
ΑΙhub.org
Understanding user interfaces with screen parsing

By Jason Wu
This blog post summarizes our paper Screen Parsing: Towards Reverse Engineering of UI Models from Screenshots, which was published in the proceedings of UIST 2021. [This blog post was cross-posted in the ACM UIST 2021 Blog on 10/22/2021.]
The Benefits of Machines that Understand User Interfaces
Machines that understand and operate user interfaces (UIs) on behalf of users could offer many benefits. For example, a screen reader (e.g., VoiceOver and TalkBack) could facilitate access to UIs for blind and visually impaired users, and task automation agents (e.g., Siri Shortcuts and IFTTT) could allow users to automate repetitive or complex tasks with their devices more efficiently. These benefits are gated on how well these systems can understand an underlying app’s UI by reasoning about 1) the functionality present, 2) how its different components work together, and 3) how it can be operated to accomplish some goal. Many rely on the availability of UI metadata (e.g., the view hierarchy and the accessibility hierarchy), which provide some information about what elements are present and their properties. However, this metadata is often unavailable due to poor toolkit support and low developer awareness. To maximize their support of apps and when they are helpful to users, these systems can benefit from understanding UIs solely from visual appearance.
Recent efforts have focused on predicting the presence of an app’s on-screen elements and semantic regions solely from its visual appearance. These have enabled many useful applications: such as allowing assistive technology to work with inaccessible apps and example-based search for UI designers. However, they constitute only a surface-level understanding of UIs, as they primarily focus on extracting what elements are on a screen and where they appear spatially. To further advance the UI understanding capabilities of machines and perform more valuable tasks, we focus on modeling the higher-level relationships by predicting UI structure.
Our work makes the following contributions:
- A problem defnition of screen parsing which is useful for a wide range of UI modeling applications
- A description of our implementation and its training procedure
- A comprehensive evaluation of our implementation with baseline comparison
- Three implemented examples of how our model can be used to facilitate downstream applications such as (i) UI similarity, (ii) accessibility metadata generation, and (iii) code generation.
Achieving Better Understanding of UIs through Hierarchy
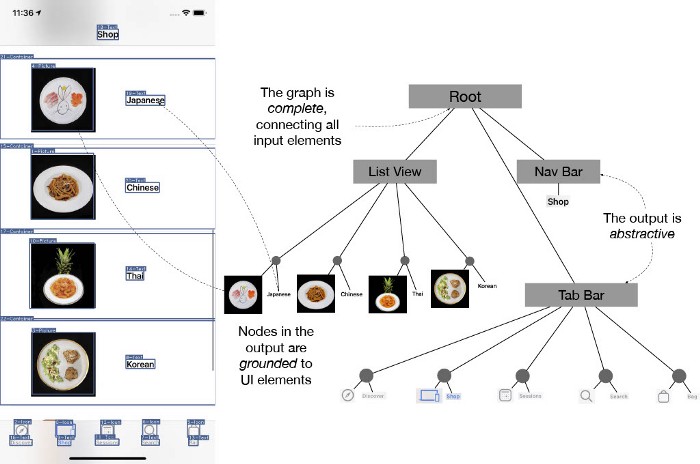
Structural representations enhance the understanding of many types of content by capturing higher-level semantics. For example, scene graphs enrich visual scenes by making sense of interactions between individual objects and parse trees disambiguate sentences by analyzing their grammar. Similarly, structure is a core property of UIs reflected in how they are constructed (i.e., stacking together views and widgets) and used. Modeling element relationships can help machines perceive UIs as humans do — not as a set of elements but as a coordinated presentation of content.
We introduce the problem of screen parsing, which we use to predict structured UI models (a high-level definition of a UI) from visual information. We focus on generating an app screen’s UI hierarchy, which specifies how UI elements are grouped and rendered on the screen. The following are properties of UI hierarchies:
- Complete — the output is a single directed tree that spans all of the UI elements on a screen
- Grounded — nodes in the output reference on-screen elements and regions
- Abstractive — the output can group elements (potentially more than once) to form higher-level structures.
Predicting UI Hierarchy from a Screenshot
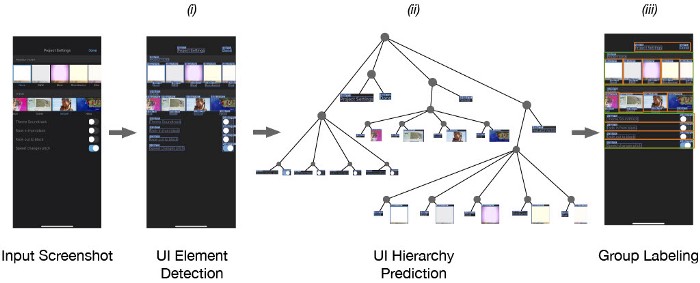
To predict UI hierarchy from a screenshot, we built a system to:
- detect the location and type of UI elements from a screenshot,
- predict a hierarchical structure that describes the relationships between them, and
- classify semantic groups.
The first step of our system processes a screenshot image using an object detection model (Faster-RCNN), which produces a list of UI element detections. The output is post-processed using standard techniques such as confidence-thresholding and non-max suppression. This list tells us what elements are on the screen and where they are but does not provide any information about their relationship.
Next, we use a stack-pointer parsing model to generate a tree structure representing UI hierarchy. Like other transition-based parsers, our model incrementally predicts a tree structure by generating a sequence of actions that build connections between UI elements using a pointer mechanism. We made two modifications to the original stack-pointer dependency parsing to adapt the parsing model for UI hierarchies. First, we injected a “container” token into the input, allowing the model to create multi-level groupings. Second, we trained the model using a dynamic oracle to reduce exposure bias since the multi-level nature of UI hierarchies leads to exponentially more “optimal” action sequences that produce the same output.
To illustrate how our model predicts UI hierarchy, we will describe the inference process. A flat list of detected UI elements is encoded using a bi-directional LSTM encoder (producing a list l of encoded elements), and the final hidden state is fed to an LSTM decoder network augmented with two data structures: 1) a stack (s) which is used by the network as intermediate memory and 2) a set (v) which records the set of nodes already processed. The stack s is initialized with a special node that represents the root of the tree. At each timestep, the element on top of s and the last hidden state is fed into the decoder network, which outputs one of three actions:
- Arc – A directed edge is created between the node on top of s (parent) and the node in l – v with the highest attention score (child). The child is pushed on s and added to v. This action attaches one of the detected UI elements onto the tree.
- Emit – An intermediate node (represented as a zero-vector) is created and pushed onto s. This action helps the model represent container or “grouping” elements, such as lists, that do not exist in l.
- Pop – s is popped. This occurs when the model has finished adding all of an element’s children to the tree structure.
This technique for generating parse trees is widely used in NLP, and it has been shown that a correct sequence of actions exists for any target tree. Note that this was originally shown for a limited subset of parse trees known as “projective” parse trees, but recent work has extended it to handle any type of tree.
Finally, we apply a set classification model to label containers (i.e., intermediate nodes) based on their descendants. We defined seven container types (including an “Other” class) that represent common groupings such as collections (e.g., lists, grids), tables, and tab bars.

We trained our models on two mobile UI datasets: (i) AMP dataset of ~130,000 iOS screens, and (ii) RICO, a publicly available dataset of ~80,000 Android screens. Both datasets were collected by crowdworkers who installed and explored popular apps across 20+ categories (in some cases excluding certain ones such as games, AR, and multimedia) on the iOS and Android app stores. Each dataset contains screenshots, annotated screens, and a type of metadata called a view hierarchy. The view hierarchy is an artifact generated during UI rendering that describes which interface widgets are used and “stacked” together to produce the final layout. Not all screens in our dataset contain this metadata, especially apps created using third-party UI toolkits or game engines. We apply heuristics to detect and exclude examples with missing or incomplete view hierarchies. The view hierarchies are similar to the presentation model we aim to predict, with a few differences, so we transform them into our target representation by applying graph smoothing, filtering, and element matching between different data sources.
More details about our machine learning models and training procedures can be found in our paper.
Experiments
We used several metrics (e.g., F1 score, graph edit distance) to perform a quantitative evaluation of our system using the test split of our mobile UI datasets. Our main point of comparison was a heuristic-based approach to inferring screen groupings used in previous work, and we found that our system was much more accurate in inferring UI hierarchy. We also found that our improved training procedure led to significant performance gains (23%) over standard methods for training parsers.
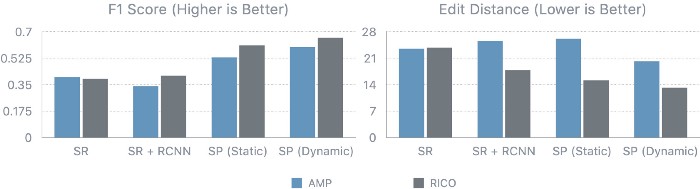
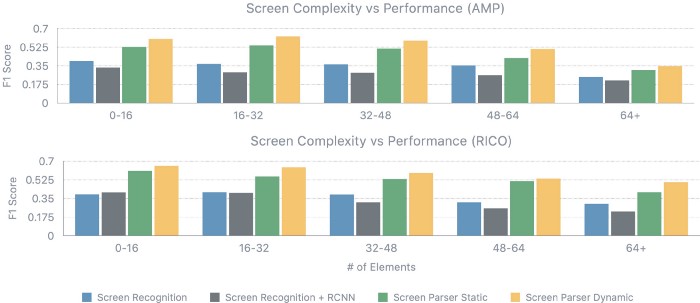
Our system’s performance is affected by a number of factors such as screen complexity and object detection errors. Accuracy is highest for screens up to 32 elements and degrades following that point, in part due to the increased number of actions the parsing model must correctly predict. Complex and crowded screens introduce the additional difficulty of detecting small UI elements, which our analysis with a matching-based oracle (computes best possible matching between object detection output and ground truth) shows as a limiting factor.
UI Hierarchy Facilitates and Improves Applications
We present a suite of example applications implemented using our screen parsing system. These applications show the versatility of our approach and how the predicted UI hierarchy facilitates many downstream tasks.
UI Similarity
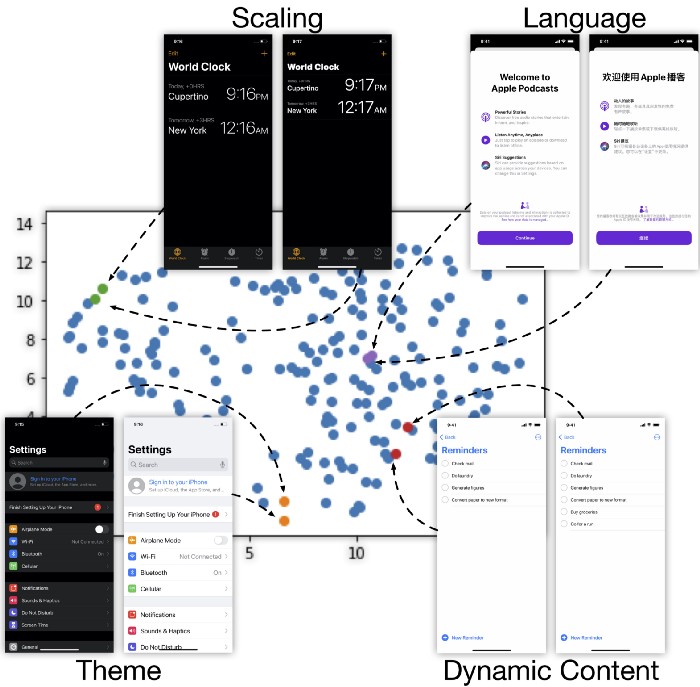
Many recent efforts in modeling UIs have focused on representing them as fixed-length embedding vectors. These vectors can be trained to encode different properties of UI screens, such as layout, content, and style, and they can be fine-tuned to support downstream tasks. For example, a common application of embedding models is measuring screen similarity, which is represented by distance in embedding space. We believe the performance of such models can be improved by incorporating structural information, an important property of UIs.
The intermediate representation of our parsing model can be used to produce a screen embedding, which describes the hierarchical structure of an app. To generate an embedding of a UI, we feed it into our model and pool the last hidden state of the encoder. This includes information about the position, type, and structure of on-screen elements. Our structural embedding can help minimize variations from display settings such as (i) scaling, (ii) language, (iii) theme, and (iv) small dynamic changes. The properties of our embedding could be useful for some UI understanding applications, such as app crawling and information extraction where it would be beneficial to disentangle screen structure and appearance. For example, an app crawler’s next action should be conditioned on the UI elements present on the screen, not on the user’s current theme. An autoencoder trained on UI screenshots would not have this property.
Accessibility Improvement
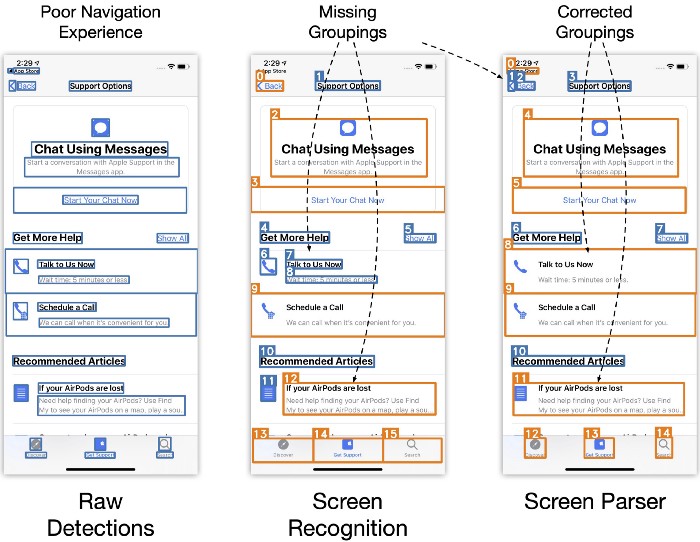
Recent work has successfully generated missing metadata for inaccessible apps by running an object detection model on the UI screenshot. Their approach to generating hierarchical data relies on manually defined heuristics that detect localized patterns between elements. However, these approaches may sometimes fail because they do not have access to global information necessary for resolving ambiguities.
In contrast, our implementation generates a UI hierarchy with a global view of the input, so it can overcome some of the limitations of heuristic-based approaches. We used the predicted UI hierarchy to group together the children of intermediate nodes of height 1 that contained at most one text label and used the X-Y cut algorithm to determine navigation order. The figure above shows an example where the grouping output from the Screen Parsing model is more accurate than the one produced by manually-defined. While this is not always the case, learning grouping rules from data requires much less human effort than manual heuristic engineering.
Code Generation
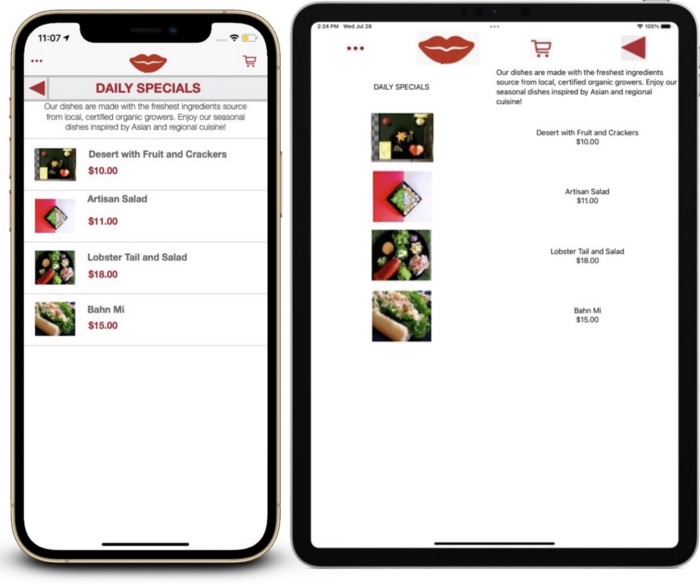
Existing approaches to code generation also rely on heuristics to detect a limited subset of container types. We employed a technique used by compilers to generate code from abstract syntax trees (AST) (the visitor pattern for code generation) and applied it to the predicted UI hierarchy. Specifically, we performed a depth-first traversal of the UI hierarchy using a visitor function that generates code based on the current state (current node and stack). The visitor function emits a SwiftUI control (e.g., Text, Toggle, Button) at every leaf node and emits a SwiftUI container (e.g., VStack, HStack) at every intermediate node. Additional parameters required by view constructors, such as label text and background color were extracted using OCR and a small set of heuristics.
The resulting code describes the original UI using only relative constraints (even if the original UI was not), allowing it to act responsively to changes in screen size or device type. The generated code does not contain appearance and style information, which is sometimes necessary to render a similar-looking screen. Nevertheless, prior work has shown that such output can be a useful starting point for UI development, and we believe future work can improve upon our approach by detecting these properties.
Conclusion
To help machines better reason about the underlying structure and purpose of UIs, we introduced the problem of screen parsing, the prediction of structured UI models from visual information. Our problem formulation captures the structural properties of UIs and is well-suited for downstream applications that rely on UI understanding. We described the architecture and training procedure for our reference implementation, which predicts an app’s presentation model as a UI hierarchy with high accuracy, surpassing baseline algorithms and training procedures. Finally, we used our system to build three example applications: (i) UI similarity search, (ii) accessibility enhancement, and (iii) code generation from UI screenshots. Screen parsing is an important step towards full machine understanding of UIs and its many benefits, but there is still much left to do. We’re excited by the opportunities at the intersection of HCI and ML, and we encourage other researchers in the ML community to work with us to realize this goal.
Acknowledgements
Many people contributed to this work and gave feedback on this blog post: Xiaoyi Zhang, Jeff Nichols, and Jeff Bigham. This work was done while Jason Wu was an intern at Apple.
For more information about machine learning research at Apple, check out the Apple Machine Learning website.
Paper Citation
Jason Wu, Xiaoyi Zhang, Jeffrey Nichols, and Jeffrey P. Bigham. 2021. Screen Parsing: Towards Reverse Engineering of UI Models from Screenshots. In Proceedings of the 2021 ACM Symposium on User Interface Software & Technology (UIST). Association for Computing Machinery, New York, NY, USA, 1–10. https://doi.org/10.1145/3472749.3474763
This article was initially published on the ML@CMU blog and appears here with the authors’ permission.
tags: deep dive

AUAI is supported by:








