
ΑΙhub.org
#IJCAI2021 invited talks round-up 2: system two deep learning, and knowledge representation for generalisation

In this post, we continue our summaries of the invited talks from the International Joint Conference on Artificial Intelligence (IJCAI-21). This time, we cover the presentations from Yoshua Bengio and Michael Thielscher.
Yoshua Bengio – System 2 deep learning: higher-level cognition, agency, out-of-distribution generalization and causality
Yoshua’s talk focussed on the development of what he calls system 2 deep learning. The aim is to incorporate agency, causality, and ideas from human intelligence to advance current deep learning methods, thus enabling better out-of-distribution generalisation.
As proposed by Daniel Kahneman, system 1 and system 2 are different types of thinking. System 1 thinking is intuitive, fast, unconscious and habitual. Current deep learning is very good at these things. System 2 processing allows us to do things that require consciousness, things that take more time to compute, such as planning and reasoning. This kind of thinking allows humans to deal with very novel situations.
Amazing progress has been made in AI, but the machines that have been built have a limited “understanding” of the data that they’ve been trained on. Yoshua, and many others, believe that the reason behind this is the fact that we have focussed on the problem of generalisation in distribution. In other words, we tend to train and test/apply a model on data from the same distribution. Humans on the other hand, excel at generalising in a more powerful way, beyond the training distribution. The goal is to develop a new kind of learning theory to incorporate this.
 Practical recommendations for monitoring out-of-distribution performance. Slide from Yoshua’s talk.
Practical recommendations for monitoring out-of-distribution performance. Slide from Yoshua’s talk.
Yoshua believes that the first step is for practitioners to accept that the problem exists, and to monitor out-of-distribution performance. Traditional methods involve shuffling the overall data, meaning that the training and test set are from the same distribution. In the real world things don’t work like that. For example, we might be training on past data, but applying to future scenarios, where the situation is likely to have changed. Yoshua’s practical recommendation is that we purposefully design test sets that reflect the kinds of changes in distribution that may happen in application scenarios.
In his talk, Yoshua considered what we could do to build better learning systems. He described ways in which we could learn from system 2 thinking and add elements of this to our deep learning models. One of these methods is based around the concept of attention, a technique that takes inspiration from cognitive attention, by enhancing important parts of the input data. In an architecture that Yoshua and his team have developed, a group of neural modules communicate with each other using an attention mechanism. Rather than every neuron in a network being attached to every other, the system is divided into modules. Within the modules the neurons are fully connected, but there is sparse connectivity between the different modules.
Yoshua also mentioned the interesting connections between reasoning and out-of-distribution generalisation. When we reason, we combine pieces of information, and it’s the ability to recombine things in novel ways, and predict the effect of an agent, that allows us to generalise. Yoshua described ways in which we could incorporate reasoning and causality into deep learning architecture.
In terms of current and future work, Yoshua and his team are working on merging two threads of research: causally-grounded learning and modular neural networks. The main task here is to develop a neural network that builds, on-the-fly, a causal explanation connecting selected items in its memory from a pool of mechanisms.
 Building reasoning and planning into neural network systems. Slide from Yoshua’s talk.
Building reasoning and planning into neural network systems. Slide from Yoshua’s talk.
If you are interested in finding out more, here are some of the papers that Yoshua mentioned in his talk:
Recurrent independent mechanisms, Anirudh Goyal, Alex Lamb, Jordan Hoffmann, Shagun Sodhani, Sergey Levine, Yoshua Bengio, Bernhard Schölkopf.
BabyAI: a platform to study the sample efficiency of grounded language learning, Maxime Chevalier-Boisvert, Dzmitry Bahdanau, Salem Lahlou, Lucas Willems, Chitwan Saharia, Thien Huu Nguyen, Yoshua Bengio.
A meta-transfer objective for learning to disentangle causal mechanisms, Yoshua Bengio, Tristan Deleu, Nasim Rahaman, Rosemary Ke, Sébastien Lachapelle, Olexa Bilaniuk, Anirudh Goyal, Christopher Pal.
Learning neural causal models from unknown interventions, Nan Rosemary Ke, Olexa Bilaniuk, Anirudh Goyal, Stefan Bauer, Hugo Larochelle, Bernhard Schölkopf, Michael C. Mozer, Chris Pal, Yoshua Bengio.
Michael Thielscher – Knowledge representation for systems with general intelligence
Michael’s research centres on combining knowledge representation with other AI methods to build systems able to generalise. For the majority of his talk, Michael focussed on two areas of his work: 1) general game playing programs, 2) general collaborative problem-solving robots.
General game playing programs
In recent years, we’ve witnessed the success of AI systems at playing a specific game, for example AlphaGo with Go, and Deep Blue with chess. However, these highly impressive systems are only good at the specific task that they have been given. The premise of a general game playing system is that it can understand descriptions of new games and learn to play these without human intervention. Essentially, the idea is to build a general problem solver. When constructing such a system two things need to be defined: 1) the problem class that we want to solve, 2) how to present a problem from that class to a general problem solving system.
Michael explained how knowledge representations are used to convey the rules of a particular game to the program. There are a number of different methods available, but he focussed on Game Description Language (GDL). Using chess as an example, he showed how we translate a natural language version of the rules of chess into a formal description. This method can be used to describe any game that is finite, n-player, has synchronous moves and has complete information.
 Representing the rules of Chess in code. Slide from Michael’s talk.
Representing the rules of Chess in code. Slide from Michael’s talk.
Once we have a representation of the rules, the next step is to build a system that understands this representation language and plays games to a high standard. Crucially, when we build this system, we are not restricted to the knowledge representation language that was used to define the rules – this system could combine any AI methods to learn to play games well. Michael and his team combine inference, search, and deep-learning. They put their knowledge representation, in the form of a propositional network, into a neural network, the purpose of which is to learn to extract features from a general game description. When given as input a particular state of the game, it gives as output an expected reward for each player as probability distribution over potential moves. Using this method Michael and his team have been able to create a system that can generalise to new games (of a similar ilk to chess and Go) when given the knowledge representation of the rules.
General collaborative problem-solving robots
Michael moved on to talk about actual real-world physical environments, and applying this general problem solving method to a robot. He and his team have built a robotic system which they are using to solve a variety of problems within what is called a blocks world environment, where blocks are picked up, moved and placed. The goal is to implement high-level planning activities, including parallel actions, and with execution constraints. They also want it to be able to handle human interference.
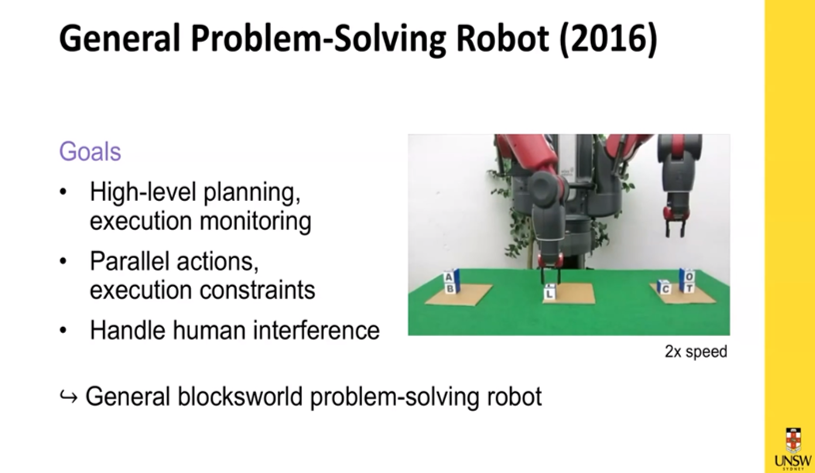 The general problem solving robot developed by Michael and his team. Slide from Michael’s talk.
The general problem solving robot developed by Michael and his team. Slide from Michael’s talk.
To build the system they used a hybrid robot control architecture, with separate left- and right-arm controls enhanced by a physics simulator. On top of this architecture they added knowledge representation for the high-level strategic planning. We saw a demonstration video of the robot building block towers of equal height whilst a human interfered with the system by moving some of the blocks.
The team are currently working on generalising the planning layer of their system to include epistemic planning to enable collaboration between agents.
To learn more, here are a couple of papers that Michael mentioned during his presentation:
Deep reinforcement learning For general game playing, Adrian Goldwaser and Michael Thielscher.
A framework for integrating symbolic and sub-symbolic representations, K. Clark, B. Hengst, M. Pagnucco, D. Rajaratnam, P. Robinson, C. Sammut, M. Thielscher.
tags: IJCAI2021

AUAI is supported by:








