorithms at some tasks:
Interactive: We modify DAgger to use adversarially chosen losses at each round instead of a fixed function. At each round, a discriminator network is trained between the last policy and the expert. Then, for all samples for that round, this discriminator network is used as the loss function. Then, just like DAgger, the learner minimizes loss over the history of samples and loss functions for all rounds. Thus, the learner is following a no-regret algorithm against a best-response by the discriminator. We call this algorithm DAgger-esque Qu-moment IL, or DAeQuIL.
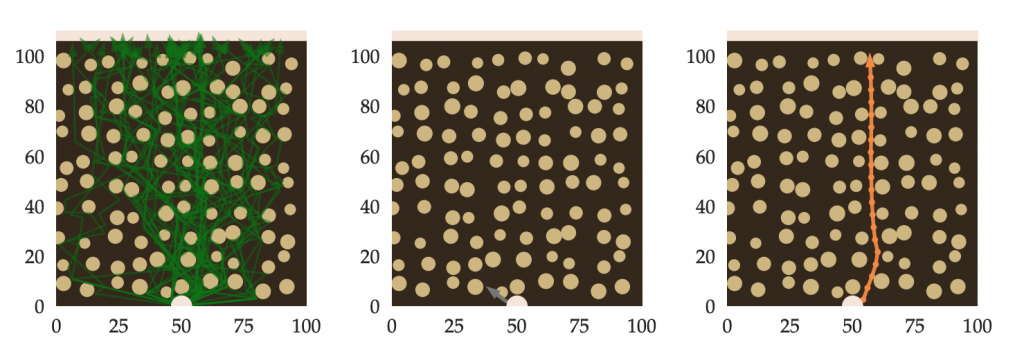
To demonstrate the potential advantages of DAeQuIL over DAgger, we test out both algorithms on a simulated UAV forest navigation task, where the expert demonstrates a wide variety of tree avoidance behaviors (left). DAgger attempts to match the mean of these interactively queried action labels, leading to it learning to crash directly into the first tree it sees (center). DAeQuIL, on the other hand, is able to learn to swerve out of the way of trees and navigate successfully through the forest (right).
Parting thoughts
We provide, for all three settings of imitation learning, performance bounds for learned policies, a provably efficient reduction to no-regret online learning, and practical algorithms. If you’re interested in learning more, I recommend you check out:
- Our paper.
- Our video explanations.
- Our code.
There are lots of interesting areas left to explore in imitation learning, including imitation from observation alone that would allow one to leverage the large corpus of instructional videos online to train robots. Another direction that we’re particularly excited about is mimicking expert behavior, even in the presence of unobserved confounders. Stay tuned!
DISCLAIMER: All opinions expressed in this post are those of the author and do not represent the views of CMU.
This article was initially published on the ML@CMU blog and appears here with the authors’ permission.
tags: deep dive

AUAI is supported by:








