
ΑΙhub.org
Beyond the mud: Datasets, benchmarks, and methods for computer vision in off-road racing

By Jacob Tyo
TL;DR: Off-the-shelf text spotting and re-identification models fail in basic off-road racing settings, even more so during muddy events. Making matters worse, there aren’t any public datasets to evaluate or improve models in this domain. To this end, we introduce datasets, benchmarks, and methods for the challenging off-road racing setting.
In the dynamic world of sports analytics, machine learning (ML) systems play a pivotal role, transforming vast arrays of visual data into actionable insights. These systems are adept at navigating through thousands of photos to tag athletes, enabling fans and participants alike to swiftly locate images of specific racers or moments from events. This technology has seamlessly integrated into various sports, significantly enhancing the spectator experience and operational efficiency. Yet, not all sports environments cater equally to the capabilities of current ML models. Off-road motorcycle racing, characterized by its unpredictable and untamed wilderness settings, poses unique challenges that push the boundaries of what existing computer vision systems can handle.
Imagine the conditions under which off-road races are conducted: racers blitz through waist-deep mud holes, endure torrential rains, navigate through blinding dust clouds, and much more. Such extreme environmental factors introduce variables like mud occlusion, complex poses (racers frequently crash), glare, motion blur, and variable lighting conditions, which significantly degrade the performance of conventional text spotting and person re-identification (ReID) models. Typical models, trained on more ‘sterile’ conditions, falter when faced with the task of identifying racers and their numbers in the chaotic and mud-splattered scenes typical of off-road racing events. Take, for example, these images of the same racer, taken only minutes apart:

The lack of public datasets tailored to these rugged conditions exacerbates the problem, leaving researchers and practitioners without the resources needed to evaluate and enhance models for better performance in off-road racing, or equally unconstrained, scenarios. Recognizing this gap, our work aims to bridge it by introducing new datasets and benchmarks specifically designed for the challenging setting of off-road motorcycle racing. This blog post will delve into the unique challenges presented by off-road racing environments, describe our efforts in creating datasets that capture these conditions, and discuss methods and benchmarks for improving computer vision models to robustly handle the extreme variability inherent in off-road racing. I’ll even give a brief overview of some new weakly supervised methods for improving models in these challenging areas, with very little labeled data. Join in as we explore the uncharted territories of machine learning applications in off-road motorcycle racing, pushing the limits of what’s possible in sports analytics and beyond.
The challenges

Off-road motorcycle racing is an adrenaline-pumping sport that takes athletes and their machines through some of the most challenging terrains nature has to offer. Unlike the relatively predictable environments of track racing or urban marathons, off-road racing is fraught with unpredictability and extreme conditions. The very essence of what makes it thrilling for participants and spectators alike—mud, dust, water, uneven terrain—presents a formidable challenge for computer vision systems. Here, we delve into the specific hurdles that these conditions pose for text spotting and re-identification models in off-road racing scenarios.
Dirt is pervasive in off-road racing, manifesting itself as mud or dust. As races progress, vehicles and riders become increasingly coated in dirt, which can obscure critical identifying features such as racer numbers or distinguishing gear colors. The dynamic nature of off-road racing means that athletes are rarely in simple, upright poses. Instead, they navigate the course through jumps, sharp turns, and even crashes. The outdoor settings of off-road races often move rapidly from deep dark forests to bright glaring fields, thus introducing variable lighting conditions. Similarly, the high speeds at which racers move combined with the stylistic choices of some photographers can lead to motion blur. In each of these cases, traditional optical character recognition (OCR) and re-identification (ReID) models, trained primarily on clean, unobstructed images, struggle to recognize text or identify individuals.
The datasets and initial benchmarks
To tackle the formidable challenges presented by off-road motorcycle racing, we embarked on a mission to create datasets that accurately capture the essence and extremities of this sport. Recognizing the gap in existing computer vision resources, our datasets—off-road Racer Number Dataset (RND) and MUddy Racer re-iDentification Dataset (MUDD)—are meticulously curated to serve as a robust foundation for developing and benchmarking models capable of operating in the harsh, unpredictable conditions of off-road racing. These datasets, as well as benchmarking code, are publically available for both of these datasets. You can find RND here and MUDD here.
Figure 3 details the text spotting results on the RND dataset. Results are broken down by the various types of occlusion in the dataset. Even on the cleanest data (i.e. the data with no occlusion), the best fine-tuned models reach a maximum E2E F1 score of 0.6, leaving a lot to be desired. Introducing any of the aforementioned challenges (i.e.) reduces this even further, down to the worse end-to-end F1 score of 0.29. The models tested were the Yet Another Mask Text Spotter (YAMTS) and Swin Text Spotter, and YAMTS was consistently the best performing. Fine-tuning reduces the negative effect of the various occlusion types (i.e. the blue bar changes less as a percentage of performance than the orange across the various occlusions), yet occlusion still causes significant performance degradation.
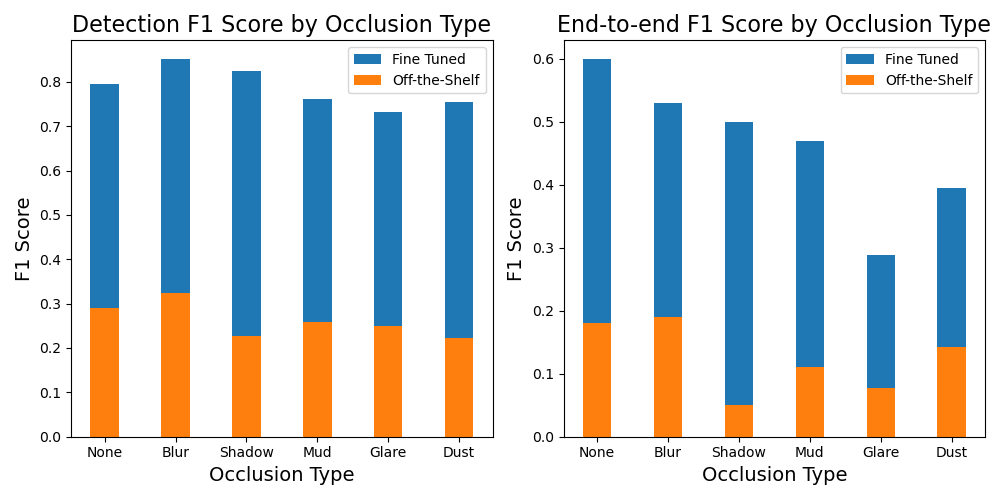
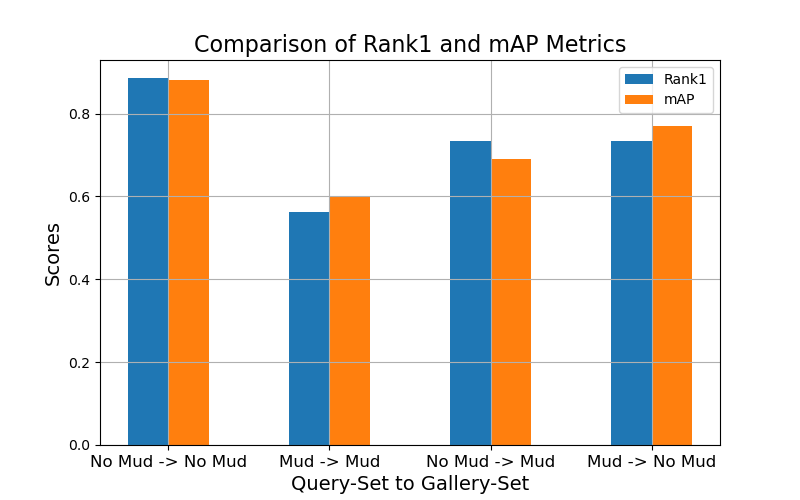
Figure 4 breaks down the performance of our best ReID models. In the standard ReID evaluation setting, a sample from a query set is used to return a ranking over a gallery set. We report the rank1 accuracy along with the mean average precision (mAP). Figure 2 looks at two variations of the query and gallery sets, one query set of all the muddy images, and one without, and the same for the gallery set. In the simplest setting (No Mud -> No Mud), model performance is getting reasonably good, around 0.9 mAP. However, mud drops this performance by as much as 30%. The models tested were the Omni-Scale Network (OSNet) and Resnet 50. Figure 4 reports results from OSNet as it was the most performant.
In summary, the off-road racing setting is difficult, even in the best case. Once dirt and mud enter the equation, models require advancement before they reach the threshold of usability in a real-world application.
Improving these systems
A “mud-like” data augmentation

The first step in building robustness to mud is to introduce a data augmentation strategy: speckling. As shown in previous examples, mud often accumulates in small chunks. To emulate this, we introduce speckling, where we randomly change many small patches of the input imagery into the pixel mean. This is similar to random erasing but at a much smaller scale with a large number of patches being erased in each image. This technique leads to a 4% improvement in Rank-1 accuracy for person re-identification on the MUDD dataset, and while it does not meaningfully affect the detection F1 score of text spotting on RND, it does improve the end-to-end F1 score by 7%. While we also use the standard color jitter data augmentation to help robustness to the color changes induced as a racer gets dirty, more research is needed to determine if a more specific color augmentation can prove useful.
Learning from weak labels
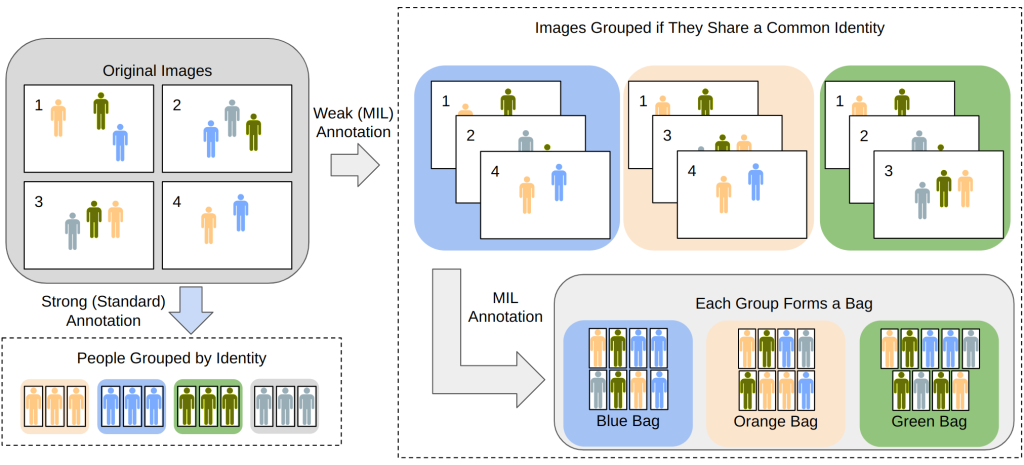
Another intricacy of sports imagery that we can take advantage of is the natural groupings that often exist. For example, prior marathon imagery has been manually grouped by humans, such that each group (which we will refer to as a bag) consists of images that all contain a specific individual. However, which specific individual is the one of interest in each image is unknown. In motorcycle racing, we have the same data, as well as customer purchase history. Most customers purchase photos of a single racer, therefore the list of purchased photos again becomes a bag of a specific individual, although which individuals in the image is unknown. This type of label is visualized in Figure 4.
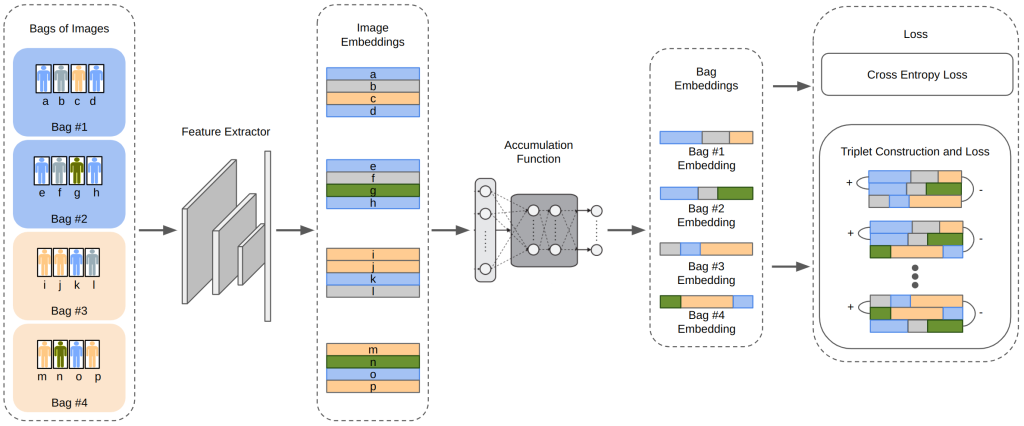
We introduce Contrastive Multiple Instance Learning (CMIL) to address this challenge. This method works by generating bag representations from all of the instance representations that comprise that bag. Then, the bag representations are used to optimize a model via triplet loss or classification loss. In other words, we optimize the model to accurately classify bags, not individuals. This does not align with our test time goal, however, of classifying individuals. But surprisingly, our bag classification models naturally generate useful individual representations. Figure 5 gives an overview of the CMIL model. On the MUDD dataset, CMIL improves over the next-best weakly labeled person re-identification methodology by 4% rank-1 accuracy, and over a model that trusts the bag-level labels to be accurate person-level labels by over 20%.
Conclusion
Off-road racing poses major challenges to existing text spotting and person re-identification methods and models, rendering them unfit for practical application. Our first steps at improving computer performance in these areas include introducing two datasets for the corresponding problems, introducing a new data augmentation technique, and bringing contrastive learning to the multiple instance learning framework. We hope that these initial works spur more innovation in off-road applications.
For more information, you can find the papers and code this blog post is based on here:
– Beyond the Mud: Datasets and Benchmarks for Computer Vision in Off-Road Racing (code)
– Contrastive Multiple Instance Learning for Weakly Supervised Person ReID (code)
This article was initially published on the ML@CMU blog and appears here with the authors’ permission.
tags: deep dive

AUAI is supported by:








