
ΑΙhub.org
On privacy and personalization in federated learning: a retrospective on the US/UK PETs challenge
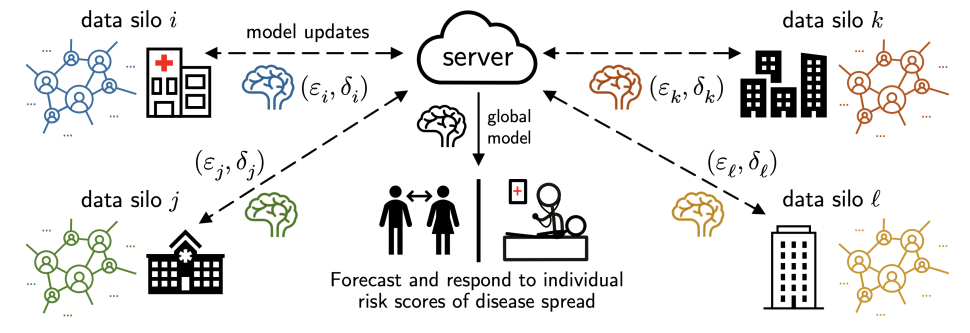
TL;DR: We study the use of differential privacy in personalized, cross-silo federated learning (NeurIPS’22), explain how these insights led us to develop a 1st place solution in the US/UK Privacy-Enhancing Technologies (PETs) Prize Challenge, and share challenges and lessons learned along the way. If you are feeling adventurous, checkout the extended version of this post with more technical details!
By Ken Liu and Virginia Smith
How can we be better prepared for the next pandemic?
Patient data collected by groups such as hospitals and health agencies is a critical tool for monitoring and preventing the spread of disease. Unfortunately, while this data contains a wealth of useful information for disease forecasting, the data itself may be highly sensitive and stored in disparate locations (e.g., across multiple hospitals, health agencies, and districts).
In this post we discuss our research on federated learning, which aims to tackle this challenge by performing decentralized learning across private data silos. We then explore an application of our research to the problem of privacy-preserving pandemic forecasting—a scenario where we recently won a 1st place, $100k prize in a competition hosted by the US & UK governments—and end by discussing several directions of future work based on our experiences.
Part 1: Privacy, personalization, and cross-silo federated learning
Federated learning (FL) is a technique to train models using decentralized data without directly communicating such data. Typically:
- a central server sends a model to participating clients;
- the clients train that model using their own local data and send back updated models; and
- the server aggregates the updates (e.g., via averaging, as in FedAvg)
and the cycle repeats. Companies like Apple and Google have deployed FL to train models for applications such as predictive keyboards, text selection, and speaker verification in networks of user devices.
However, while significant attention has been given to cross-device FL (e.g., learning across large networks of devices such as mobile phones), the area of cross-silo FL (e.g., learning across a handful of data silos such as hospitals or financial institutions) is relatively under-explored, and it presents interesting challenges in terms of how to best model federated data and mitigate privacy risks. In Part 1.1, we’ll examine a suitable privacy granularity for such settings, and in Part 1.2, we’ll see how this interfaces with model personalization, an important technique in handling data heterogeneity across clients.
1.1. How should we protect privacy in cross-silo federated learning?
Although the high-level federated learning workflow described above can help to mitigate systemic privacy risks, past work suggests that FL’s data minimization principle alone isn’t sufficient for data privacy, as the client models and updates can still reveal sensitive information.
This is where differential privacy (DP) can come in handy. DP provides both a formal guarantee and an effective empirical mitigation to attacks like membership inference and data poisoning. In a nutshell, DP is a statistical notion of privacy where we add randomness to a query on a “dataset” to create quantifiable uncertainty about whether any one “data point” has contributed to the query output. DP is typically measured by two scalars  —the smaller, the more private.
—the smaller, the more private.
In the above, “dataset” and “data point” are in quotes because privacy granularity matters. In cross-device FL, it is common to apply “client-level DP” when training a model, where the federated clients (e.g., mobile phones) are thought of as “data points”. This effectively ensures that each participating client/mobile phone user remains private.
However, while client-level DP makes sense for cross-device FL as each client naturally corresponds to a person, this privacy granularity may not be suitable for cross-silo FL, where there are fewer (2-100) ‘clients’ but each holds many data subjects that require protection, e.g., each ‘client’ may be a hospital, bank, or school with many patient, customer, or student records.
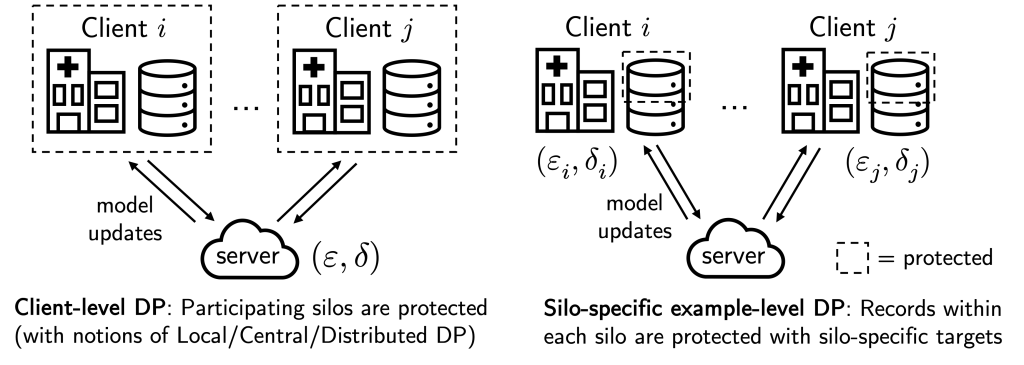
In our recent work (NeurIPS’22), we instead consider the notion of “silo-specific example-level DP” in cross-silo FL (see figure above). In short, this says that the  -th data silo may set its own
-th data silo may set its own  example-level DP target for any learning algorithm with respect to its local dataset.
example-level DP target for any learning algorithm with respect to its local dataset.
This notion is better aligned with real-world use cases of cross-silo FL, where each data subject contributes a single “example”, e.g., each patient in a hospital contributes their individual medical record. It is also very easy to implement: each silo can just run DP-SGD for local gradient steps with calibrated per-step noise. As we discuss below, this alternate privacy granularity affects how we consider modeling federated data to improve privacy/utility trade-offs.
1.2. The interplay of privacy, heterogeneity, and model personalization
Let’s now look at how this privacy granularity may interface with model personalization in federated learning.
Model personalization is a common technique used to improve model performance in FL when data heterogeneity (i.e. non-identically distributed data) exists between data silos.1 Indeed, existing benchmarks suggest that realistic federated datasets may be highly heterogeneous and that fitting separate local models on the federated data are already competitive baselines.
When considering model personalization techniques under silo-specific example-level privacy, we find that a unique trade-off may emerge between the utility costs from privacy and data heterogeneity (see figure below):
- As DP noises are added independently by each silo for its own privacy targets, these noises are reflected in the silos’ model updates and can thus be smoothed out when these updates are averaged (e.g. via FedAvg), leading to a smaller utility drop from DP for the federated model.
- On the other hand, federation also means that the shared, federated model may suffer from data heterogeneity (“one size does not fit all”).
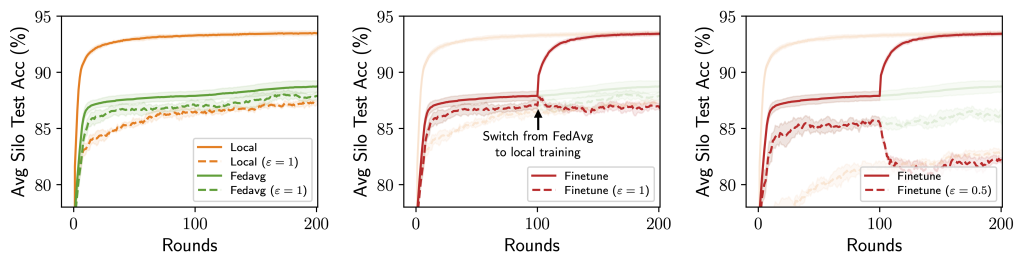
This “privacy-heterogeneity cost tradeoff” is interesting because it suggests that model personalization can play a key and distinct role in cross-silo FL. Intuitively, local training (no FL participation) and FedAvg (full FL participation) can be viewed as two ends of a personalization spectrum with identical privacy costs—silos’ participation in FL itself does not incur privacy costs due to DP’s robustness to post-processing—and various personalization algorithms (finetuning, clustering, …) are effectively navigating this spectrum in different ways.
If local training minimizes the effect of data heterogeneity but enjoys no DP noise reduction, and contrarily for FedAvg, it is natural to wonder whether there are personalization methods that lie in between and achieve better utility. If so, what methods would work best?
Our analysis points to mean-regularized multi-task learning (MR-MTL) as a simple yet particularly suitable form of personalization. MR-MTL simply asks each client to train its own local model  , regularize it towards the mean of others’ models
, regularize it towards the mean of others’ models  via a penalty
via a penalty  , and keep across rounds (i.e. client is stateful). The mean model is maintained by the FL server (as in FedAvg) and may be updated in every round. More concretely, each local update step takes the following form:
, and keep across rounds (i.e. client is stateful). The mean model is maintained by the FL server (as in FedAvg) and may be updated in every round. More concretely, each local update step takes the following form:
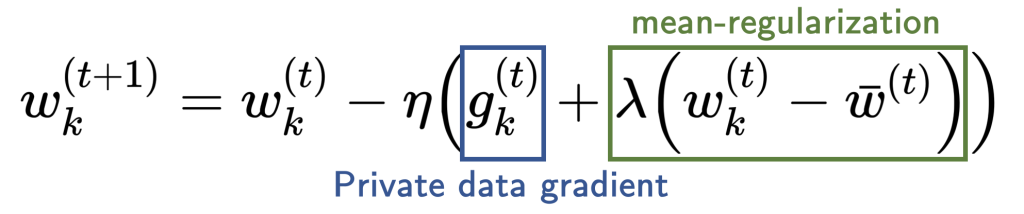
The hyperparameter  serves as a smooth knob between local training and FedAvg:
serves as a smooth knob between local training and FedAvg:  recovers local training, and a larger forces the personalized models to be closer to each other (intuitively, “federate more”).
recovers local training, and a larger forces the personalized models to be closer to each other (intuitively, “federate more”).
MR-MTL has some nice properties in the context of private cross-silo FL:
- Noise reduction is attained throughout training via the soft proximity constraint towards an averaged model;
- The mean-regularization itself has no privacy overhead;2 and
- provides a smooth interpolation along the personalization spectrum.
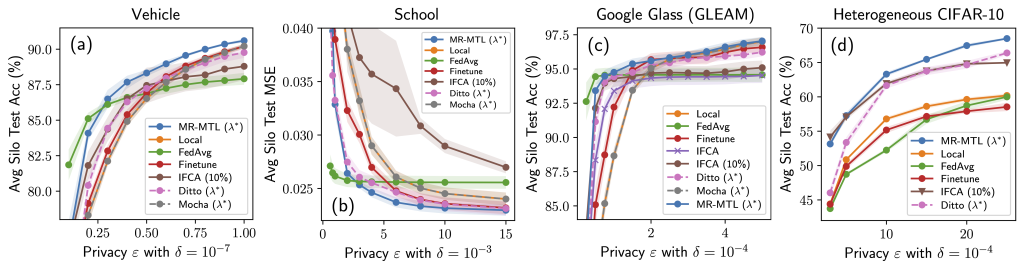
Why is the above interesting? Consider the following experiment where we try a range of values roughly interpolating local training and FedAvg. Observe that we could find a “sweet spot”  that outperforms both of the endpoints under the same privacy cost. Moreover, both the utility advantage of MR-MTL() over the endpoints, and itself, are larger under privacy; intuitively, this says that silos are encouraged to “federate more” for noise reduction.
that outperforms both of the endpoints under the same privacy cost. Moreover, both the utility advantage of MR-MTL() over the endpoints, and itself, are larger under privacy; intuitively, this says that silos are encouraged to “federate more” for noise reduction.
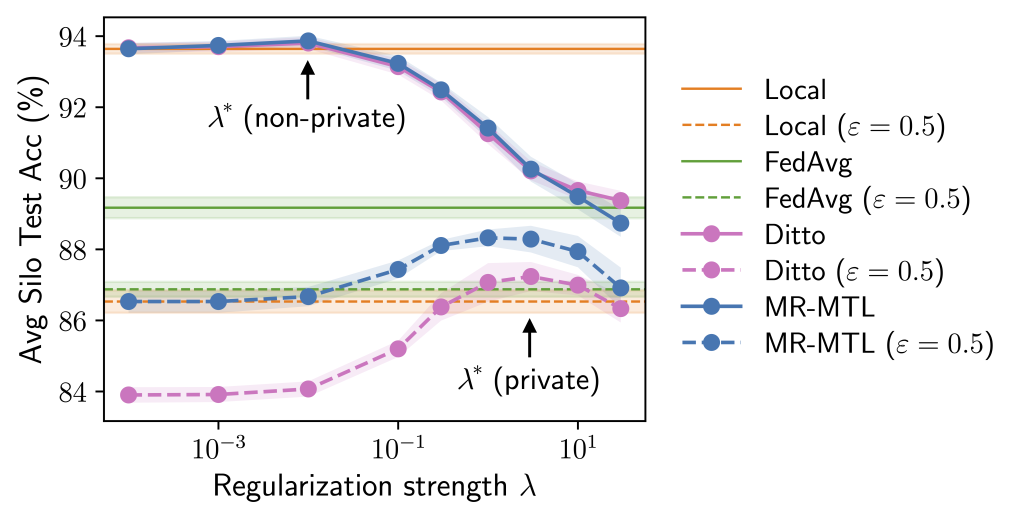
The above provides rough intuition on why MR-MTL may be a strong baseline for private cross-silo FL and motivates this approach for a practical pandemic forecasting problem, which we discuss in Part 2. Our full paper delves deeper into the analyses and provides additional results and discussions!
Part 2: Federated pandemic forecasting at the US/UK PETs challenge
Let’s now take a look at a federated pandemic forecasting problem at the US/UK Privacy-Enhancing Technologies (PETs) prize challenge, and how we may apply the ideas from Part 1.
2.1. Problem setup
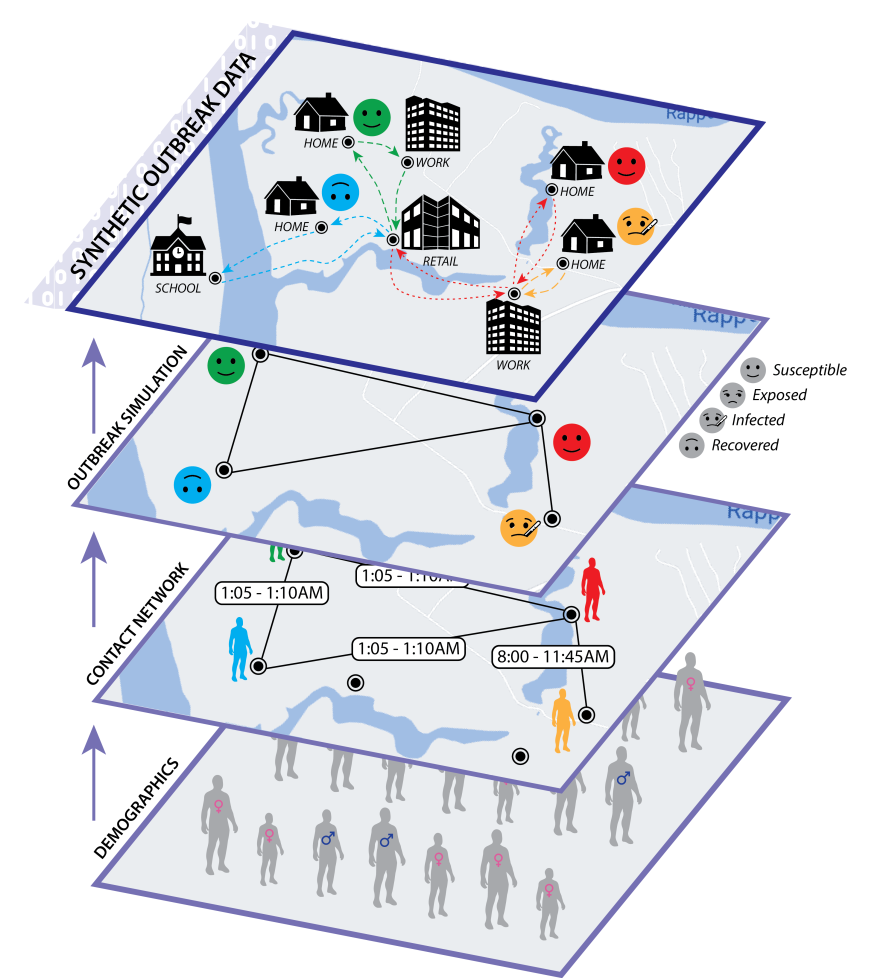
The pandemic forecasting problem asks the following: Given a person’s demographic attributes (e.g. age, household size), locations, activities, infection history, and the contact network, what is the likelihood of infection in the next  days? Can we make predictions while protecting the privacy of individuals? Moreover, what if the data are siloed across administrative regions?
days? Can we make predictions while protecting the privacy of individuals? Moreover, what if the data are siloed across administrative regions?
There’s a lot to unpack in the above. First, the pandemic outbreak problem follows a discrete-time SIR model (Susceptible → Infectious → Recovered) and we begin with a subset of the population infected. Subsequently,
- Each person goes about their usual daily activities and gets into contact with others (e.g. at a shopping mall)—this forms a contact graph where individuals are nodes and direct contacts are edges;
- Each person may get infected with different risk levels depending on a myriad of factors—their age, the nature and duration of their contact(s), their node centrality, etc.; and
- Such infection can also be asymptomatic—the individual can appear in the S state while being secretly infectious.
The challenge dataset models a pandemic outbreak in Virginia and contains roughly 7.7 million nodes (persons) and 186 million edges (contacts) with health states over 63 days; so the actual contact graph is fairly large but also quite sparse.
There are a few extra factors that make this problem challenging:
- Data imbalance: less than 5% of people are ever in the I or R state and roughly 0.3% of people became infected in the final week.
- Data silos: the true contact graph is cut along administrative boundaries, e.g., by grouped FIPS codes/counties. Each silo only sees a local subgraph, but people may still travel and make contacts across multiple regions! in In the official evaluation, the population sizes can also vary by more than 10
 across silos.
across silos. - Temporal modeling: we are given the first
 days of each person’s health states (S/I/R) and asked to predict individual infections any time in the subsequent
days of each person’s health states (S/I/R) and asked to predict individual infections any time in the subsequent  days. What is a training example in this case? How should we perform temporal partitioning? How does this relate to privacy accounting?
days. What is a training example in this case? How should we perform temporal partitioning? How does this relate to privacy accounting? - Graphs generally complicate DP: we are often used to ML settings where we can clearly define the privacy granularity and how it relates to an actual individual (e.g. medical images of patients). This is tricky with graphs: people can make different numbers of contacts each of different natures, and their influence can propagate throughout the graph. At a high level (and as specified by the scope of sensitive data of the competition), what we care about is known as node-level DP—the model output is “roughly the same” if we add/remove/replace a node, along with its edges.
2.2. Applying MR-MTL with silo-specific example-level privacy
One clean approach to the pandemic forecasting problem is to just operate on the individual level and view it as (federated) binary classification: if we could build a feature vector to summarize an individual, then risk scores are simply the sigmoid probabilities of near-term infection.
Of course, the problem lies in what that feature vector (and the corresponding label) is—we’ll get to this in the following section. But already, we can see that MR-MTL with silo-specific example-level privacy (from Part 1) is a nice framework for a number of reasons:
- Model personalization is likely needed as the silos are large and heterogeneous by construction (geographic regions are unlike to all be similar).
- Privacy definition: There are a small number of clients, but each holds many data subjects, and client-level DP isn’t suitable.
- Usability, efficiency, and scalability: MR-MTL is remarkably easy to implement with minimal resource overhead (over FedAvg and local training). This is crucial for real-world applications.
- Adaptability and explainability: The framework is highly adaptable to any learning algorithm that can take DP-SGD-style updates. It also preserves the explainability of the underlying ML algorithm as we don’t obfuscate the model weights, updates, or predictions.
It is also helpful to look at the threat model we might be dealing with and how our framework behaves under it; the interested reader may find more details in the extended post!
2.3. Building training examples
We now describe how to convert individual information and the contact network into a tabular dataset for every silo with  nodes.
nodes.
Recall that our task is to predict the risk of infection of a person within days, and that each silo only sees its local subgraph. We formulate this via a silo-specific set of examples  , where the features
, where the features  describe the neighborhood around a person
describe the neighborhood around a person  (see figure) and binary label
(see figure) and binary label  denotes if the person become infected in the next
denotes if the person become infected in the next  days.
days.
Each example’s features  consist of the following:
consist of the following:
(1) Individual features: Basic (normalized) demographic features like age, gender, and household size; activity features like working, school, going to church, or shopping; and the individual’s infection history as concatenated one-hot vectors (which depends on how we create labels; see below).
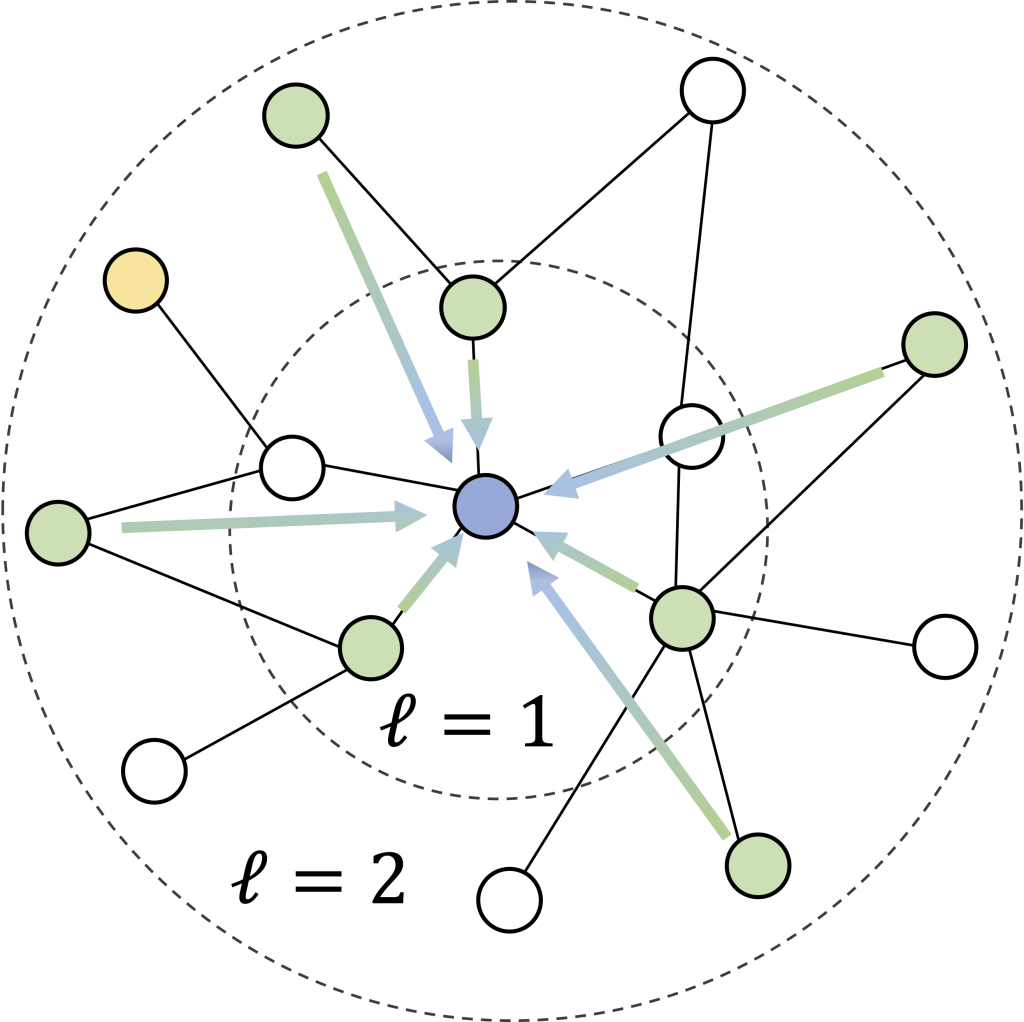
(2) Contact features: One of our key simplifying heuristics is that each node’s  -hop neighborhood should contain most of the information we need to predict infection. We build the contact features as follows:
-hop neighborhood should contain most of the information we need to predict infection. We build the contact features as follows:
- Every sampled neighbor
 of a node
of a node  is encoded using its individual features (as above) along with the edge features describing the contact—e.g. the location, the duration, and the activity type.
is encoded using its individual features (as above) along with the edge features describing the contact—e.g. the location, the duration, and the activity type. - We use iterative neighborhood sampling (figure above), meaning that we first select a set of
 1-hop neighbors, and then sample
1-hop neighbors, and then sample  2-hop neighbors adjacent to those 1-hop neighbors, and so on. This allows reusing 1-hop edge features and keeps the feature dimension
2-hop neighbors adjacent to those 1-hop neighbors, and so on. This allows reusing 1-hop edge features and keeps the feature dimension  low.
low. - We also used deterministic neighborhood sampling—the same person always takes the same subset of neighbors. This drastically reduces computation as the graph/neighborhoods can now be cached. For the interested reader, this also has implications on privacy accounting.

The figure above illustrates the neighborhood feature vector that describes a person and their contacts for the binary classifier! Intriguingly, this makes the per-silo models a simplified variant of a graph neural network (GNN) with a single-step, non-parameterized neighborhood aggregation and prediction (cf. SGC models).
For the labels  , we deployed a random infection window strategy:
, we deployed a random infection window strategy:
- Pick a window size
 (say 21 days);
(say 21 days); - Select a random day
 within the valid range (
within the valid range ( );
); - Encode the S/I/R states in the past window from for every node in the neighborhood as individual features;
- The label is then whether person is infected in any of the next days from .
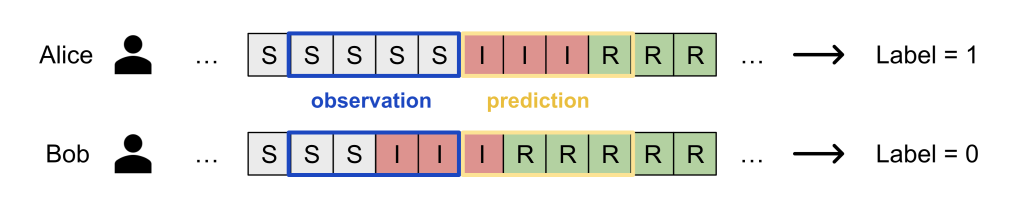
Our strategy implicitly assumes that a person’s infection risk is individual: whether Bob gets infected depends only on his own activities and contacts in the past window. This is certainly not perfect as it ignores population-level modeling (e.g. denser areas have higher risks of infection), but it makes the ML problem very simple: just plug-in existing tabular data modeling approaches!
2.4. Putting it all together
We can now see our solution coming together: each silo builds a tabular dataset using neighborhood vectors for features and infection windows for labels, and each silo trains a personalized binary classifier under MR-MTL with silo-specific example-level privacy. We complete our method with a few additional ingredients:
- Privacy accounting. We’ve so far glossed over what silo-specific “example-level” DP actually means for an individual. We’ve put more details in the extended blog post, and the main idea is that local DP-SGD can give “neighborhood-level” DP since each node’s enclosing neighborhood is fixed and unique, and we can then convert it to node-level DP (our privacy goal from Part 2.1) by carefully accounting for how a certain node may appear in other nodes’ neighborhoods.
- Noisy SGD as an empirical defense. While we have a complete framework for providing silo-specific node-level DP guarantees, for the PETs challenge specifically we decided to opt for weak DP (
 ) as an empirical protection, rather than a rigorous theoretical guarantee. While some readers may find this mildly disturbing at first glance, we note that the strength of protection depends on the data, the models, the actual threats, the desired privacy-utility trade-off, and several crucial factors linking theory and practice which we outline in the extended blog. Our solution was in turn attacked by several red teams to test for vulnerabilities.
) as an empirical protection, rather than a rigorous theoretical guarantee. While some readers may find this mildly disturbing at first glance, we note that the strength of protection depends on the data, the models, the actual threats, the desired privacy-utility trade-off, and several crucial factors linking theory and practice which we outline in the extended blog. Our solution was in turn attacked by several red teams to test for vulnerabilities. - Model architecture: simple is good. While the model design space is large, we are interested in methods amenable to gradient-based private optimization (e.g. DP-SGD) and weight-space averaging for federated learning. We compared simple logistic regression and a 3-layer MLP and found that the variance in data strongly favors linear models, which also have benefits in privacy (in terms of limited capacity for memorization) as well as explainability, efficiency, and robustness.
- Computation-utility tradeoff for neighborhood sampling. While larger neighborhood sizes
 and more hops better capture the original contact graph, they also blow up the computation and our experiments found that larger and tend to have diminishing returns.
and more hops better capture the original contact graph, they also blow up the computation and our experiments found that larger and tend to have diminishing returns. - Data imbalance and weighted loss. Because the data are highly imbalanced, training naively will suffer from low recall and AUPRC. While there are established over-/under-sampling methods to deal with such imbalance, they, unfortunately, make privacy accounting a lot trickier in terms of the subsampling assumption or the increased data queries. We leveraged the focal loss from the computer vision literature designed to emphasize hard examples (infected cases) and found that it did improve both the AUPRC and the recall considerably.
The above captures the essence of our entry to the challenge. Despite the many subtleties in fully building out a working system, the main ideas were quite simple: train personalized models with DP and add some proximity constraints!
Takeaways and open challenges
In Part 1, we reviewed our NeurIPS’22 paper that studied the application of differential privacy in cross-silo federated learning scenarios, and in Part 2, we saw how the core ideas and methods from the paper helped us develop our submission to the PETs prize challenge and win a 1st place in the pandemic forecasting track. For readers interested in more details—such as theoretical analyses, hyperparameter tuning, further experiments, and failure modes—please check out our full paper. Our work also identified several important future directions in this context:
DP under data imbalance. DP is inherently a uniform guarantee, but data imbalance implies that examples are not created equal—minority examples (e.g., disease infection, credit card fraud) are more informative, and they tend to give off (much) larger gradients during model training. Should we instead do class-specific (group-wise) DP or refine “heterogeneous DP” or “outlier DP” notions to better cater to the discrepancy between data points?
Graphs and privacy. Another fundamental basis of DP is that we could delineate what is and isn’t an individual. But as we’ve seen, the information boundaries are often nebulous when an individual is a node in a graph (think social networks and gossip propagation), particularly when the node is arbitrarily well connected. Instead of having rigid constraints (e.g., imposing a max node degree and accounting for it), are there alternative privacy definitions that offer varying degrees of protection for varying node connectedness?
Scalable, private, and federated trees for tabular data. Decision trees/forests tend to work extremely well for tabular data such as ours, even with data imbalance, but despite recent progress, we argue that they are not yet mature under private and federated settings due to some underlying assumptions.
Novel training frameworks. While MR-MTL is a simple and strong baseline under our privacy granularity, it has clear limitations in terms of modeling capacity. Are there other methods that can also provide similar properties to balance the emerging privacy-heterogeneity cost tradeoff?
Honest privacy cost of hyperparameter search. When searching for better frameworks, the dependence on hyperparameters is particularly interesting: our full paper (section 7) made a surprising but somewhat depressing observation that the honest privacy cost of just tuning (on average) 10 configurations (values of in this case) may already outweigh the utility advantage of the best tune MR-MTL(). What does this mean if MR-MTL is already a strong baseline with just a single hyperparameter?
Check out the following related links:
- Extended version of this blog with more technical details
- Part 1: Our NeurIPS’22 paper and poster
- Part 2: The US/UK Privacy-Enhancing Technologies (PETs) Prize Challenge
- Team profile
- Open-source release
- Description: challenge main page, technical brief of the federated pandemic forecasting problem
- News coverage: DrivenData, CMU, White House, NSF, UK Gov
DISCLAIMER: All opinions expressed in this post are those of the authors and do not represent the views of CMU.
Footnotes
. However, tuning as a hyperparameter can incur privacy cost. This article was initially published on the ML@CMU blog and appears here with the authors’ permission.
tags: deep dive

AUAI is supported by:








