
ΑΙhub.org
Interview with Anindya Das Antar: Evaluating effectiveness of moderation guardrails in aligning LLM outputs
In their paper presented at AIES 2025, “Do Your Guardrails Even Guard?” Method for Evaluating Effectiveness of Moderation Guardrails in Aligning LLM Outputs with Expert User Expectations, Anindya Das Antar, Xun Huan and Nikola Banovic propose a method to evaluate and select guardrails that best align LLM outputs with domain knowledge from subject-matter experts. Here, Anindya tells us more about their method, some case studies, and plans for future developments.
Could you give us some background to your work – why are guardrails such an important area for study?
Ensuring that large language models (LLMs) produce desirable outputs without harmful side effects and align with user expectations, organizational goals, and existing domain knowledge is crucial for their adoption in high-stakes decision-making. However, despite training on vast amounts of data, LLMs can still produce incorrect, misleading, or otherwise unexpected and undesirable outputs. When AI engineers identify such LLM limitations, they often retrain the model or fine-tune it with additional high-quality data, a process that is both costly and resource-intensive. To guard against incorrect, biased, and undesirable LLM outputs, natural language prompt-based guardrails offer a lightweight and flexible alternative to steering and aligning off-the-shelf LLMs with user expectations.
What is the latest research situation with regards to guardrails, and how effective have previous efforts been?
Existing research showed that guardrail engineers implement different types of guardrails based on knowledge from subject-matter authorities and existing literature to steer and align pre-trained LLMs with expert user expectations. Among them, input guardrails flag, filter, and remove inappropriate content from the user prompts before the LLM starts processing them as inputs. Whereas output guardrails validate the LLM-generated outputs before users see them and shape LLM decision-making. One common example is the use of LLM output moderation guardrails, implemented through prompt engineering, which translates expert input, corporate guidelines, and empirical findings into LLM behavior by injecting constraints, filtering criteria, or value-aligned instructions into natural language prompts.
However, not all guardrails are effective in steering and aligning LLM outputs. Some even introduce biases that negatively steer and impact LLM decision-making. Thus, it is essential to identify and retain only those guardrails that enhance alignment. Although existing evaluation methods assess LLM performance, with and without guardrails, they provide limited insight into the contribution of each individual guardrail and its interactions with other guardrails on enhancing user-LLM alignment. Additionally, evaluating all possible combinations of guardrails using quantitative performance or fairness metrics is computationally expensive, making it challenging to find an effective combination.
Could you tell us about the method that you’ve introduced?
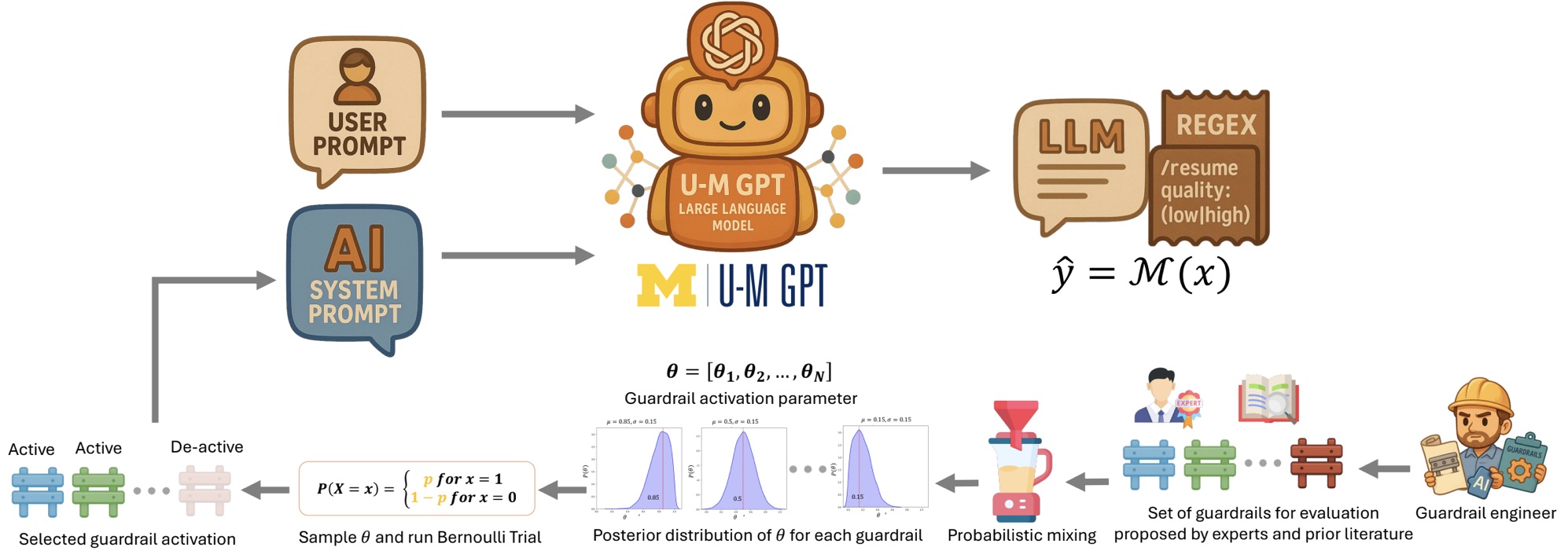
We propose a probabilistic Bayesian method to systematically evaluate and select guardrails that best align LLM outputs with empirical evidence representing domain knowledge from subject-matter experts. Our method produces measurable and interpretable estimates of the contribution of individual guardrails and their interactions to model alignment. Instead of simply accepting or rejecting a guardrail, our method learns the uncertainty and effectiveness of each guardrail by estimating a mixing parameter, or guardrail activation probability (theta), which captures how different guardrails, and in what proportions, contribute to better LLM alignment. You can think of it a bit like those ASMR paint-mixing videos: our method attempts to find the optimal mixture of “colors” (guardrails) that best matches (aligns with) the target reference “shade” (expert-defined output) by learning the uncertainty and confidence in the mixture.
If researchers wish to utilize our method to assess a set of moderation guardrails aimed at aligning the LLM with their expectations and domain knowledge, they must first articulate those expected outcomes. Initially, subject matter experts need to capture their domain knowledge and desired outputs in an empirical alignment dataset or use an existing one that ensures a fair benchmark. Our method then estimates a vector of Bernoulli parameters, denoted as theta, which represents the activation probability of each corresponding guardrail. Additionally, it models the posterior probability distribution of theta to account for uncertainty in its estimation. Unlike deterministic approaches that merely switch guardrails on or off, our method treats theta as a continuous probability, allowing for a more nuanced evaluation.
Would you be able to say something about the use cases that you’ve tested your method on?
We conducted a series of quantitative experiments to validate our method’s ability to select effective guardrails and reject ineffective ones for user–LLM alignment. Acting as guardrail engineers, we illustrated and evaluated our approach using two publicly available datasets across two real-world applications: 1) resume quality classification and 2) recidivism prediction (a defendant’s likelihood of reoffending). Each use case is grounded in a clear alignment goal: 1) promoting equal opportunity in hiring and 2) fairness in criminal justice risk assessment, regardless of candidates’ or defendants’ gender or ethnicity. We leveraged knowledge from subject matter authority experts, along with existing empirical data, to construct an alignment dataset and a set of moderation guardrails, including specially designed distractor guardrails that should not be selected. Our findings demonstrated that our method effectively identifies useful moderation guardrails, enabling guardrail engineers to select and interpret the contributions of different guardrails to “user-LLM” alignment. Our results also showed that our method selects guardrails that align LLM predictions with expert expectations better than the model alone.
To summarize, we proposed a Bayesian probabilistic method to evaluate and select guardrails that best align LLM outputs with expert user expectations. Unlike deterministic methods that toggle guardrails on or off, our method learns to probabilistically find the optimal guardrail combination by accounting for uncertainty. Finally, using resume quality and recidivism prediction examples, our validation showed that our method helps guardrail engineers select effective guardrails and understand their contribution in user–LLM alignment.
What are your plans for future work in this space?
- While we demonstrated our method with moderation guardrails, it can be extended to evaluate adversarial and security-focused guardrails aimed at preventing jailbreaking and reducing LLM hallucinations.
- In this work, we conducted quantitative evaluations primarily with guardrail engineers; future studies could more directly engage domain experts, ethicists, policymakers, and industry practitioners in the evaluation process. Because alignment goals may differ or even conflict across stakeholders, our method emphasizes explicitly defining the alignment objective and target audience upfront. This could support LLM auditability, traceability, and non-discrimination in high-risk applications.
- For users who may find probability density plots difficult to interpret, future work could incorporate explanation tools that improve understanding of guardrail effects at both the local level (e.g., for individual resumes) and the cohort level (e.g., across different demographic groups).
- In addition, while prompt-based guardrails are well-suited to LLMs, many deployed models rely on other steering mechanisms; extending our method to evaluate these alternative approaches is another important direction.
- Finally, we plan to explore how the approach scales to larger datasets, more complex tasks, and adaptive guardrail configurations that respond to evolving user needs over time.
Together, these efforts aim to further strengthen user–LLM alignment and support the ethical and responsible deployment of LLM-based decision-support systems in high-stakes, real-world settings.
About Anindya Das Antar

|
Anindya Das Antar is a Postdoctoral Fellow at the Lucy Family Institute for Data & Society at the University of Notre Dame. He is a HCI researcher focused on applied machine learning, human-centered explainable AI, and responsible AI for human–AI alignment. His work centers on human behavior modeling and the design of interactive tools that help both AI engineers and domain experts identify and introduce missing latent domain knowledge in AI models. Anindya earned his Masters and Ph.D. in Computer Science and Engineering from the University of Michigan. His research has been supported by Procter & Gamble, Toyota Research Institute, NIH, and the Office of Naval Research. |
Read the work in full
“Do Your Guardrails Even Guard?” Method for Evaluating Effectiveness of Moderation Guardrails in Aligning LLM Outputs with Expert User Expectations, Anindya Das Antar, Xun Huan, Nikola Banovic.
tags: AAAI, ACM SIGAI, AIES, AIES2025

AUAI is supported by:








