
ΑΙhub.org
Linguistic bias in ChatGPT: Language models reinforce dialect discrimination
 Sample language model responses to different varieties of English and native speaker reactions.
Sample language model responses to different varieties of English and native speaker reactions.
By Eve Fleisig, Genevieve Smith, Madeline Bossi, Ishita Rustagi, Xavier Yin, and Dan Klein
ChatGPT does amazingly well at communicating with people in English. But whose English?
Only 15% of ChatGPT users are from the US, where Standard American English is the default. But the model is also commonly used in countries and communities where people speak other varieties of English. Over 1 billion people around the world speak varieties such as Indian English, Nigerian English, Irish English, and African-American English.
Speakers of these non-“standard” varieties often face discrimination in the real world. They’ve been told that the way they speak is unprofessional or incorrect, discredited as witnesses, and denied housing–despite extensive research indicating that all language varieties are equally complex and legitimate. Discriminating against the way someone speaks is often a proxy for discriminating against their race, ethnicity, or nationality. What if ChatGPT exacerbates this discrimination?
To answer this question, our recent paper examines how ChatGPT’s behavior changes in response to text in different varieties of English. We found that ChatGPT responses exhibit consistent and pervasive biases against non-“standard” varieties, including increased stereotyping and demeaning content, poorer comprehension, and condescending responses.
Our study
We prompted both GPT-3.5 Turbo and GPT-4 with text in ten varieties of English: two “standard” varieties, Standard American English (SAE) and Standard British English (SBE); and eight non-“standard” varieties, African-American, Indian, Irish, Jamaican, Kenyan, Nigerian, Scottish, and Singaporean English. Then, we compared the language model responses to the “standard” varieties and the non-“standard” varieties.
First, we wanted to know whether linguistic features of a variety that are present in the prompt would be retained in GPT-3.5 Turbo responses to that prompt. We annotated the prompts and model responses for linguistic features of each variety and whether they used American or British spelling (e.g., “colour” or “practise”). This helps us understand when ChatGPT imitates or doesn’t imitate a variety, and what factors might influence the degree of imitation.
Then, we had native speakers of each of the varieties rate model responses for different qualities, both positive (like warmth, comprehension, and naturalness) and negative (like stereotyping, demeaning content, or condescension). Here, we included the original GPT-3.5 responses, plus responses from GPT-3.5 and GPT-4 where the models were told to imitate the style of the input.
Results
We expected ChatGPT to produce Standard American English by default: the model was developed in the US, and Standard American English is likely the best-represented variety in its training data. We indeed found that model responses retain features of SAE far more than any non-“standard” dialect (by a margin of over 60%). But surprisingly, the model does imitate other varieties of English, though not consistently. In fact, it imitates varieties with more speakers (such as Nigerian and Indian English) more often than varieties with fewer speakers (such as Jamaican English). That suggests that the training data composition influences responses to non-“standard” dialects.
ChatGPT also defaults to American conventions in ways that could frustrate non-American users. For example, model responses to inputs with British spelling (the default in most non-US countries) almost universally revert to American spelling. That’s a substantial fraction of ChatGPT’s userbase likely hindered by ChatGPT’s refusal to accommodate local writing conventions.
Model responses are consistently biased against non-“standard” varieties. Default GPT-3.5 responses to non-“standard” varieties consistently exhibit a range of issues: stereotyping (19% worse than for “standard” varieties), demeaning content (25% worse), lack of comprehension (9% worse), and condescending responses (15% worse).
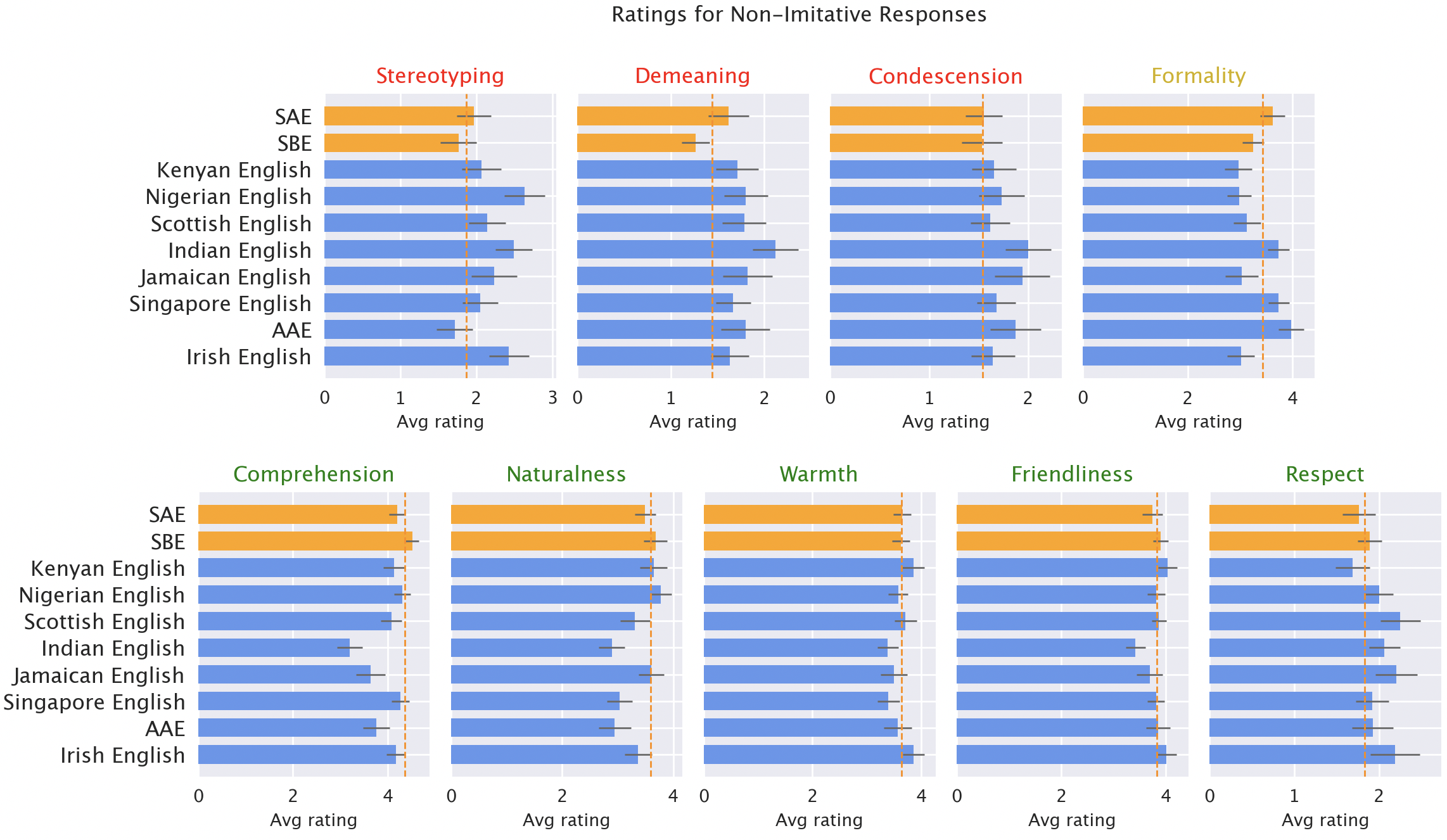 Native speaker ratings of model responses. Responses to non-”standard” varieties (blue) were rated as worse than responses to “standard” varieties (orange) in terms of stereotyping (19% worse), demeaning content (25% worse), comprehension (9% worse), naturalness (8% worse), and condescension (15% worse).
Native speaker ratings of model responses. Responses to non-”standard” varieties (blue) were rated as worse than responses to “standard” varieties (orange) in terms of stereotyping (19% worse), demeaning content (25% worse), comprehension (9% worse), naturalness (8% worse), and condescension (15% worse).
When GPT-3.5 is prompted to imitate the input dialect, the responses exacerbate stereotyping content (9% worse) and lack of comprehension (6% worse). GPT-4 is a newer, more powerful model than GPT-3.5, so we’d hope that it would improve over GPT-3.5. But although GPT-4 responses imitating the input improve on GPT-3.5 in terms of warmth, comprehension, and friendliness, they exacerbate stereotyping (14% worse than GPT-3.5 for minoritized varieties). That suggests that larger, newer models don’t automatically solve dialect discrimination: in fact, they might make it worse.
Implications
ChatGPT can perpetuate linguistic discrimination toward speakers of non-“standard” varieties. If these users have trouble getting ChatGPT to understand them, it’s harder for them to use these tools. That can reinforce barriers against speakers of non-“standard” varieties as AI models become increasingly used in daily life.
Moreover, stereotyping and demeaning responses perpetuate ideas that speakers of non-“standard” varieties speak less correctly and are less deserving of respect. As language model usage increases globally, these tools risk reinforcing power dynamics and amplifying inequalities that harm minoritized language communities.
Learn more here: [ paper ]
This article was initially published on the BAIR blog, and appears here with the authors’ permission.
tags: deep dive

AIhub is supported by:








