
ΑΙhub.org
Counterfactuals in explainable AI: interview with Ulrike Kuhl
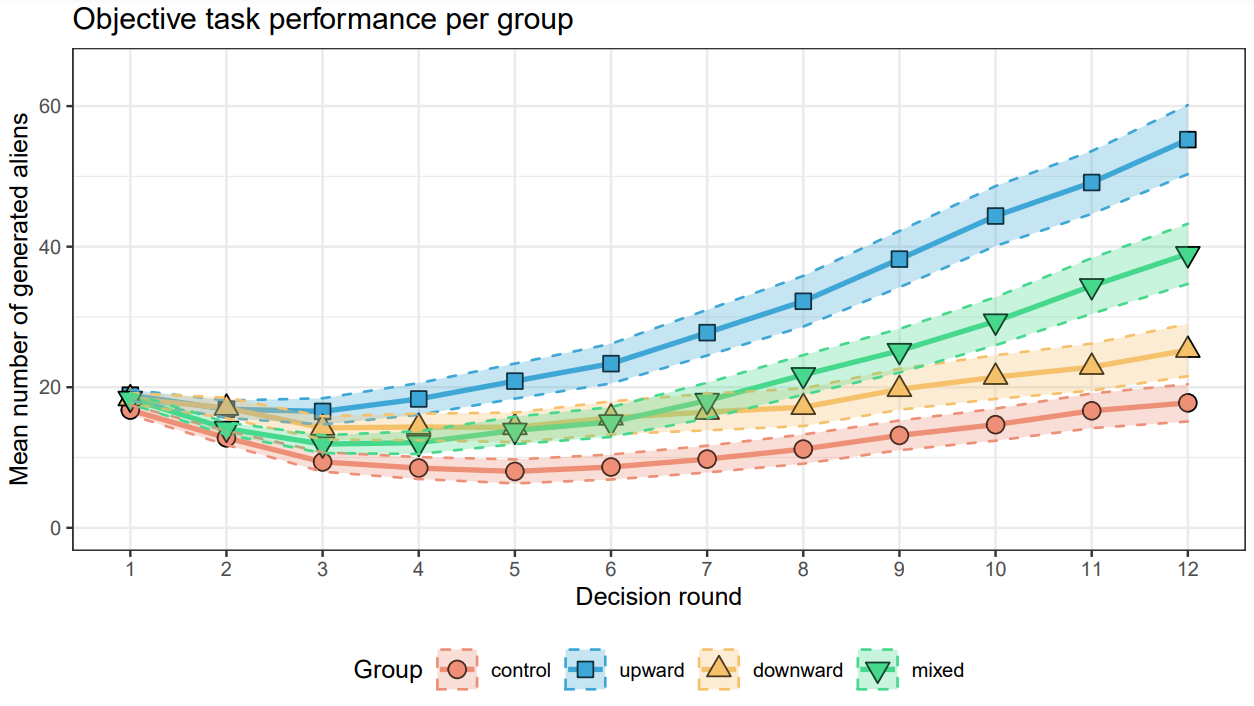 Objective task performance, measured as development of mean number of generated aliens per round per group.
Objective task performance, measured as development of mean number of generated aliens per round per group.
In their work For Better or Worse: The Impact of Counterfactual Explanations’ Directionality on User Behavior in xAI, Ulrike Kuhl, and colleagues André Artelt and Barbara Hammer, have investigated counterfactual explanations in explainable artificial intelligence. In this interview, Ulrike tells us more about their study, and highlights some of their interesting and surprising findings.
Could you give us a quick introduction to counterfactual explanations – what they are and how they are used in explainable AI?
Counterfactual statements are something we as humans use every day. Phrases like “If I had gotten up earlier, I would have been on time” are counterfactuals, describing a hypothetical alternative to the current, factual state. In the realm of explainable AI (xAI), counterfactuals play a pivotal role by providing accessible and intuitive insights into the decision-making processes of AI models. They work as explanations by spotlighting the essential alterations required in the model’s input to modify a prediction. In simpler terms, it’s akin to asking: “What changes should I make to the input data to achieve a different outcome?” In this way, counterfactuals explanations (CFEs) are expected to act as a bridge between complex AI predictions and human comprehension.
From a computational perspective, counterfactuals are highly appealing as they can be formalized as a straightforward optimization problem, determining small alterations to the input data of an AI model that would result in a different prediction or outcome. Therefore, they are considered a valuable tool for enhancing the transparency and interpretability of AI models across various domains.
What is the focus of study in your paper?
The focus of our study stems from an intriguing observation surrounding these types of explanations: Individual counterfactuals differ fundamentally in terms of quality of the alternative scenario they depict. They may describe a better alternative world (“If I had eaten more potato chips, I wouldn’t be hungry right now.”) or a worse one (“If I had eaten more potato chips, I would have gained too much weight.”).
We know from psychological research that humans deal with these different types differently: Thinking about “what would have been better” (upward direction) typically fuels motivation and leads to an adjustment in future action. The effects of pondering “what would have been worse” (downward direction) are more complex: On the one hand, evidence points towards inducing relief as it highlights that the current situation is not as dire as it could have been. Conversely, some authors argue that it serves as a wake-up call, making individuals more aware of the potential downsides.
What makes our research particularly relevant to the landscape of xAI is the fact that this directionality aspect is barely ever considered. Thus, we made it the focal point of our study to explore whether both types of counterfactuals are equally valuable for explaining the behavior of AI models, and whether individuals, including those without extensive technical knowledge, can effectively use them to gain insights from an AI system.
Could you talk about how you went about carrying out your user study?
The user study is based on an experimental framework we specifically designed to investigate various aspects of CFEs, the so-called Alien Zoo. In this framework, participants play an online game where they imagine themselves as a zookeeper taking care of a pack of aliens. Each round, they must select a combination of plants to feed their pack. If the choice was good, the pack thrives, and the number of aliens increases. If the choice was bad, it decreases.
Pack size is computed by a machine learning model, and for each input the user gives, the system computes a counterfactual that is presented to users in regular intervals. We tested the effects in four independent experimental groups: Users in group 1 received upward CFEs (“Your result would have been BETTER if you had selected:”). Users in group 2 received downward CFEs (“Your result would have been WORSE if you had selected:”). We also wanted to see whether there might be an additive effect of both types of information, so users in group 3 received mixed feedback (BOTH). As a control, the fourth group did not receive any explanations. The challenge for the users in each group is to figure out a good diet by interacting with the system.
By comparing the development of the pack sizes between groups, we can evaluate whether the explanations help users to solve the task. By asking people afterward about their specific knowledge and subjective experience, we can draw conclusions about how much users took away, and how much they felt the explanations helped.

 Exemplary scenes from the Alien Zoo game. (A) Example of a typical decision scene. (B) Example of a feedback scene for participants in the upward CFE condition, displaying user decision from the last two rounds, respective impact on alien number, and computed CFE.
Exemplary scenes from the Alien Zoo game. (A) Example of a typical decision scene. (B) Example of a feedback scene for participants in the upward CFE condition, displaying user decision from the last two rounds, respective impact on alien number, and computed CFE.
What were your main findings?
We found that there was indeed a systematic difference in terms of how many aliens users produced depending on which group they were in. In contrast to all other groups, participants who receive upward CFEs outperform all other groups at some point over time within the game, producing more aliens. In addition to this objective task performance, we also asked participants whether they could categorize plants as relevant and irrelevant. These categorization results show that participants receiving upward CFEs could also categorize plants significantly better than downward participants. This suggests that users provided with upward explanations were able to form a more accurate and explicit understanding of the underlying data distribution.
In summary, our findings support the notion that informing users of “what would have been better” serves as the most actionable and beneficial feedback in the setting we tested: Upward CFEs lead to both better objective task performance and explicit knowledge of the underlying data distribution.
One possible mechanism underlying these results is the concept of “regulatory fit.” This psychological phenomenon suggests that when the direction of the explanation aligns with the user’s task motivation, it can induce greater motivation and enhance usability. Our findings indicate that the alignment of upward CFEs with the task motivation may have contributed to the increased user satisfaction and motivation, ultimately leading to superior task performance. These results highlight the practical significance of considering the motivational aspect in the design of counterfactual explanations for AI systems.
Were there any particularly interesting or surprising findings?
Our study unveiled not just one, but two aspects that held surprises in store for us.
On the one hand, we initially had limited expectations regarding how mixed feedback would influence user performance, so looking at this group was intriguing. Interestingly, participants who received both upward and downward feedback displayed a performance pattern that lay in between those who received upward CFEs rather than the downward CFE group. Over the course of the game, users in the mixed group performed better than the control group and the downward CFE group but stayed below the upward CFE group. This observation may suggest that the notion of regulatory fit may apply even in cases where the condition only partially aligns with the user’s task motivation. While not as effective as pure upward CFEs, the mixed feedback did seem to provide a performance boost.
The second point was that in terms of subjective experience, there were no differences between groups. That means, even while the upward group was better objectively, their responses after the game did not show that they liked the explanations more, or found the more usable, than the other groups. This even applied when compared to control participants’ that did not receive any explanations at all. This points to a challenge: objective performance and subjective feeling are not the same, and there is much research needed to disentangle these two aspects.
Overall, these aspects underscore the complexity of human-AI interaction, where a more nuanced approach to counterfactual explanations may yield unexpected but advantageous results.
Objective task performance, measured as development of mean number of generated aliens per round per group.
What further work are you planning in this area?
This study shows that upward CFEs offer valuable feedback for novice users in abstract domains. However, the generalizability of these findings remains an open question. To address this, our future work aims to extend our investigations into more realistic settings.
Further, by investigating the utility and user-friendliness of both “better” and “worse” counterfactuals, we started to shed light on only one of many underexplored dimensions in xAI. We are committed to transparency and collaborative research, and thus made our study and the experimental code openly available. By sharing our work, we aim to facilitate an exploration of the diverse unexplored dimensions of CFEs also by other interested researchers, thus hoping to contribute to a more comprehensive understanding of how counterfactual explanations can improve the interpretability and practical usability of AI.
About Ulrike

|
Dr Ulrike Kuhl is a postdoctoral researcher at Bielefeld University, affiliated with the CoR-Lab Research Institute for Cognition and Robotics and overseeing the Data-NInJA research training group supporting junior researchers working on trustworthy AI. As a cognitive scientist with a background in neuroscience, she holds a PhD from the Max Planck Institute for Human Cognitive and Brain Sciences in Leipzig. With her research, she aspires to contribute to a more comprehensive understanding of the human factors involved in explainable AI, ultimately fostering the development of more user-centered and actionable explanations for automated systems. |
Read the research in full
For Better or Worse: The Impact of Counterfactual Explanations’ Directionality on User Behavior in xAI, Ulrike Kuhl, André Artelt & Barbara Hammer, Explainable Artificial Intelligence (2023).
GitHub page for the project with code, user data, and evaluation scripts.

AUAI is supported by:








