
ΑΙhub.org
Methods for addressing class imbalance in deep learning-based natural language processing
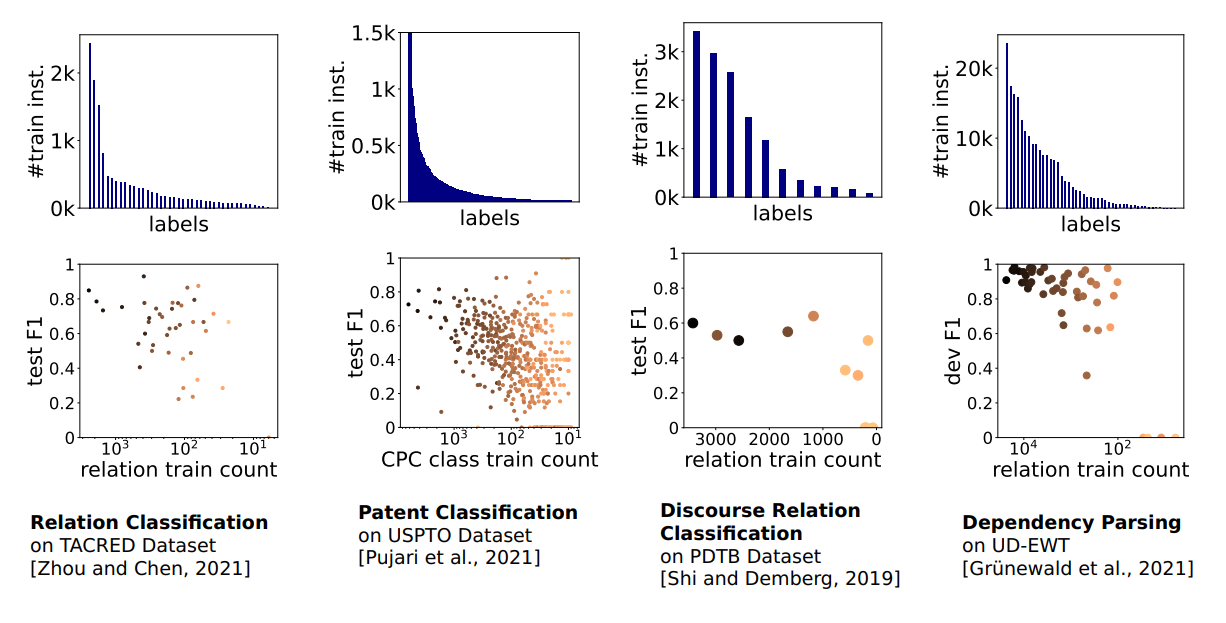 Figure 1: Modern Transformer-based Natural Language Processing (NLP) methods still struggle with class imbalance: class-wise performance (second row, each dot represents one class) decreases with class frequency in training data (first row) for a variety of NLP tasks. Datasets/scores: TACRED, Zhou and Chen [2021], USPTO, Pujari et al. [2021], PDTB, Shi and Demberg [2019], UD-EWT, Grünewald et al. [2021].
Figure 1: Modern Transformer-based Natural Language Processing (NLP) methods still struggle with class imbalance: class-wise performance (second row, each dot represents one class) decreases with class frequency in training data (first row) for a variety of NLP tasks. Datasets/scores: TACRED, Zhou and Chen [2021], USPTO, Pujari et al. [2021], PDTB, Shi and Demberg [2019], UD-EWT, Grünewald et al. [2021].
Natural Language Processing (NLP) tasks are often addressed by training supervised models using manually labeled datasets. This comes with the challenge that categories rarely occur with the exact same frequency; in practice, the distribution of samples across classes is usually highly skewed. In sentiment analysis, there may be a large number of negative reviews, with only a small number of positive reviews. Text classification tasks such as patent categorization or medical code prediction even use inventories of hundreds of classes with label distributions following a long tail.
Such class imbalance in the training and evaluation datasets can pose a challenge for NLP models, which are more heavily influenced by majority class data during training. As a result, NLP models tend to perform poorly on the minority classes, which often contain the cases that are most important and informative to the downstream user. For example, the TACRED relation extraction dataset covers more than 40 relations between entities such as persons and organizations, e.g., org:founded_by indicates the founder of an organization. An infrequent relation in this dataset is org:shareholders, which holds between organizations and their shareholders. Though infrequent, the relation may be of special interest in a business use case that aims to identify the players in a business field. While impressive improvements have been measured on NLP benchmarks in the past years, the problem of training models in class-imbalanced scenarios remains challenging (see Figure 1).
Whether you are an NLP researcher or an NLP developer, you have probably come across this issue and may now be looking for options how to address it. This blogpost gives an overview of class imbalance methods for deep learning-based NLP organized by method type [Henning et al., 2022]. Which methods are suitable for your use case depends on the nature of your classification task, e.g., whether all classes are equally important to you, and also on practical considerations such as computational resources. Our practical decision aid in Figure 2 suggests starting points for typical use cases. We then give intuitive explanations for a selected set of methods for addressing class imbalance in NLP. At the end, we discuss open challenges and directions for further research.
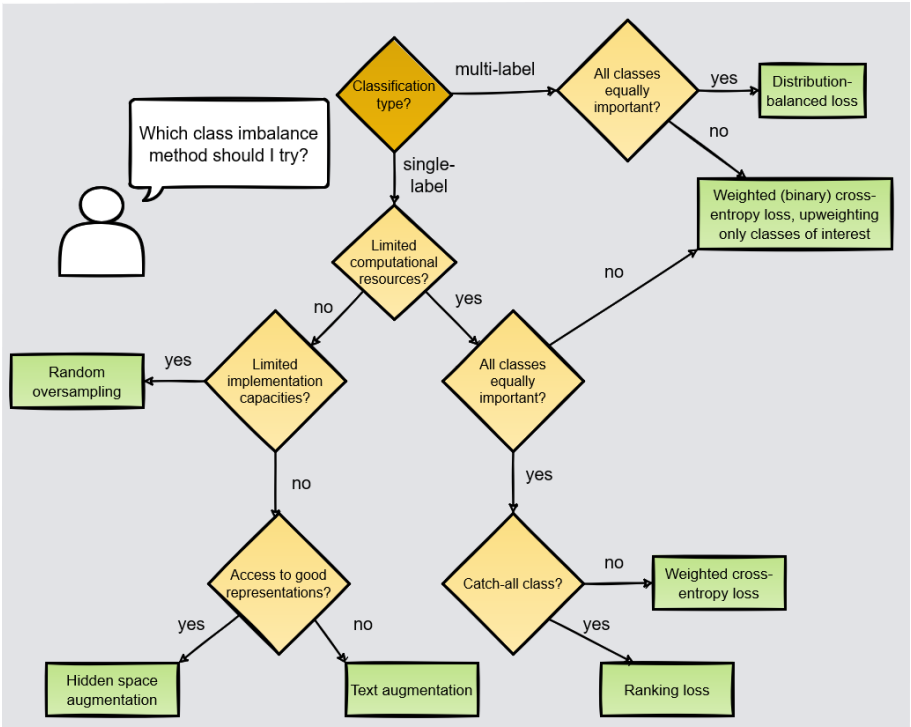 Figure 2: A practical decision aid for addressing class-imbalanced problems in NLP following Henning et al. [2022].
Figure 2: A practical decision aid for addressing class-imbalanced problems in NLP following Henning et al. [2022].
What is Natural Language Processing?
NLP aims to enable computers to understand, interpret, and generate human language and is thus an interdisciplinary field at the intersection of linguistics, computer science, and artificial intelligence. Recent advances in NLP have been driven by the availability of large datasets and the development of powerful deep learning models such as Transformers.
How does class imbalance affect NLP models?
If a model fails to learn a good decision boundary easily, it will predict the majority class in case of doubt. This problem may be aggravated in NLP tasks that require treating a large, often heterogenous catch-all class that contains all instances that are not of interest to the task, while the remaining (minority) classes are approximately same-sized. An example of this is the “Outside” label in IOB sequence tagging.
Evaluation results might be misleading in class-imbalanced scenarios. For example, accuracy might be high even if the model does not predict the minority class(es) at all. Accuracy is an example of a metric that is dominated by the large classes – every instance contributes equally to the metric and large classes have many more instances than the minority class(es). It is therefore important to carefully choose evaluation metrics that are appropriate for the use case. For instance, if all classes are equally important, the unweighted average of per-class F1 scores (macro F1) is a viable option. If we care mainly about finding instances of a minority class as in the org:shareholder problem above, optimizing for the F1 score of this class may be more meaningful.
Re-Sampling
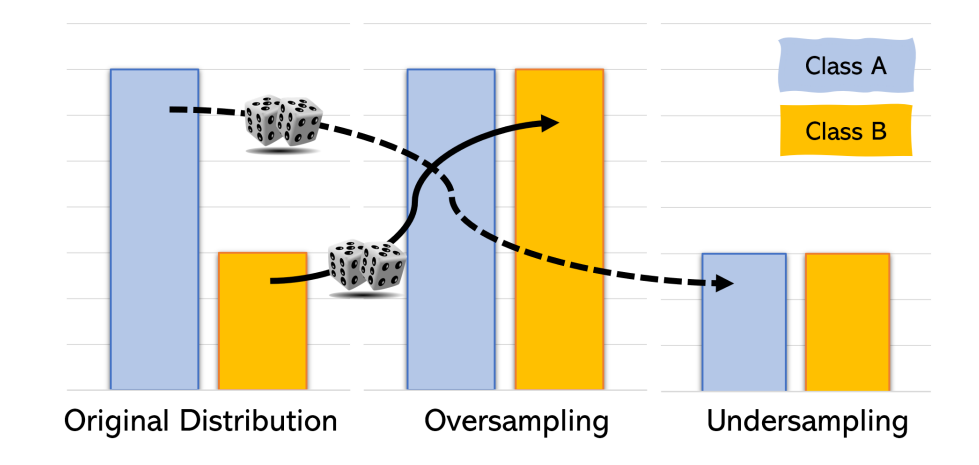 Figure 3: Random oversampling usually outperforms undersampling, but increases training time.
Figure 3: Random oversampling usually outperforms undersampling, but increases training time.
To increase the importance of minority instances in training, the label distribution can be changed by various sampling strategies that duplicate or remove instances. Sampling can either be executed once or repeatedly during training. In random oversampling (ROS), a random choice of minority instances are duplicated, whereas in random undersampling (RUS), a random choice of majority instances are removed from the dataset (see Figure 3). When applied in deep learning, ROS usually outperforms RUS. More flexible class-based sampling variants can also further improve results. For example, the amount of re-sampling can be tuned separately for each class. This can be done repeatedly during training based on the current model performance on the various classes.
In multi-label classification, over-sampling an instance with a minority label may simultaneously amplify the majority class count due to label dependencies between majority and minority classes [Huang et al., 2021]. Effective sampling in such settings is still an open issue. Existing approaches monitor the class distributions during sampling or assign instance-based sampling probabilities.
A good starting point for implementing sampling techniques is the imblearn package for Python.
Data Augmentation
While re-sampling approaches make the model focus more on the minority classes and thereby can lead to moderate gains, their effectiveness is inherently limited by the available data. To overcome this limitation, one could, for instance, write or select additional minority examples. However, this is particularly laborious in naturally imbalanced settings. First, looking for additional minority instances means trying to find the needle in the haystack. By definition, minority instances are rare in natural data, so large amounts of text data need to be collected to retrieve these instances. Second, the minority class examples found with this type of effort may be biased, e.g., due to collection via keyword queries. Synthetically generating additional minority instances (see Figure 4) thus is a promising direction.
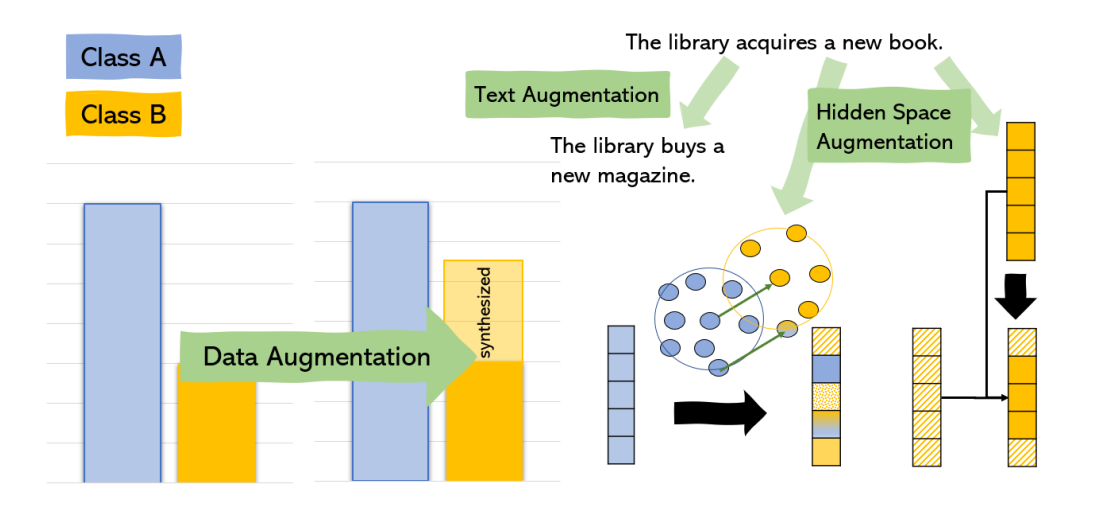 Figure 4: Data Augmentation methods can help in class-imbalanced NLP settings.
Figure 4: Data Augmentation methods can help in class-imbalanced NLP settings.
Text augmentation generates new natural language instances of minority classes, ranging from simple string-based manipulations such as synonym replacements over machine translation-based approaches to prompting Transformer models.
Hidden space augmentation generates new instance vectors that are not directly associated with a particular natural language string, leveraging the representations of real examples. For example, the TextCut algorithm [Jiang et al., 2021] randomly replaces small parts of the BERT representation of one instance with those of the other. More advanced hidden space augmentation methods learn or perform operations on the vector space, e.g., by sampling a majority instance and adding or subtracting the direction of a typical minority instance.
Staged Learning
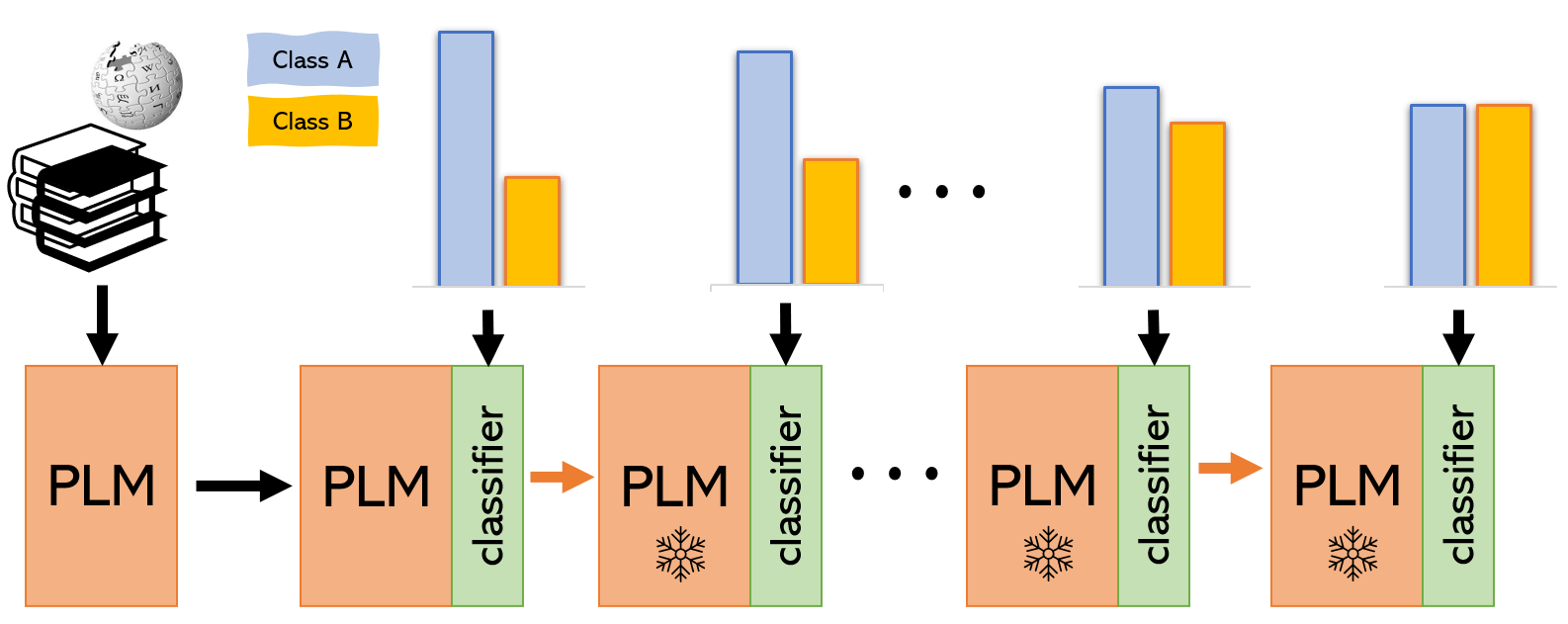 Figure 5: Staged learning fine-tunes representations in a first stage, which are then frozen. In this example, the training data of the stages that fine-tune the classifier layers is sampled such that it gets more balanced with each stage. PLM: pretrained language model.
Figure 5: Staged learning fine-tunes representations in a first stage, which are then frozen. In this example, the training data of the stages that fine-tune the classifier layers is sampled such that it gets more balanced with each stage. PLM: pretrained language model.
Re-sampling and data augmentation approaches can reduce the classifier’s bias towards the majority class(es), but they can also make the learned features less representative of the underlying data distribution. One approach to finding a good trade-off between reducing classifier bias and learning representative features is to perform the training in several stages (see Figure 5 for an example setup). In computer vision, two-staged training has been proposed as a means to mitigate class imbalance [Kang et al., 2020]. The aim of the first stage is to learn good representations, which are then frozen. In the second stage, only the classifier layers are updated.
In NLP, deep learning models are usually based on pre-trained neural text encoders or word embeddings, and further in-domain pre-training has been shown to be beneficial. Imbalanced classification can further be addressed as a continual learning task with k stages where the data gradually becomes more balanced from stage to stage [Jang et al., 2021]. The first stage contains the most imbalanced subset, and then the degree of imbalance decreases, with the last stage presenting the most balanced subset.
Model design
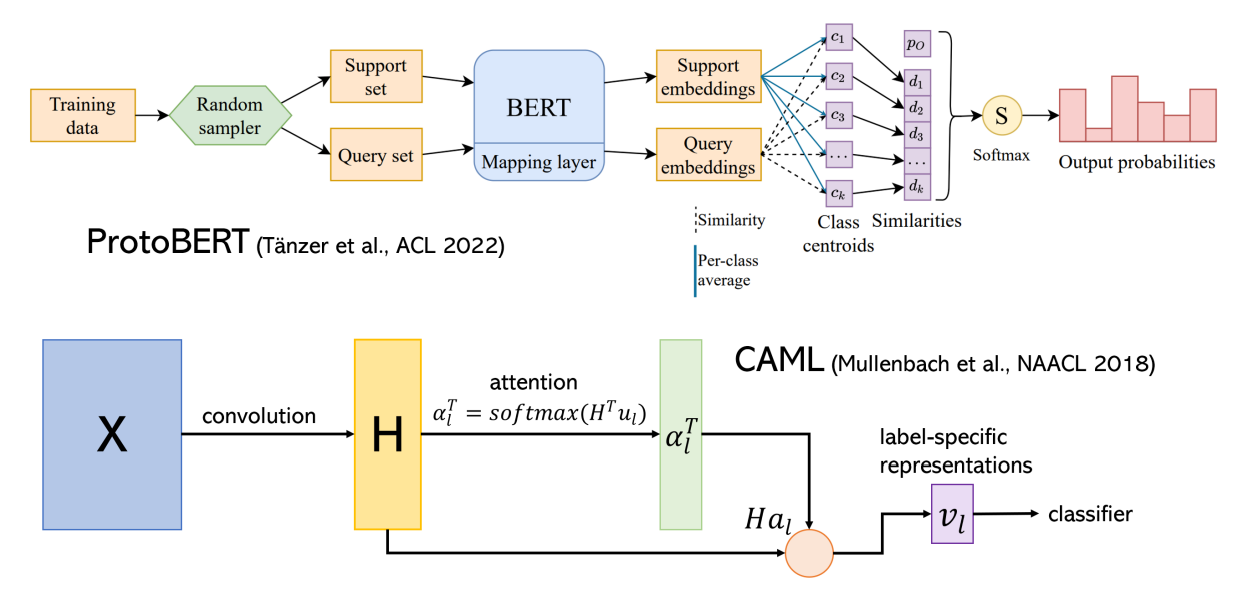 Figure 6: Model architectures for imbalanced classification: ProtoBERT and Convolutional Attention for Multi-Label Classification (CAML, Mullenbach et al. [2018]). Image source (top row): Tänzer et al. [2022].
Figure 6: Model architectures for imbalanced classification: ProtoBERT and Convolutional Attention for Multi-Label Classification (CAML, Mullenbach et al. [2018]). Image source (top row): Tänzer et al. [2022].
Sampling and data augmentation are methods that can be applied largely independent of model architecture. Another option to tackle class imbalance is to make modifications to existing models or even design architectures that aim at improving performance in imbalanced settings.
One possibility is to train a network to obtain prototypical representations for each class, and predict classes for test instances based on their distance to these prototypical class representations (see Figure 6). For example, ProtoBERT [Tänzer et al., 2022] uses class centroids in a learned BERT-based feature space and, when applied to a task with a catch-all class, treats the distance of any instance to this class as just another learnable parameter. If prior knowledge on the task and/or dataset is available, e.g., known biases in the dataset, this may be incorporated into the model structure.
A research area closely related to class imbalance is few-shot learning which aims to learn classes based on only very few training examples. Model ideas from few-shot learning can be leveraged for long-tailed settings, e.g., by making use of relational information between class labels or by computing label-specific representations.
Loss Functions
Standard cross-entropy loss (see Figure 7) is composed from the predictions for instances that carry the label in the gold standard, which is why the resulting classifiers fit the minority classes less well. Loss functions that are specifically designed for class-imbalanced scenarios either re-weight instances by class membership or prediction difficulty, or explicitly model class margins to change the decision boundary.
Weighted cross entropy uses class-specific weights that are tuned as hyperparameters or set to the inverse class frequency. Rather than re-weighting instances, LDAM (label-distribution-aware margin loss), essentially a smooth hinge loss with label-dependent margins, aims to increase the distance of the minority class instances to the decision boundary with the aim of better generalization for these classes [Cao et al., 2019]. As it encourages larger margins for minority classes, LDAM might be an appropriate loss function in settings with a large catchall class, whose representations often take up much of the representation space. Ranking losses can also be effective to incentivize the model to only pay attention to “real” classes.
In multi-label classification, each label assignment can be viewed as a binary decision, hence binary cross entropy (BCE) is often used here. Under imbalance, two issues arise. First, although class-specific weights have been used with BCE, their effect on minority classes is less clear than in the single-label case. For each instance, all classes contribute to BCE, with the labels not assigned to the instance (called negative classes) included via (1 − yj) log(1 − pj). Thus, if weighted binary cross entropy (WBCE) uses a high weight for a class, it also increases the importance of negative instances for a minority class, which may further encourage the model to not predict this minority class. To leverage class weights more effectively in BCE for multi-label classification, one option is to only re-weight the part of the loss associated with the positive instances (see WBCE positive in Figure 7).
Second, training with BCE implies treating the logits of different classes independently of each other (as each label assignment is a binary decision), whereas in training with CE, the logits of different classes depend on each other. This difference has motivated the design of multi-label specific losses for class-imbalanced scenarios such as distribution-balanced loss [Wu et al., 2020], which has been shown to be very effective in multi-label text classification [Huang et al., 2021].
 Figure 7: Overview of loss functions suitable in imbalanced classification scenarios, formulated for one instance.
Figure 7: Overview of loss functions suitable in imbalanced classification scenarios, formulated for one instance.
Recent Trends and Challenges
What works (best)? As there is no established benchmark for class-imbalanced settings in NLP, evaluation results are hard to compare across papers. In general, re-sampling or changing the loss function may lead to small to moderate gains. For data augmentation, the reported performance increases tend to be larger than for re-sampling or new loss functions. The effects of staged training or modifications of the model vary drastically, ranging from detrimental to very large performance gains.
Hence, re-sampling, data augmentation, and changing the loss function are straightforward choices in class-imbalanced settings. Approaches based on staged learning or model design may sometimes outperform them, but often come with a higher implementation or computational cost.
How should we report results? Much NLP research only reports aggregate statistics, making it hard to judge the impact on improvements by class, which is often important in practice. We thus argue that NLP researchers should always report per-class statistics. Opensourcing spreadsheets with the exact numbers would enable the community to compare systems more flexibly from multiple angles, i.e., with respect to whichever class(es) matter in a particular application scenario, and to re-use this data in research on class imbalance.
A main hindrance to making progress on class imbalance in computer vision and NLP alike is that experimental results are often hard to compare. A first important step would be to not restrict baselines to methods of the same type, e.g., a new data augmentation approach should not only be compared to other data augmentation methods, but also to using loss functions for class imbalance. Establishing a shared and systematic benchmark of a diverse set of class-imbalanced NLP tasks would be highly beneficial for both researchers and practitioners.
How can we move forward? Most work on class-imbalanced NLP has focused on single-label text classification, whereas multi-label settings are still an open research challenge. New class imbalance methods may emerge from few-shot learning or prompting. Class imbalance also poses problems in structured prediction tasks such as sequence labeling or parsing, where many classification decisions need to be optimized jointly. Moreover, we need to study how class imbalance methods affect prediction confidence estimates.
References
Sophie Henning, William H. Beluch, Alexander Fraser, and Annemarie Friedrich. A survey of methods for addressing class imbalance in deep-learning based natural language processing. CoRR, 2022.
Yi Huang, Buse Giledereli, Abdullatif Köksal, Arzucan Özgür, and Elif Ozkirimli. Balancing methods for multi-label text classification with long-tailed class distribution. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, November 2021.
Wanrong Jiang, Ya Chen, Hao Fu, and Guiquan Liu. Textcut: A multi-region replacement data augmentation approach for text imbalance classification. In Neural Information Processing: 28th International Conference, ICONIP 2021.
Bingyi Kang, Saining Xie, Marcus Rohrbach, Zhicheng Yan, Albert Gordo, Jiashi Feng, and Yannis Kalantidis. Decoupling representation and classifier for long-tailed recognition. In 8th International Conference on Learning Representations, ICLR 2020.
Joel Jang, Yoonjeon Kim, Kyoungho Choi, and Sungho Suh. Sequential targeting: A continual learning approach for data imbalance in text classification. Expert Systems with Applications, 2021.
James Mullenbach, Sarah Wiegreffe, Jon Duke, Jimeng Sun, and Jacob Eisenstein. Explainable prediction of medical codes from clinical text. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2018.
Michael Tänzer, Sebastian Ruder, and Marek Rei. Memorisation versus generalisation in pretrained language models. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, 2022.
Kaidi Cao, Colin Wei, Adrien Gaidon, Nikos Arechiga, and Tengyu Ma. Learning imbalanced datasets with label-distribution-aware margin loss. In Advances in Neural Information Processing Systems, volume 32, 2019.
Tong Wu, Qingqiu Huang, Ziwei Liu, Yu Wang, and Dahua Lin. Distribution-balanced loss for multi-label classification in long-tailed datasets. In Computer Vision – ECCV 2020.
tags: deep dive


AUAI is supported by:








