
ΑΙhub.org
Bottom-up top-down detection transformers for open vocabulary object detection

We perform open vocabulary detection of the objects mentioned in the sentence using both bottom-up and top-down feedback.
By Ayush Jain and Nikolaos Gkanatsios
Object detection is the fundamental computer vision task of finding all “objects” that are present in a visual scene. However, this raises the question, what is an object? Typically, this question is side-stepped by defining a vocabulary of categories and then training a model to detect instances of this vocabulary. This means that if “apple” is not in this vocabulary, the model does not consider it as an object. The problem gets even worse when we try to integrate these object detectors into real household agents. Imagine that we want a robot that can pick up “your favorite green mug from the table right in front of you”. We want the robot to specifically detect the “green mug” which is on the “table in front of you” and not any other mug or table. Obviously, treating descriptions such as “green mug from the table right in front of you” as separate classes in the detector’s vocabulary cannot scale; one can come up with countless variations of such descriptions.
In light of this, we introduce Bottom-up Top-Down DEtection TRansformer (BUTD-DETR pron. Beauty-DETER), a model that conditions directly on a language utterance and detects all objects that the utterance mentions. When the utterance is a list of object categories, BUTD-DETR operates as a standard object detector. It is trained from both fixed vocabulary object detection datasets and referential grounding datasets which provide image-language pairs annotated with the bounding boxes for all objects referred to in the language utterance. With minimal changes, BUTD-DETR grounds language phrases both in 3D point clouds and 2D images.

No box bottleneck: BUTD-DETR decodes object boxes directly by attending to language and visual input instead of selecting them from a pool. Language-directed attention helps us localize objects that our bottom-up, task-agnostic attention may miss. For example, in the above image, the hint of “clock on top of the shelf” suffices to guide our attention to the right place, though the clock is not a salient object in the scene. Previous approaches for language grounding are detection-bottlenecked: they select the referred object from a pool of box proposals obtained from a pre-trained object detector. This means that if the object detector fails, then the grounding model will fail as well.
How does it work?
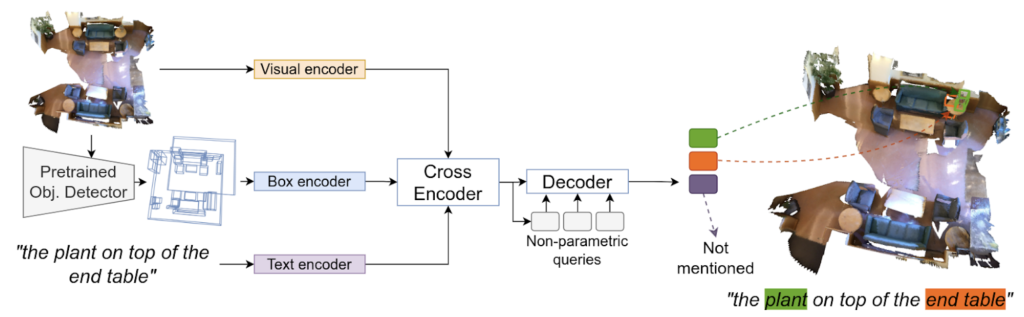
The input to our model is a scene and a language utterance. A pre-trained object detector is used to extract box proposals. Next, the scene, boxes, and utterance are encoded using per-modality-specific encoders into visual, box, and language tokens respectively. These tokens are contextualized by attending to one another. The refined visual tokens are used to initialize object queries that attend to the different streams and decode boxes and spans.
Augmenting supervision with detection prompts
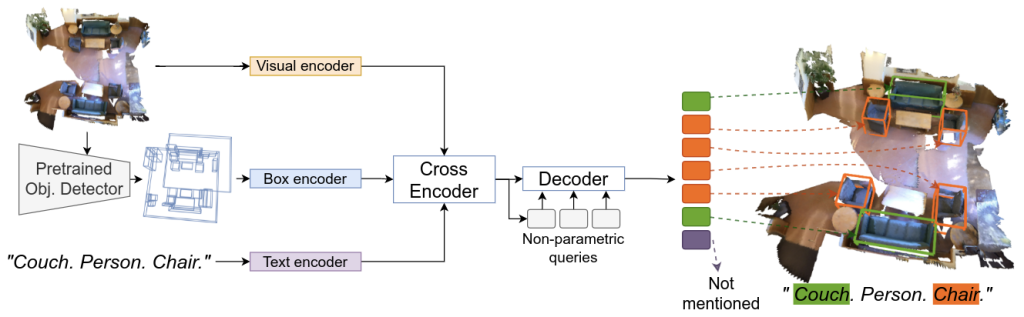
Object detection is an instance of referential language grounding in which the utterance is simply the object category label. We cast object detection as the referential grounding of detection prompts: we randomly sample some object categories from the detector’s vocabulary and generate synthetic utterances by sequencing them, e.g., “Couch. Person. Chair.”, as shown in the figure above. We use these detection prompts as additional supervision data: the task is to localize all object instances of the category labels mentioned in the prompt if they appear in the scene. For the category labels with no instances present in the visual input (e.g. “person” in the above figure), the model is trained to not match them to any boxes. In this way, a single model can perform both language grounding and object detection simultaneously and share the supervision information.
Results
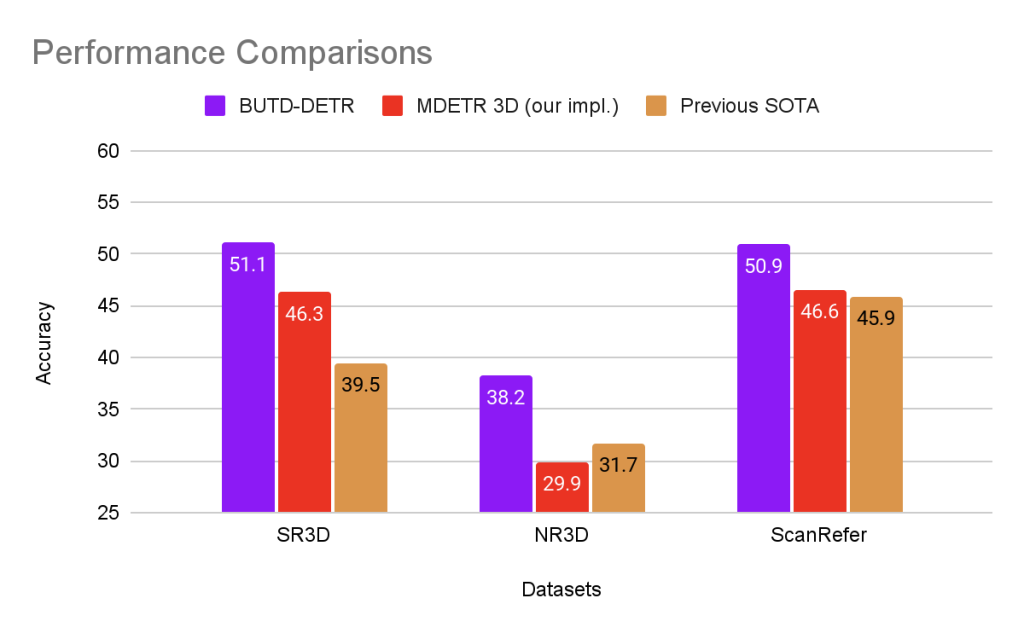
BUTD-DETR achieves a large boost in performance over state-of-the-art approaches across all 3D language grounding benchmarks (SR3D, NR3D, ScanRefer). Moreover, it was the winning entry in the ReferIt3D challenge, held at the ECCV workshop on Language for 3D Scenes. On 2D language grounding benchmarks, BUTD-DETR performs on par with state-of-the-art methods when trained on large-scale data. Importantly, our model converges twice as fast compared to state-of-the-art MDETR, mainly because of the efficient deformable attention which we used with our 2D model.
We show the qualitative results of our model in the video at the beginning of the blog. For more visualizations, please refer to our project page and paper.
What’s next?
Our method detects all objects mentioned in the sentence — however, this assumes that the user needs to mention all relevant objects in the sentence. This is not desirable in general — for example, in response to “make breakfast” we would like our model to detect all the relevant ingredients like bread, eggs etc., even if they are not mentioned in the sentence. Additionally, while our architecture works for both 2D and 3D language grounding with minimal changes, we do not share parameters between the two modalities. This prevents transferring representations across modalities, which would be particularly helpful for the low-resource 3D modality. Our ongoing work is investigating these two directions.
We have released our code and model weights on GitHub, making it easy to reproduce our results and build upon our method. If you are interested in a language-conditioned open vocabulary detector for your project, then give BUTD-DETR a run! For more details, please check out our project page and paper.
This article was initially published on the ML@CMU blog and appears here with the authors’ permission.
tags: deep dive

AUAI is supported by:








