
ΑΙhub.org
Extending the reward structure in reinforcement learning: an interview with Tanmay Ambadkar

In this interview series, we’re meeting some of the AAAI/SIGAI Doctoral Consortium participants to find out more about their research. Tanmay Ambadkar is researching the reward structure in reinforcement learning, with the goal of providing generalizable solutions that can provide robust guarantees and are easily deployable. We caught up with Tanmay to find out more about his research, and in particular, the constrained reinforcement learning framework he has been working on.
Tell us a bit about your PhD – where are you studying, and what is the topic of your research?
I am a 4th year PhD candidate at The Pennsylvania State University, PA, USA. I am being advised by Dr Abhinav Verma. While I haven’t really drilled down on what my dissertation will be titled, I would like to call it “Extending the reward structure in Reinforcement Learning”.
Could you give us an overview of the research you’ve carried out during your PhD?
My research aims to look beyond the Markovian reward structure that is the basis of reinforcement learning (RL). Most RL problems assume the reward is a single value that provides an indicator of how well you have done at the current timestep. This is the Markovian structure, where the history does not matter. This is not applicable for a lot of, if not most, real world RL problems. My research focuses on extending the reward function to allow non-Markovian properties using linear temporal logic, allowing the user to define constraints like safety or plan paths. These specifications get encoded as a reward signal that the agent can then exploit to solve the task at hand. Further, we move to vector rewards, where each channel defines a different objective, which the user can then provide a preference for. The policy then must change its behaviour according to the preference provided and thus form a pareto front of policies. Finally, we explore if we can allow non-Markovian structure on top of these vector valued rewards, which allows us to define interesting non-linear utility functions that break the fundamental bellman property assumption.
Is there an aspect of your research that has been particularly interesting?
I would like to highlight the constrained RL framework we have been working on. Specifically, we tackle the problem of defining hard safety constraints on the state features of the environment which must be obeyed not just post training, but during training. Most constrained RL frameworks can provide guarantees after training, but learn to be safe after committing a lot of violations in training. In the specific setting that we operate, we terminate the agent as soon as it is unsafe. Along with this, the safety signal is binary, which the agent only receives if unsafe. This creates significant challenges for existing RL frameworks (CPO, CUP, Saute RL), which we show in our experiments, fail completely.
We turn to neurosymbolic techniques. Specifically, we study formal methods used in control theory to see if we can apply them in RL. Existing formal methods + RL work has shown extremely promising performance, but they suffer from compute explosion with state dimension. Specifically, they operate under unrealistic assumptions like having access to the transition function and work with very small state spaces (less than 10 dimensions). We borrow two fundamental advances in control theory – Koopman operators and control barrier functions. The Koopman operator theory is extremely interesting, it says that we can approximate highly non-linear dynamics as a global linear operator by finding functions in an infinite dimensional space to restore the linear property. This was never tried before in formal methods, where the assumption was you need to use a bottleneck space or a patchwork of linear models.
We proposed using the Koopman operator with weakest preconditions to show that we can extend safety up to 17 dimensions. However, this was still not the best result. We started working on creating a control barrier function. A control barrier function is like a force field that allows you to approach the barrier as fast as possible, but the force field starts to repel you away as you get closer. Control theory research would build control barrier functions (CBFs) for specific use cases with the assumption of known dynamics, something we cannot do for RL. Additionally, it does not operate in the discrete RL setting.
We propose the first multi-step robust CBF called RAMPS (ICLR 2026). We learn linear dynamics (simple linear regression also works) and approximate a high percentile error bound on one-step predictions (99th percentile) to then create a robust barrier function which can look ahead multiple steps into the future and prevent violations. This prevents an unsafe action from being taken now, which will violate safety a few steps in the future. RAMPS is the first method to extend safety to 348 dimensional state spaces with highly non-linear dynamics (Ant and Humanoid), while being extremely fast (sub-millisecond response time). With RAMPS, we show 90% reduction in safety violations while achieving 10x increase in reward performance. This is the first approach that allows RL + formal methods theory to be applicable to real world robotics, something which we are looking to try our hands at now.
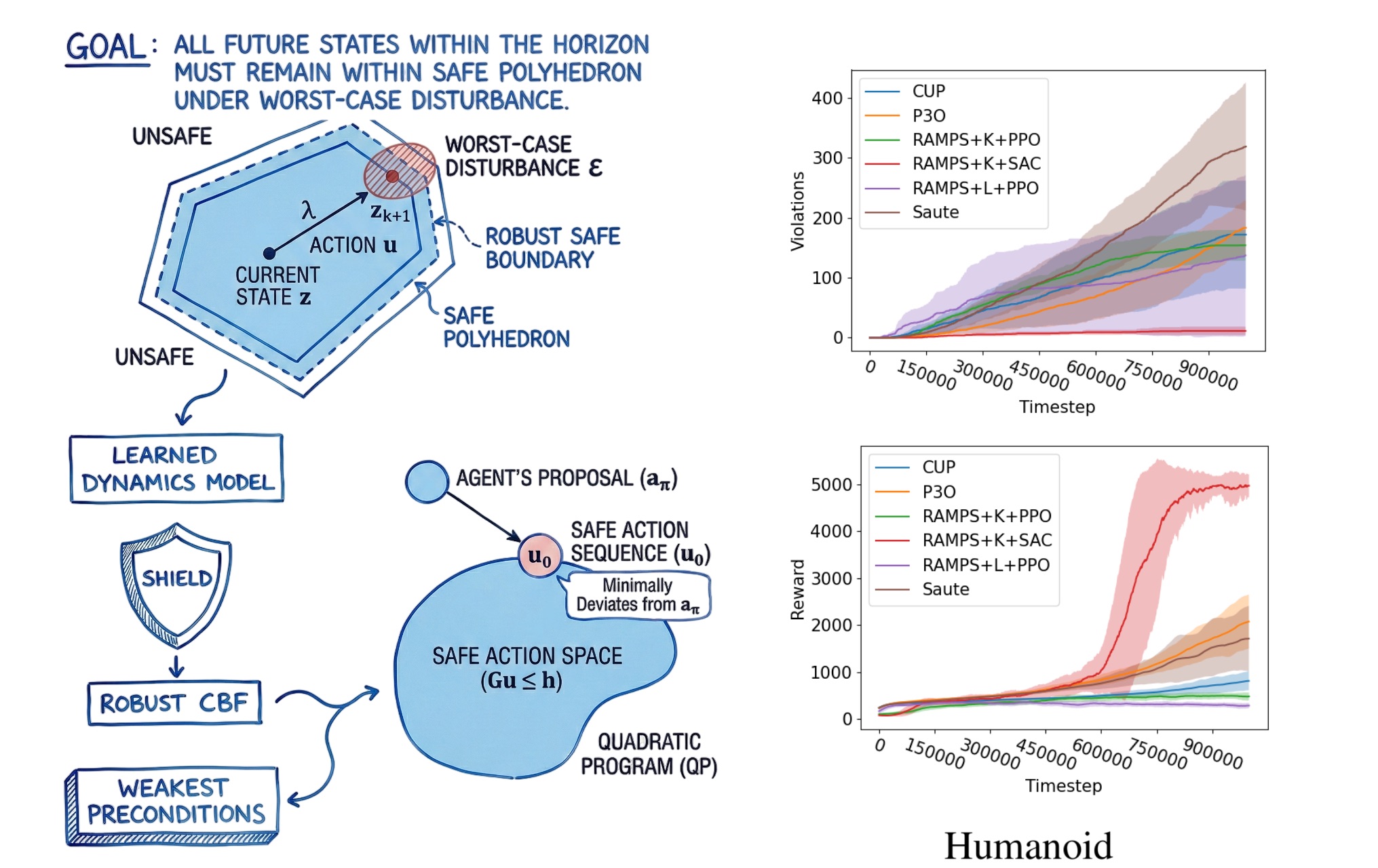
What are your plans for building on your research so far during the PhD – what aspects will you be investigating next?
Continuing on the constrained RL framework, we have shown extensibility to 348 dimensions. While this makes it usable for a lot of problems, it cannot work with vision problems. With vision data, it is impossible to define constraints over the state space, because the state space is made up of pixels. The constraints now have to be based on hidden simulator states (partially observable) and encoded as a cost function. We are looking to extend the control barrier theory to vision domains and show that formal method techniques are extremely useful for all problem classes and provide extremely robust theoretical guarantees.
In addition to this, we would like to tackle the fundamental problem of sparse costs of safety, which make it extremely difficult to learn a good policy. We want to see if we can apply formal method theory to generate dense cost signals that can inform these Lagrangian policies of the impending danger that might not be obvious at the current position. Finally, I want to work towards extending all my work towards LLMs. LLMs are notoriously difficult models to work with due to their mammoth size and relatively lesser understanding. With my knowledge of RL theory and reward functions, I want to explore if we can elicit desired behaviour in large language models by modifying certain properties or incorporating elements of neurosymbolic architecture. I also want to see if I can bring my expertise in RL towards better alignment algorithms.
What made you want to study AI, and particularly the area of trustworthy AI?
I have been fascinated with tech ever since I looked at a computer. I love robots and envision an autonomous future, but movies like I, Robot made me realize that we need trustworthy AI to ensure we do not cause harm.
I would like to thank my family for introducing me to hardware (Raspberry Pi), which taught me how to code and its real-world impact. To put my love for robotics into practice, I tinkered with ML and landed on reinforcement learning — captivated by the idea of a system learning to perform a task using just feedback.
This path led me to pursue an advanced degree in AI. My advisor introduced me to fundamental challenges that limit the use of RL in the real world, which steered me toward studying trustworthy AI. I look forward to exploring other applications where I can ensure AI is always safe.
Could you tell us an interesting (non-AI related) fact about you?
I love music and I play the piano. I have mostly taught myself via YouTube videos and can finally play almost any song by ear (YAY)! A lesser known fact (rather well-kept secret) about me is I used to mix music and post it on YouTube to potentially kickstart a DJing career.
About Tanmay Ambadkar

|
I am a Ph.D. Candidate at the Pennsylvania State University, USA. My research studies the various possibilities of reward functions to extend RL to a multitude of real-world use cases that might not follow the standard RL properties. I combine deep reinforcement learning with formal method theory to provide neurosymbolic solutions that are trustworthy and interpretable. My goal is to be able to provide generalizable solutions that can provide robust guarantees and are easily deployable. |
tags: AAAI, AAAI Doctoral Consortium, AAAI2026, ACM SIGAI

AIhub is supported by:








