
ΑΙhub.org
Career advisor systems

Career advisor systems are essentially recommender systems in the space of job searching and career advice. They provide recommendations to candidates with possible career paths and to employers with possible candidates for a job opening. In this post we will outline the required capabilities of such systems, and highlight the challenges that need to be overcome in order to construct a working system. Questions like “What is a career advisor system?”, “What is it capable of doing?”, ”Why do we need them?” etc are answered in this article. We also discuss our recent work (presented at AAAI-IAAI [1]) which describes how we proposed to solve this problem.
Career advisor systems differ from typical recommender systems in more than one aspect. The main differences stem from the following:
- Job descriptions (JD) and curriculum vitae (CV) typically exist in free-text form instead of some structured data (candidates usually design their CVs to draw the attention of employers, and this adds an additional layer of complexity),
- Hot skills, and associated sought after domains, may change over time,
- Skills have complex relationships among themselves (C is related to C++; C++ is related to Java etc),
- Career paths one may choose are very personal depending upon the skills, aspirations, needs and constraints of a person.
The two important stakeholders in the career space are candidates and employers.
Candidates
Every candidate is unique in terms of skills, experience and education. Therefore, personalized career path recommendation systems that could mine the current career profile and recommend the most relevant career paths for a candidate are an attractive proposition. The current recommendation systems within an organizational context (where the notion of career paths and job roles are well defined) could be effective in meeting this requirement. However, these systems may not be able to operate at an industrial sector level across organizations. This is primarily due to the lack of standardized definitions of jobs and career roles across organizations. For example, job responsibilities in a software engineering role in one organization might be similar to that of a system analyst role in another organization, but cannot be understood by a recommender system. Similarly, the role and expectations from a CEO of a start-up greatly vary from that of a CEO of a large company.
Employers
The inherent problem faced by an employer is that for a single job posting there could be hundreds, if not thousands, of applications. As the interview is a time intensive process, to invite a manageable number of applicants for the interview, the recruiters apply standard filters such as: a) the university an applicant attended, b) applicant’s exam grades, c) applicant’s experience, d) applicant’s current CTC (cost to company) etc. Such methods may introduce a heavy bias in how the top candidates are invited for interviews.
Nowadays, organisations use approaches such as application tracking systems (ATS) to filter through the first round of profiles. There are substantial gaps in how these systems function and in some cases they can be gamed. Typically such systems look for specific keywords and entities in a CV by doing dictionary lookups and hence are unable to interpret the context of a skill or measure the knowledge an individual may have of them. Such systems would also fail to infer implicit skills (skills that are not mentioned directly in the CV or JD but can be deduced). A simple example of this would be, if a person works on machine learning models using python, how likely are they to have an understanding of linear algebra and algorithmic methods, understand design principles or something as basic as being able to operate a computer? Such inferences of implicit skills are straightforward for humans, but difficult to impart to an algorithm. Also most such systems are domain specific and tailored for the roles in an organization. Often these systems may fail if a candidate has used some obscure formatting in their CV. Recent work on evaluation of recommendation systems [2] raises questions around the fairness and inherent bias in such systems across different genders, age groups, and racial or ethnic populations.
The primary goal of our research was to overcome some of these problems. We proposed to formalize skills as the building blocks for career recommendations as they are more amenable to standardization across candidates and organizations. We hypothesized that skill as a building block can be a uniform unit of measurement functioned with factors like years of experience, achievements like patents, publications, educational courses and qualifications. We envisage this system to be: domain independent, able to infer implicit skills, and quantify and rank individuals primarily based on their skills. In order to achieve this we had to answer: how can we teach a system to understand a skill-term without giving it a dictionary to look-up skills? Can we train a model that infers from context and associates terms in a sentence as potential skill terms? There are many approaches to achieve this. For example, one can train a conditional random field (CRF) model or a rule-based part-of-speech (PoS) tagging system. Our work dives into these questions and talks about a system that can perform some of these tasks reasonably well. We also established a benchmark for such systems in the future.
Our work explored three main things:
- An ensemble method for skill extraction from naturally occurring text in candidates’ resumes and JDs.
- The concept of implicit skills (that are not mentioned in a job description) is introduced and a method of extracting them is proposed. To identify these implicit skills for a JD, we find the other JDs similar to this JD. This similarity match is done in the semantic space using Doc2Vec. We trained our Doc2Vec model on 1.1 million JDs covering several domains crawled from the web, and all the JDs are projected onto this semantic space. The skills absent in the JD but present in similar JDs are obtained, and the obtained skills are weighted using several techniques to obtain the set of final implicit skills.
- A bi-directional matching algorithm that matches the skills of a candidate with skills mentioned in a job description is proposed. Empirical results for matching resumes and JDs demonstrate that the proposed approach gives a mean reciprocal rank of 0.88, an improvement of 29.4% when compared to the performance of a baseline method that uses only explicit skills.
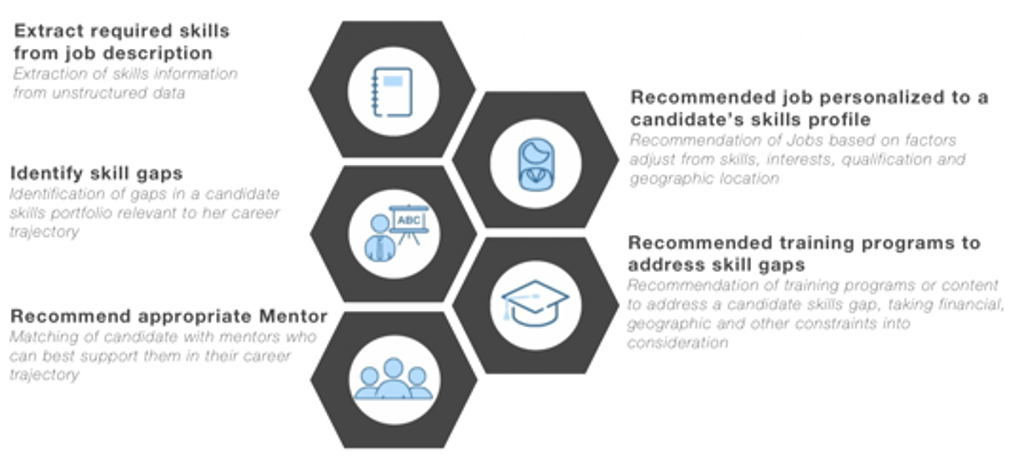
The applications of such a system are widespread and Figure 1 contains some of the possibilities including skill gap identification, career counselling and recommending respective next steps [3]. To elaborate an example, skill gap analysis tools can be used by students and recent college graduates to identify skills and courses to upskill or bridge the gap between their current skills and their career goals. In addition, with a knowledge-driven economy spurred by rapid technological advances, existing workers often find that their skills are outdated and their jobs under threat [4,5]. These workers could be greatly helped by these skill gap analysis tools to upskill themselves. Also, there is an evident misalignment between courses covered in academic institutions and industry needs, potentially resulting in unemployability and additional costs incurred by corporations to reskill or train their new hires [6,7]. Academic institutions can use the tool to introduce new hot skills to the curriculum.
A recent application of our work to solving a social issue is described next. We worked with EmancipAction, an organisation that helps trafficked children with resources like counselling, rehabilitation and support in India. During our discussion, we realised they face various challenges; one was identifying the right counsellor for the child. In a diverse country like India, the linguistic barrier between the counsellor and child is one factor to be considered. In addition there are counsellors who are more experienced with certain kinds of cases, age groups, etc. As a social good effort, we developed a multi-modal system for EmancipAction, which leveraged signals from the data of the child and the counsellor to make a well-guided recommendation using the counsellor experience as a feature for skills. The initial results were promising and this method could potentially reduce the stress of moving the child among various counsellors. Our specific findings from this particular work are published in our paper [8].
As we covered in this blog post, there are various challenges associated with a job recommendation system. We proposed a skill identification based system to overcome them. Our system (or parts of it) can be used for, or applied to, different applications and problem solving beyond job recommendation, career path recommendation and skill gap analysis, such as our social good example.
Newer language models like BERT and GPT-3 may also be suitable for the task of skill extraction after domain adaptation and be able to further improve our system and benchmarks. Research spanning these areas is vital and of obvious interest for both educational institutes and enterprises.
References
[1] Implicit Skills Extraction Using Document Embedding and Its Use in Job Recommendation, Akshay Gugnani and Hemant Misra
[2] Investigating Potential Factors Associated with Gender Discrimination in Collaborative Recommender Systems, Masoud Mansoury, Himan Abdollahpouri, Jessie Smith, Arman Dehpanah, Mykola Pechenizkiy, Bamshad Mobasher
[3] Generating Unified Candidate Skill Graph for Career Path Recommendation, Akshay Gugnani, Vinay Kumar Reddy Kasireddy and Karthikeyan Ponnalagu
[4] Aspiring Minds Report
[5] Education to Employment: Getting Europe’s Youth into Work
[6] Cognitive Education: Why Personalize?
[7] Job-Skills Mismatch Underlines Need for Re-training
[8] Multimodal Web Application to Infer Emotional Intelligence of Adolescent Counsellor, Prerna Agarwal, Anupama Ray, Ayush Shah, Akshay Gugnani, Priyanka Halli, Shubham Atreja, Gargi Dasgupta
tags: herotagrc


AUAI is supported by:








