
ΑΙhub.org
On noisy evaluation in federated hyperparameter tuning
Evaluating models in federated networks is challenging due to factors such as client subsampling, data heterogeneity, and privacy. These factors introduce noise that can affect hyperparameter tuning algorithms and lead to suboptimal model selection.
By Kevin Kuo
Hyperparameter tuning is critical to the success of cross-device federated learning applications. Unfortunately, federated networks face issues of scale, heterogeneity, and privacy, which introduce noise in the tuning process and make it difficult to faithfully evaluate the performance of various hyperparameters. Our work (MLSys’23) explores key sources of noise and surprisingly shows that even small amounts of noise can have a significant impact on tuning methods—reducing the performance of state-of-the-art approaches to that of naive baselines. To address noisy evaluation in such scenarios, we propose a simple and effective approach that leverages public proxy data to boost the evaluation signal. Our work establishes general challenges, baselines, and best practices for future work in federated hyperparameter tuning.
Federated learning: An overview

Cross-device federated learning (FL) is a machine learning setting that considers training a model over a large heterogeneous network of devices such as mobile phones or wearables. Three key factors differentiate FL from traditional centralized learning and distributed learning:
Scale. Cross-device refers to FL settings with many clients with potentially limited local resources e.g. training a language model across hundreds to millions of mobile phones. These devices have various resource constraints, such as limited upload speed, number of local examples, or computational capability.
Heterogeneity. Traditional distributed ML assumes each worker/client has a random (identically distributed) sample of the training data. In contrast, in FL client datasets may be non-identically distributed, with each user’s data being generated by a distinct underlying distribution.
Privacy. FL offers a baseline level of privacy since raw user data remains local on each client. However, FL is still vulnerable to post-hoc attacks where the public output of the FL algorithm (e.g. a model or its hyperparameters) can be reverse-engineered and leak private user information. A common approach to mitigate such vulnerabilities is to use differential privacy, which aims to mask the contribution of each client. However, differential privacy introduces noise in the aggregate evaluation signal, which can make it difficult to effectively select models.
Federated hyperparameter tuning
Appropriately selecting hyperparameters (HPs) is critical to training quality models in FL. Hyperparameters are user-specified parameters that dictate the process of model training such as the learning rate, local batch size, and number of clients sampled at each round. The problem of tuning HPs is general to machine learning (not just FL). Given an HP search space and search budget, HP tuning methods aim to find a configuration in the search space that optimizes some measure of quality within a constrained budget.
Let’s first look at an end-to-end FL pipeline that considers both the processes of training and hyperparameter tuning. In cross-device FL, we split the clients into two pools for training and validation. Given a hyperparameter configuration  , we train a model using the training clients (explained in section “FL Training”). We then evaluate this model on the validation clients, obtaining an error rate/accuracy metric. We can then use the error rate to adjust the hyperparameters and train a new model.
, we train a model using the training clients (explained in section “FL Training”). We then evaluate this model on the validation clients, obtaining an error rate/accuracy metric. We can then use the error rate to adjust the hyperparameters and train a new model.
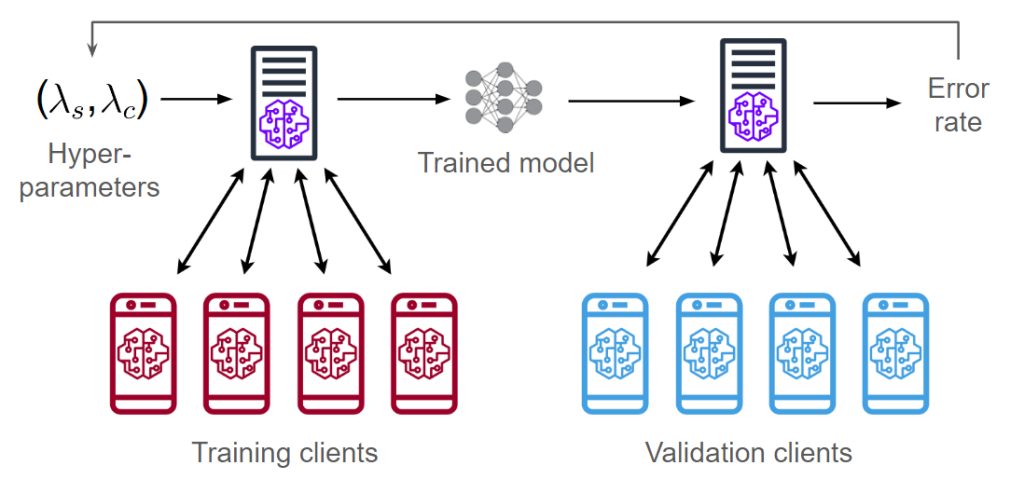
The diagram above shows two vectors of hyperparameters  . These correspond to the hyperparameters of two optimizers: one is server-side and the other is client-side. Next, we describe how these hyperparameters are used during FL training.
. These correspond to the hyperparameters of two optimizers: one is server-side and the other is client-side. Next, we describe how these hyperparameters are used during FL training.
FL training
A typical FL algorithm consists of several rounds of training where each client performs local training followed by aggregation of the client updates. In our work, we experiment with a general framework called FedOPT which was presented in Adaptive Federated Optimization (Reddi et al. 2021). We outline the per-round procedure of FedOPT below:
- The server broadcasts the model
 to a sampled subset of
to a sampled subset of  clients.
clients. - Each client (in parallel) trains on their local data
 using
using ClientOPTand obtains an updated model .
. - Each client sends back to the server.
- The server averages all the received models
 .
. - To update , the server computes the difference
 and feeds it as a pseudo-gradient into
and feeds it as a pseudo-gradient into ServerOPT(rather than computing a gradient w.r.t. some loss function).
 ) we consider tuning. (Source: edited from Wikipedia)
) we consider tuning. (Source: edited from Wikipedia)Steps 2 and 5 of FedOPT each require a gradient-based optimization algorithm (called ClientOPT and ServerOPT) which specify how to update given some update vector. In our work, we focus on an instantiation of FedOPT called FedAdam, which uses Adam (Kingma and Ba 2014) as ServerOPT and SGD as ClientOPT. We focus on tuning five FedAdam hyperparameters: two for client training (SGD’s learning rate and batch size) and three for server aggregation (Adam’s learning rate, 1st-moment decay, and 2nd-moment decay).
FL evaluation
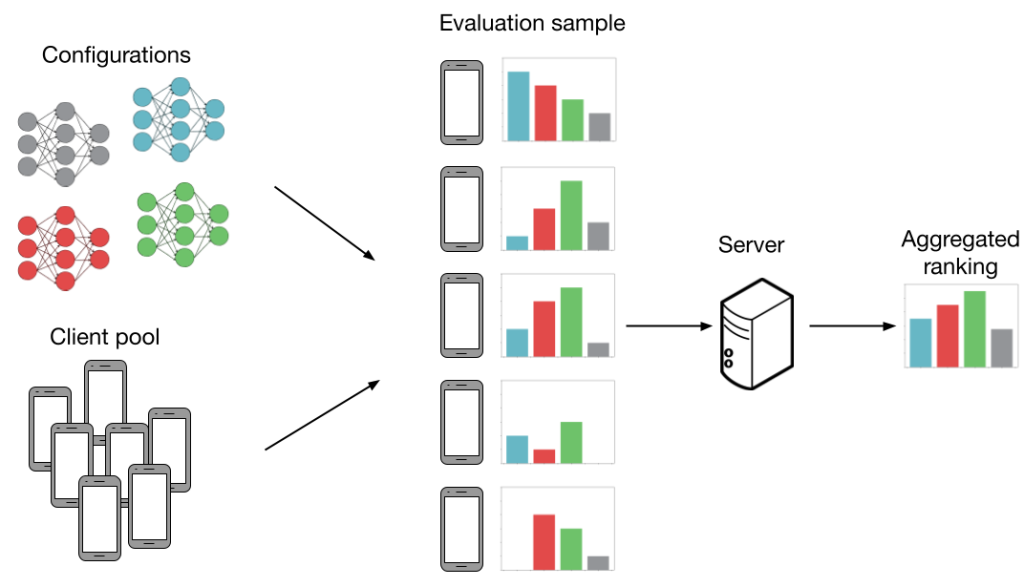
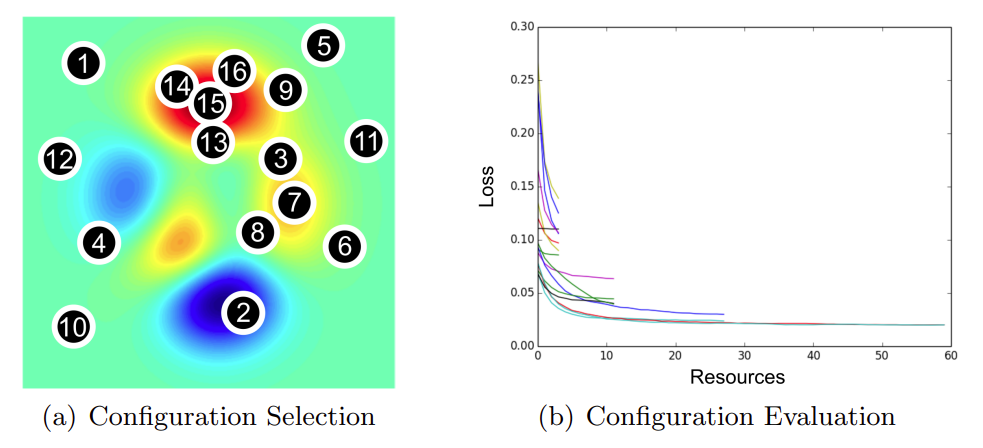
Now, we discuss how FL settings introduce noise to model evaluation. Consider the following example below. We have  configurations (grey, blue, red, green) and we want to figure out which configuration has the best average accuracy across
configurations (grey, blue, red, green) and we want to figure out which configuration has the best average accuracy across  clients. More specifically, each “configuration” is a set of HP values (learning rate, batch size, etc.) that are fed into an FL training algorithm (more details in the next section). This produces a model we can evaluate. If we can evaluate every model on every client then our evaluation is noiseless. In this case, we would be able to accurately determine that the green model performs the best. However, generating all the evaluations as shown below is not practical, as evaluation costs scale with both the number of configurations and clients.
clients. More specifically, each “configuration” is a set of HP values (learning rate, batch size, etc.) that are fed into an FL training algorithm (more details in the next section). This produces a model we can evaluate. If we can evaluate every model on every client then our evaluation is noiseless. In this case, we would be able to accurately determine that the green model performs the best. However, generating all the evaluations as shown below is not practical, as evaluation costs scale with both the number of configurations and clients.
Below, we show an evaluation procedure that is more realistic in FL. As the primary challenge in cross-device FL is scale, we evaluate models using only a random subsample of clients. This is shown in the figure by red ‘X’s and shaded-out phones. We cover three additional sources of noise in FL which can negatively interact with subsampling and introduce even more noise into the evaluation procedure:
Data heterogeneity. FL clients may have non-identically distributed data, meaning that the evaluations on various models can differ between clients. This is shown by the different histograms next to each client. Data heterogeneity is intrinsic to FL and is critical for our observations on noisy evaluation; if all clients had identical datasets, there would be no need to sample more than one client.
Systems heterogeneity. In addition to data heterogeneity, clients may have heterogeneous system capabilities. For example, some clients have better network reception and computational hardware, which allows them to participate in training and evaluation more frequently. This biases performance towards these clients, leading to a poor overall model.
Differential privacy. Using the evaluation output (i.e. the top-performing model), a malicious party can infer whether or not a particular client participated in the FL procedure. At a high level, differential privacy aims to mask user contributions by adding noise to the aggregate evaluation metric. However, this additional noise can make it difficult to faithfully evaluate HP configurations.
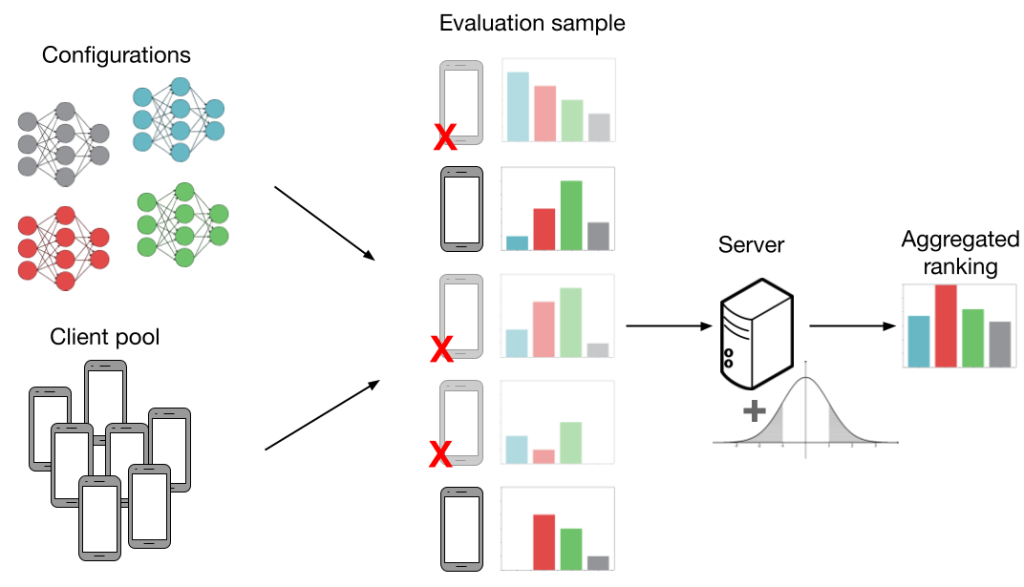
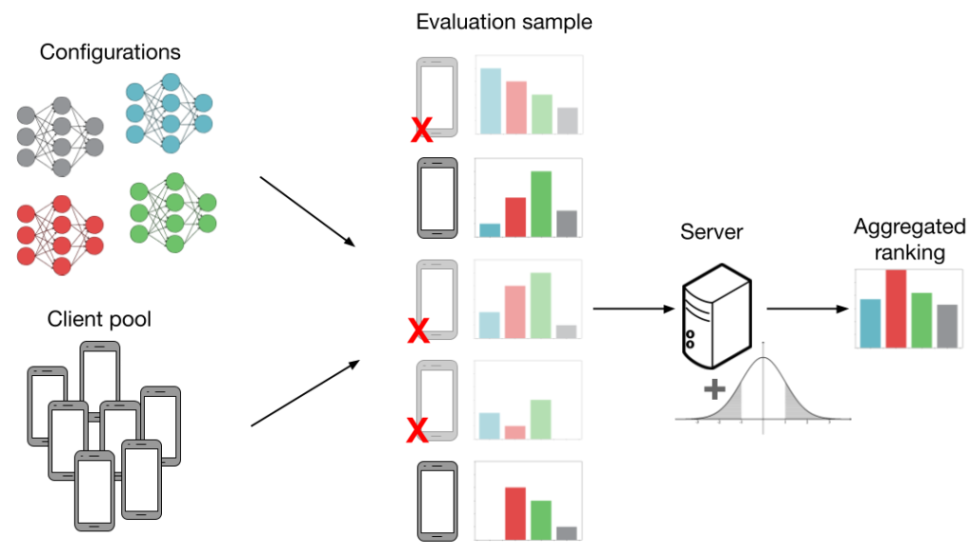
In the figure above, evaluations can lead to suboptimal model selection when we consider client subsampling, data heterogeneity, and differential privacy. The combination of all these factors leads us to incorrectly choose the red model over the green one.
Experimental results
The first goal of our work is to investigate the impact of four sources of noisy evaluation that we outlined in the section “FL Evaluation”. In more detail, these are our research questions:
- How does subsampling validation clients affect HP tuning performance?
- How do the following factors interact with/exacerbate issues of subsampling?
- data heterogeneity (shuffling validation clients’ datasets)
- systems heterogeneity (biased client subsampling)
- privacy (adding Laplace noise to the aggregate evaluation)
- In noisy settings, how do SOTA methods compare to simple baselines?
Surprisingly, we show that state-of-the-art HP tuning methods can perform catastrophically poorly, even worse than simple baselines (e.g., random search). While we only show results for CIFAR10, results on three other datasets (FEMNIST, StackOverflow, and Reddit) can be found in our paper. CIFAR10 is partitioned such that each client has at most two out of the ten total labels.
Noise hurts random search
This section investigates questions 1 and 2 using random search (RS) as the hyperparameter tuning method. RS is a simple baseline that randomly samples several HP configurations, trains a model for each one, and returns the highest-performing model (i.e. the example in “FL Evaluation”, if the configurations were sampled independently from the same distribution). Generally, each hyperparameter value is sampled from a (log) uniform or normal distribution.
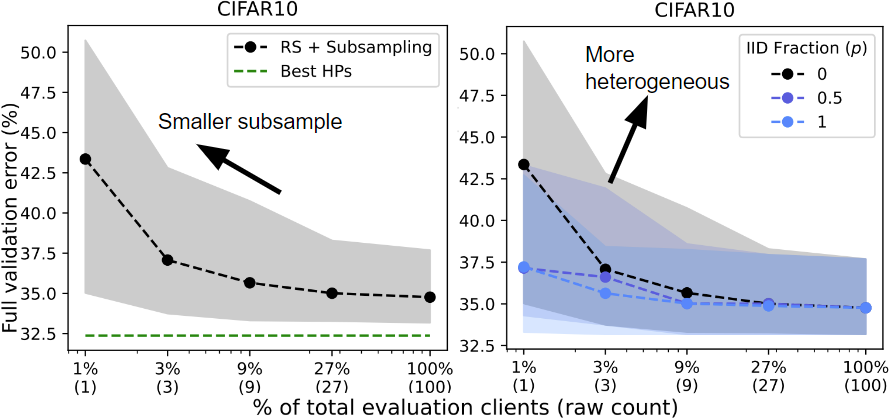
Client subsampling. We run RS while varying the client subsampling rate from a single client to the full validation client pool. “Best HPs” indicates the best HPs found across all trials of RS. As we subsample less clients (left), random search performs worse (higher error rate).
Data heterogeneity. We run RS on three separate validation partitions with varying degrees of data heterogeneity based on the label distributions on each client. Client subsampling generally harms performance but has a greater impact on performance when the data is heterogeneous (IID Fraction = 0 vs. 1).
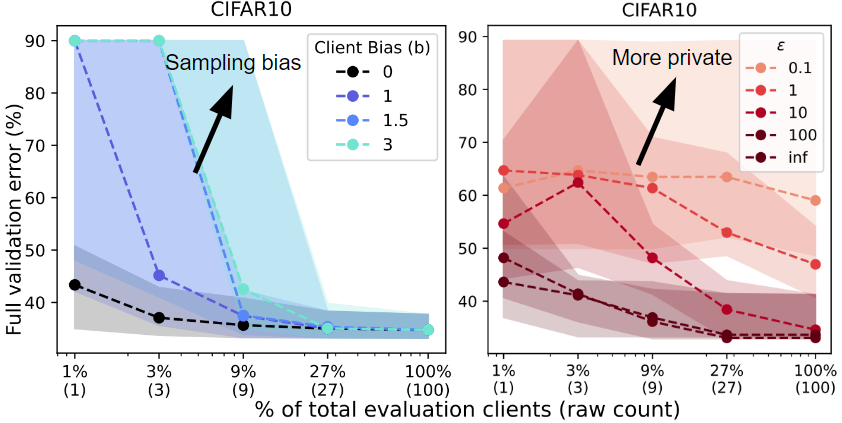
Systems heterogeneity. We run RS and bias the client sampling to reflect four degrees of systems heterogeneity. Based on the model that is currently being evaluated, we assign a higher probability of sampling clients who perform well on this model. Sampling bias leads to worse performance since the biased evaluations are overly optimistic and do not reflect performance over the entire validation pool.
Privacy. We run RS with 5 different evaluation privacy budgets  . We add noise sampled from
. We add noise sampled from  to the aggregate evaluation, where
to the aggregate evaluation, where  is the number of evaluations (16), is the privacy budget (each curve), and
is the number of evaluations (16), is the privacy budget (each curve), and  is the number of clients sampled for an evaluation (x-axis). A smaller privacy budget requires sampling a larger raw number of clients to achieve reasonable performance.
is the number of clients sampled for an evaluation (x-axis). A smaller privacy budget requires sampling a larger raw number of clients to achieve reasonable performance.
Noise hurts complex methods more than RS
Seeing that noise adversely affects random search, we now focus on question 3: Do the same observations hold for more complex tuning methods? In the next experiment, we compare 4 representative HP tuning methods.
- Random Search (RS) is a naive baseline.
- Tree-Structured Parzen Estimator (TPE) is a selection-based method. These methods build a surrogate model that predicts the performance of various hyperparameters rather than predictions for the task at hand (e.g. image or language data).
- Hyperband (HB) is an allocation-based method. These methods allocate more resources to the most promising configurations. Hyperband initially samples a large number of configurations but stops training most of them after the first few rounds.
- Bayesian Optimization + Hyperband (BOHB) is a combined method that uses both the sampling strategy of TPE and the partial evaluations of HB.
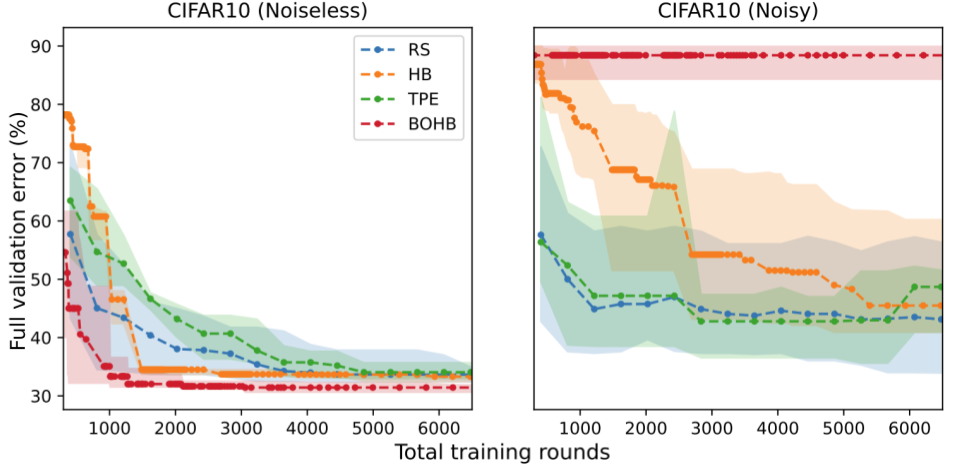
We report the error rate of each HP tuning method (y-axis) at a given budget of rounds (x-axis). Surprisingly, we find that the relative ranking of these methods can be reversed when the evaluation is noisy. With noise, the performance of all methods degrades, but the degradation is particularly extreme for HB and BOHB. Intuitively, this is because these two methods already inject noise into the HP tuning procedure via early stopping which interacts poorly with additional sources of noise. Therefore, these results indicate a need for HP tuning methods that are specialized for FL, as many of the guiding principles for traditional hyperparameter tuning may not be effective at handling noisy evaluation in FL.
 .
.Proxy evaluation outperforms noisy evaluation
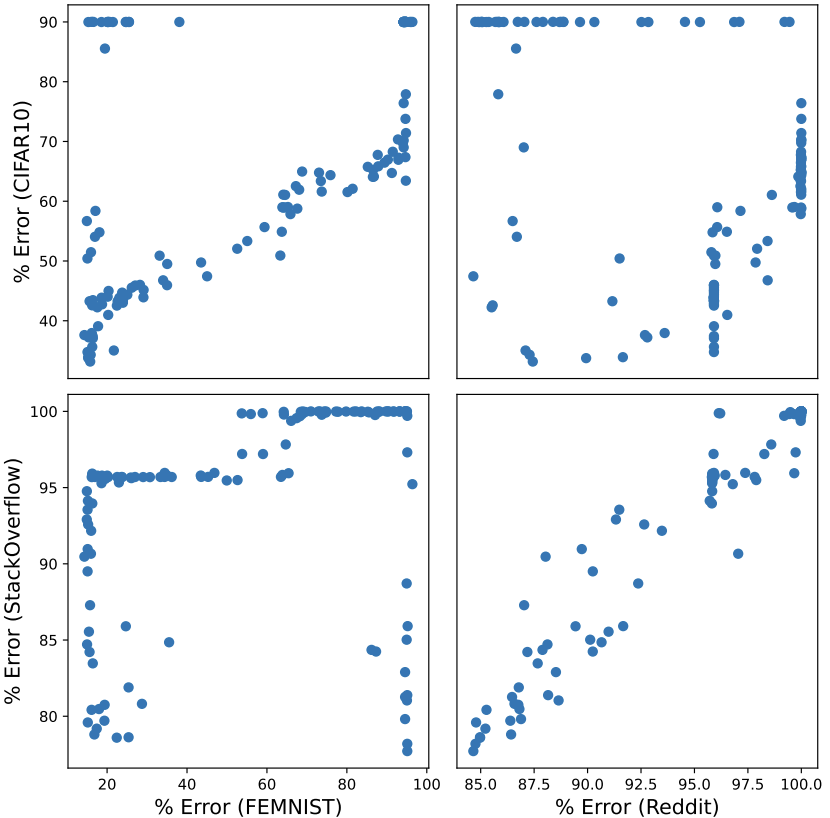
In practical FL settings, a practitioner may have access to public proxy data which can be used to train models and select hyperparameters. However, given two distinct datasets, it is unclear how well hyperparameters can transfer between them. First, we explore the effectiveness of hyperparameter transfer between four datasets. Below, we see that the CIFAR10-FEMNIST and StackOverflow-Reddit pairs (top left, bottom right) show the clearest transfer between the two datasets. One likely reason for this is that these task pairs use the same model architecture: CIFAR10 and FEMNIST are both image classification tasks while StackOverflow and Reddit are next-word prediction tasks.
Given the appropriate proxy dataset, we show that a simple method called one-shot proxy random search can perform extremely well. The algorithm has two steps:
- Run a random search using the proxy data to both train and evaluate HPs. We assume the proxy data is both public and server-side, so we can always evaluate HPs without subsampling clients or adding privacy noise.
- The output configuration from 1. is used to train a model on the training client data. Since we pass only a single configuration to this step, validation client data does not affect hyperparameter selection at all.
In each experiment, we choose one of these datasets to be partitioned among the clients and use the other three datasets as server-side proxy datasets. Our results show that proxy data can be an effective solution. Even if the proxy dataset is not an ideal match for the public data, it may be the only available solution under a strict privacy budget. This is shown in the FEMNIST plot where the orange/red lines (text datasets) perform similarly to the  curve.
curve.
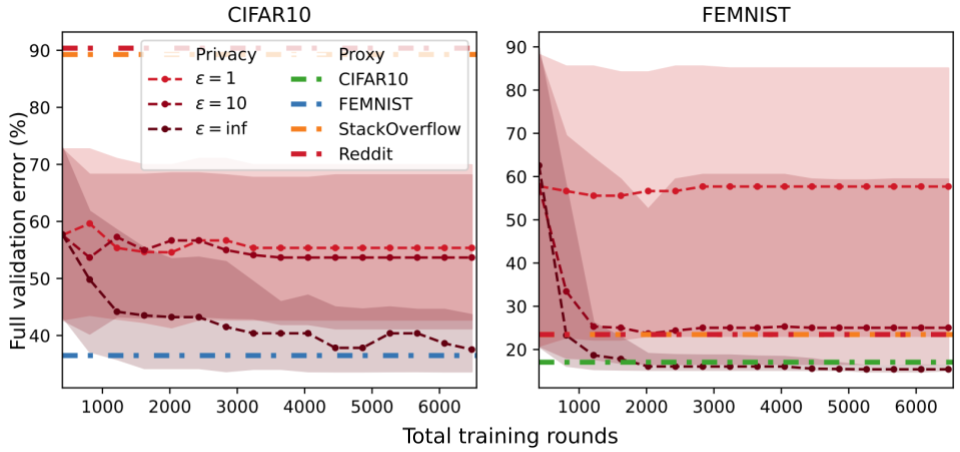 versus noiseless evaluations on the proxy dataset. The proxy HP tuning methods appear as horizontal lines because they are one-shot.
versus noiseless evaluations on the proxy dataset. The proxy HP tuning methods appear as horizontal lines because they are one-shot.Conclusion
In conclusion, our study suggests several best practices for federated HP tuning:
- Use simple HP tuning methods.
- Sample a sufficiently large number of validation clients.
- Evaluate a representative set of clients.
- If available, proxy data can be an effective solution.
Furthermore, we identify several directions for future work in federated HP tuning:
- Tailoring HP tuning methods for differential privacy and FL. Early stopping methods are inherently noisy/biased and the large number of evaluations they use is at odds with privacy. Another useful direction is to investigate HP methods specific to noisy evaluation.
- More detailed cost evaluation. In our work, we only considered the number of training rounds as our resource budget. However, practical FL settings consider a wide variety of costs, such as total communication, amount of local training, or total time to train a model.
- Combining proxy and client data for HP tuning. A key issue of using public proxy data for HP tuning is that the best proxy dataset is not known in advance. One direction to address this is to design methods that combine public and private evaluations to mitigate bias from proxy data and noise from private data. Another promising direction is to rely on the abundance of public data and design a method that can select the best proxy dataset.
This article was initially published on the ML@CMU blog and appears here with the authors’ permission.
tags: deep dive

AUAI is supported by:








