
ΑΙhub.org
Does AutoML work for diverse tasks?
By Misha Khodak and Ameet Talwalkar
Over the past decade, machine learning (ML) has grown rapidly in both popularity and complexity. Driven by advances in deep neural networks, ML is now being applied far beyond its traditional domains like computer vision and text processing, with applications in areas as diverse as solving partial differential equations (PDEs), tracking credit card fraud, and predicting medical conditions from gene sequences. However, progress in such areas has often required expert-driven development of complex neural network architectures, expensive hyperparameter tuning, or both. Given that such resource intensive iteration is expensive and inaccessible to most practitioners, AutoML has emerged with an overarching goal of enabling any team of ML developers to deploy ML on arbitrary new tasks. Here we ask about the current status of AutoML, namely: can available AutoML tools quickly and painlessly attain near-expert performance on diverse learning tasks?
This blog post is dedicated to two recent but related efforts that measure the field’s current effectiveness at achieving this goal: NAS-Bench-360 and the AutoML Decathlon. The first is a benchmark suite focusing on the burgeoning field of neural architecture search (NAS), which seeks to automate the development of neural network models. With evaluations on ten diverse tasks—including a precomputed tabular benchmark on three of them—NAS-Bench-360 is the first NAS testbed that goes beyond traditional AI domains such as vision, text, and audio signals. Specifically, the 10 tasks vary in their domain (including image, finance time series, audio, and natural sciences), problem type (including regression, single-label, and multi-label classification), and scale (ranging from several thousands to hundreds of thousands of observations).
The second is a NeurIPS 2022 competition (which we are soft-launching today!) that builds on our NAS-Bench-360 work yet has a broader vision of understanding what is truly the best approach for a practitioner to take when faced with a modern ML problem. During the public development phase of the competition we will release a set of diverse tasks that will be representative of (but distinct from) the final set of test tasks on which evaluation will be performed. Unlike most past competitions in the AutoML community, competitors in the AutoML Decathlon are free (and in fact encouraged) to consider a wide range of approaches from traditional hyperparameter optimization and ensembling methods to modern techniques such as NAS and large-scale transfer learning.
You can learn more about getting involved with either of these efforts at the bottom of this post.
NAS-Bench-360: A NAS Benchmark for diverse tasks
NAS-Bench-360 is a benchmark suite consisting of ten ML tasks that we developed jointly with Renbo Tu, Nick Roberts, Junhong Shen, and Fred Sala. These tasks represent a diverse set of signals, including various kinds of imaging sources, simulation data, genomic data, and more. At the same time, we constrain all tasks to be amenable to modern NAS search spaces, i.e. we do not include tabular or graph-based data, thus allowing for the application of most NAS methods. Our evaluation on NAS-Bench-360 is thus a robustness test that checks whether the massive amount of largely computer vision-driven progress in the field of NAS is actually indicative of wider success of AutoML across a variety of applications, data types, and tasks. More importantly, the benchmark will serve as a useful tool to develop and evaluate new, better methods for NAS.
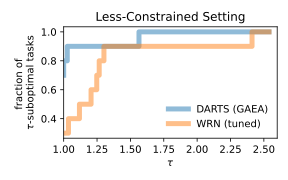
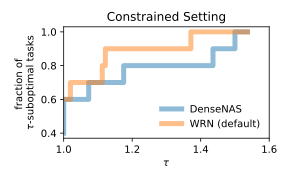
So can AutoML tools—specifically NAS methods—quickly and painlessly attain near-expert performance on NAS-Bench-360? In positive news, searching over a large search space such as DARTS using a state-of-the-art algorithm such as GAEA does yield models that outperform available expert architectures on half of the tasks, in addition to consistently beating perennial Kaggle favorite XGBoost and a recent attempt at a general-purpose architecture, Perceiver IO. On the other hand it fails catastrophically on several tasks, doing little better than a simple baseline, namely a tuned Wide ResNet (Figure 1, left panel). Indeed, despite being developed on CIFAR-10 it does surprisingly poorly on 2D classification tasks from the medical and audio domains. Furthermore, in a resource-constrained setting where AutoML methods are not given much more time than running a single architecture, the leading NAS method DenseNAS does worse than an untuned Wide ResNet (Figure 1, right panel).
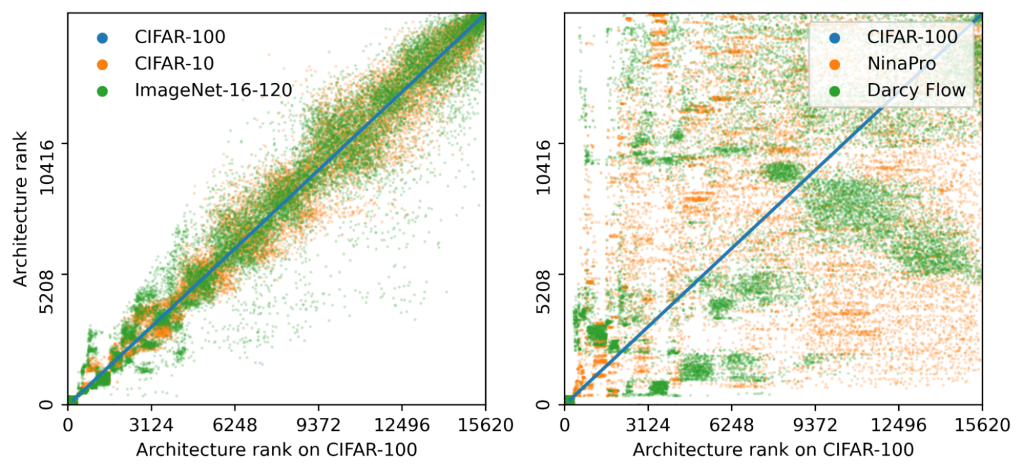
Our evaluation of modern NAS methods on NAS-Bench-360 demonstrates the need for such a benchmark and a lack of robustness in the field. NAS-Bench-360 is also useful for understanding past and future search spaces and algorithms, specifically whether current beliefs about NAS extend to diverse tasks. For example, Figure 2 shows that high-performing architectures transfer well between vision tasks—a quality used extensively in NAS research—but not between diverse tasks. Other examples of scientific uses of NAS-Bench-360—such as one investigating a recent paper on operation redundancy—are provided in our paper and in a recent ICLR 2022 blog post on zero-cost proxies. We also expect NAS-Bench-360 to be used for the development of new NAS methods; to further this, for two of the datasets we provide precomputed models for all architectures in the NAS-Bench-201 search space; together with existing CIFAR-100 precompute results this means three NAS-Bench-360 datasets have precomputed tabular benchmarks to accelerate search algorithm development.
The AutoML Decathlon: A competition focused on diverse tasks and methods


Our goal in releasing NAS-Bench-360 is to spur the development of NAS methods that work well on diverse tasks. However, given the mixed performance of NAS on this benchmark, there remains a question of whether automatic architecture design should even be the focus of AutoML research more broadly. Building on our efforts from NAS-Bench-360, a group of researchers at CMU, Hewlett Packard Enterprise (HPE), Wisconsin-Madison, and Morgan Stanley are organizing the AutoML Decathlon competition at NeurIPS 2022 precisely to ask the following broader question: what automated technique(s) are best for diverse tasks?
This competition is designed to address two gaps between research and practice:
- Lack of task diversity. The field of NAS is no exception here, as the vast majority of recent AutoML benchmarking and competition efforts have focused on computer vision or other well studied tasks in speech and language processing. Evaluating AutoML methods on such well-studied tasks does not give a good indication of their utility on more far-afield applications.
- Siloed methodological development. Many developments in AutoML narrowly focus on particular techniques rather than the downstream benefits to the end user. A practitioner with a specific ML task ultimately cares about the quality of the resulting model (in terms of accuracy and other non-accuracy metrics), as opposed to the underlying technical details of the procedure yielding this model, e.g., whether the model is the result of a weight-sharing NAS method, a fine-tuned large model, a more classical non-deep learning AutoML technique, or some other automated procedure.
By designing our competition in a practitioner-centric fashion and accounting for the two aforementioned gaps, our competition aims to spur innovation in AutoML with results that are directly transferable to ML practitioners. We envision that the results of our competition will provide novel empirical insights into several open practical and scientific questions, including:
- Given the growing methodological diversity of (Auto)ML approaches, what methods should I consider as a practitioner in 2022?
- How do leading NAS methods compare to the increasingly popular pre-training/fine-tuning paradigm?
- How do either of these more modern approaches compare to classical AutoML approaches or to standard baselines such as XGBoost or a tuned ResNet?
- Should I consider using any AutoML procedure given that I’m working on a specific scientific, technological, or industrial problem that seemingly differs drastically from well-studied tasks in computer vision and NLP?
- Given a reasonable computational budget, can any AutoML approach (whether classical or more modern) consistently outperform bespoke models that were hand-crafted by either domain experts and/or ML experts?
We note that while AutoML is not a new research area, we view our competition as being particularly timely given (1) rapid growth of ML task diversity, (2) progress in ML model development, and (3) acceleration in the scale of both datasets and available compute resources. Indeed, recent progress along these three dimensions has led us to make remarkably different design choices from those of past competitions like the AutoDL competition, which was launched just three years ago. For instance, we work with bigger datasets, allow larger computational budgets, consider an expanding set of applications, and perform more robust evaluations based on performance profiles. Relatedly, while over the past three years we’ve witnessed significant progress in NAS and the emergence of the pretrain/fine-tuning paradigm in various settings, neither of these types of approaches featured prominently in the AutoDL competition (or other past competitions). In contrast, we hypothesize that these approaches will be more prominently featured in the AutoML Decathlon.
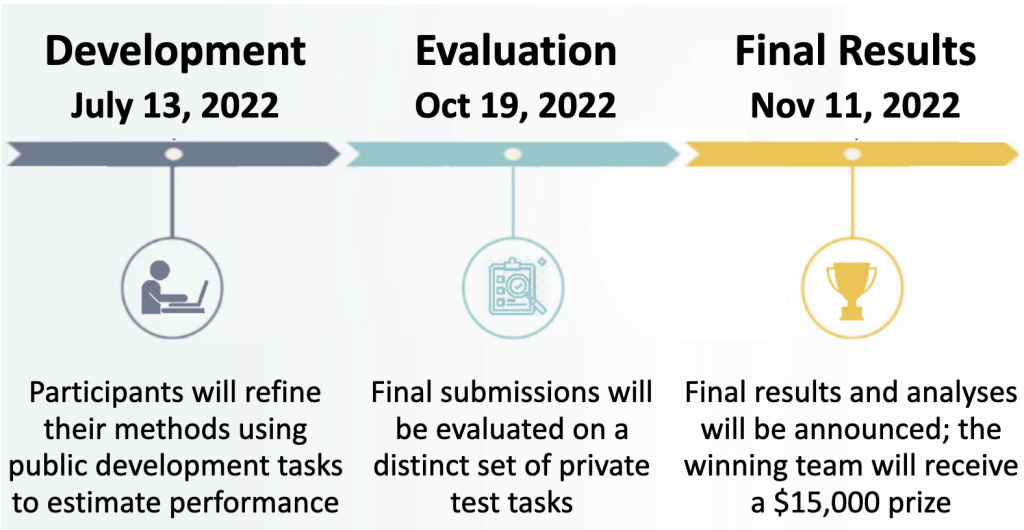
The AutoML Decathlon is built around a set of 20 datasets that we have curated which represent a broad spectrum of practical applications in scientific, technological, and industrial domains. As explained in Figure 3, ten of the tasks will be used for development and an additional ten tasks will be used for final evaluation and revealed only after the competition. We will provide computational resources to participants as needed, with funding provided by Morgan Stanley. The results of our performance-profile based evaluation will determine monetary prizes, including a $15K first prize, with sponsorship provided by HPE.
Getting Involved: Using NAS-Bench-360 and competing in the AutoML Decathlon
Our goal with both NAS-Bench360 and the AutoML Decathlon is to encourage community participation in evaluating what AutoML is already good at, what areas need improving, and what directions seem most promising for future work. We hope that these rigorous benchmarking activities will help the field more rapidly move towards a truly democratized ML toolkit that can be used by researchers and practitioners alike.
To learn more, check out the following links:
- NAS-Bench360: You can download the ten datasets on the website, and learn more about the benchmark and our various insights from our paper.
- AutoML Decathlon: The competition officially starts next week and runs through mid October, but we are soft-launching today to spread the word. You can learn more about the details at the competition website and the associated CodaLab website.
Also, stay tuned for a follow up blog post where our collaborator Junhong Shen describes our recent algorithmic NAS work targeting diverse tasks.
This article was initially published on the ML@CMU blog and appears here with the authors’ permission.
tags: deep dive

AUAI is supported by:








