
ΑΙhub.org
Large-scale training at BAIR with Ray Tune
By Richard Liaw, Eric Liang and Kristian Hartikainen
In this blog post, we share our experiences in developing two critical software libraries that many BAIR researchers use to execute large-scale AI experiments: Ray Tune and the Ray Cluster Launcher, both of which now back many popular open-source AI libraries.
As AI research becomes more compute intensive, many AI researchers have become squeezed for time and resources. Many researchers now rely on cloud providers like Amazon Web Services or Google Compute Platform to access the huge amounts of computational resources necessary for training large models.
Understanding research infrastructure
To put things into perspective, let’s first take a look at a standard machine learning workflow in industry (Figure 1).
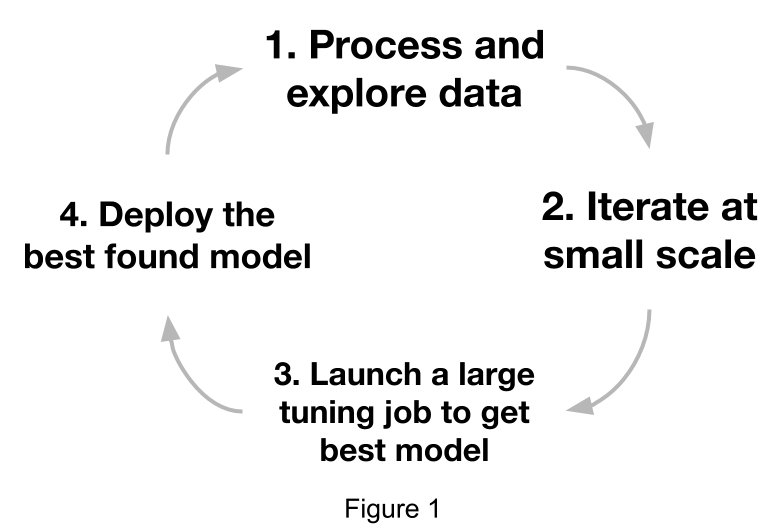
Figure 1 represents the typical ML model development workflow in
industry.
The typical research workflow is actually a tight loop between steps 2 and 3, generalizing to something like Figure 2.
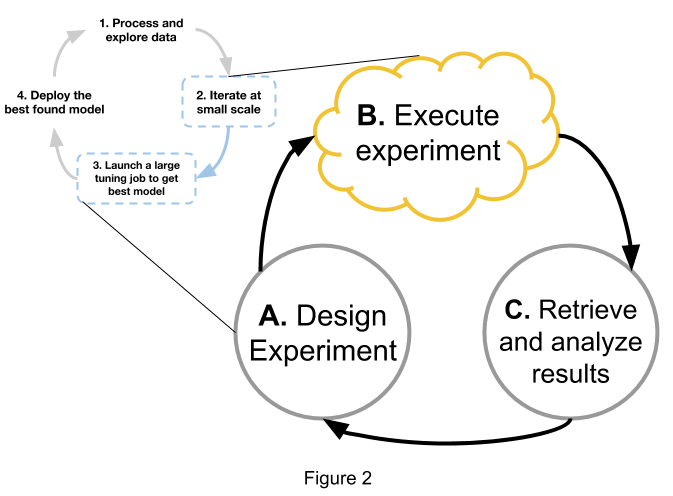
Figure 2 represents the typical ML model development workflow for research. The research workflow is typically a subsection of the industry workflow.
The research workflow is very much an iterative process and is often bottlenecked by the experiment execution step (Figure 2, B). Typically, an “experiment” consists of multiple training jobs, or “trials”, where each trial is a job that trains a single model. Each trial might train a model using a different set of configuration parameters (hyperparameters) or a different seed.
At Berkeley, we saw that AI researchers moving to the cloud spent a lot of time writing their own experiment execution tools that wrangled cloud-provider APIs for starting instances, setting up dependencies, and launching experiments.
Unfortunately, despite the vast amounts of time poured into developing these tools, these ad-hoc solutions are typically limited in functionality:
-
Simplistic Architecture: Each trial is typically launched on a separate node without any centralized control logic. This makes it difficult for researchers to implement optimization techniques such as Population-based Training or Bayesian Optimization that require coordination between different runs.
-
Lack of Fault Handling: The results of training jobs are lost forever if an instance fails. Researchers often manually manage the failover by tracking live experiments on a spreadsheet, but this is both time consuming and error-prone.
-
No Spot Instance Discount: The lack of fault tolerance capabilities also means forgoing the spot instance discount (up to 90%) that cloud providers offer.
To sum up, instrumenting and managing distributed experiments on cloud resources is both burdensome and difficult to get right. As such, easy-to-use frameworks that bridge the gap between execution and research can greatly accelerate the research process. Members from a couple of labs across BAIR collaborated to build two complementary tools for AI experimentation in the cloud:
Ray Tune: a fault-tolerant framework for training and hyperparameter tuning. Specifically, Ray Tune (or “Tune” for short):
- Coordinates among parallel jobs to enable parallel hyperparameter optimization.
- Automatically checkpoints and resumes training jobs in case of machine failures.
- Offers many state-of-the-art hyperparameter search algorithms such as Population-based Training and HyperBand.
Ray Cluster Launcher: a utility for managing resource provisioning and cluster configurations across AWS, GCP, and Kubernetes.
Ray Tune
Tune was built to address the shortcomings of these ad-hoc experiment execution tools. This was done by leveraging the Ray Actor API and adding failure handling.
Actor-based Training
Many techniques for hyperparameter optimization require a framework that monitors the metrics of all concurrent training jobs and controls the training execution. To address this, Tune uses a master-worker architecture to centralize decision-making and communicates with its distributed workers using the Ray Actor API.
What is the Ray Actor API? Ray provides an API to create an “actor” from a Python class. This enables classes and objects to be used in parallel and distributed settings.
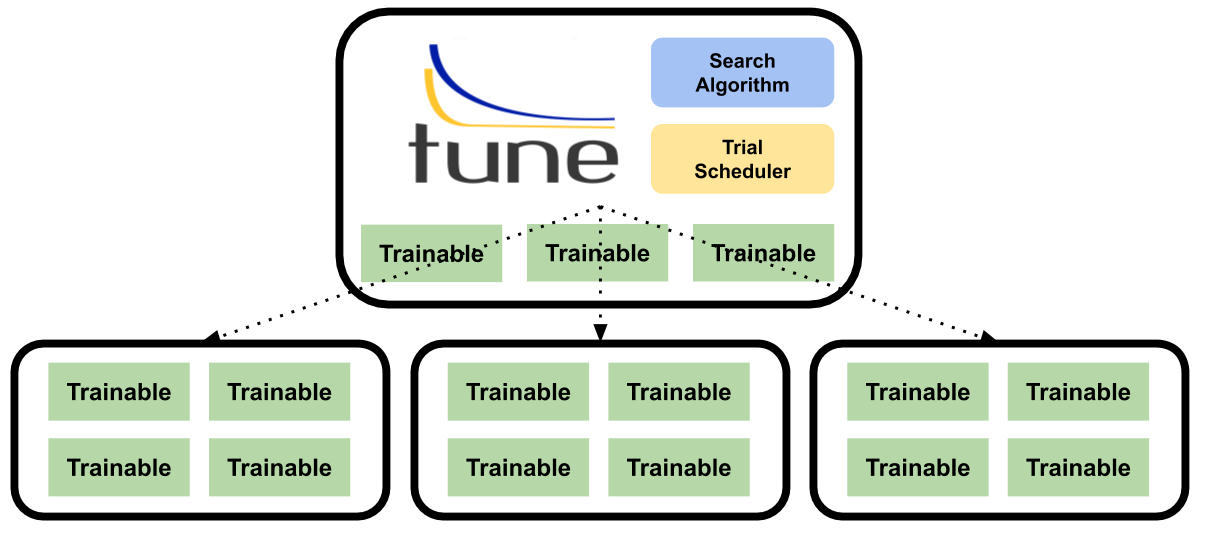
Tune uses a Trainable class interface to define an actor class specifically for training models. This interface exposes methods such as _train, _stop, _save, and _restore, which allows Tune to monitor intermediate training metrics and kill low-performing trials.
class NewTrainable(tune.Trainable):
def _setup(self, config):
...
def _train(self):
"""Run 1 step of training (e.g., one epoch).
Returns:
A dict of training metrics.
"""
...
def _save(self, checkpoint_dir):
...
def _restore(self, checkpoint_path):
...
More importantly, by leveraging the Actor API, we can implement parallel hyperparameter optimization methods in Tune such as HyperBand and Parallel Bayesian Optimization which was not possible with prior experiment execution tools that researchers used.
Fault Tolerance
Cloud providers often offer “preemptible instances” (i.e., spot instances) at a significant discount. The steep discounts allow researchers to lower their cloud computing costs significantly. However, the downside is that the cloud provider can terminate or stop your machine at any time, causing you to lose training progress.
To enable spot instance usage, we built Tune to automatically checkpoint and resume training jobs across different machines in the cluster so that experiments would be resilient to preemption and cluster resizing.
# Tune will resume training jobs from the last checkpoint
# even if machines are removed.
analysis = tune.run(
NewTrainable,
checkpoint_freq=5, # Checkpoint every 5 epochs
config={"lr": tune.grid_search([0.001, 0.01, 0.1])},
)
How does it work?
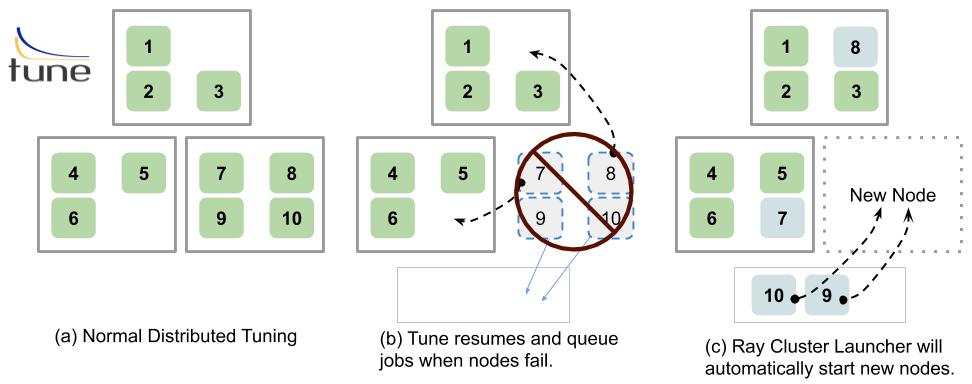
If a node is lost while a training job is still executing on that node and a checkpoint of the training job (trial) exists, Tune will wait until available resources are available to begin executing the trial again.
If the trial is placed on a different node, Tune will automatically push the previous checkpoint file to that node and restore the state, allowing the trial to resume from the latest checkpoint even after failure.
Ray Cluster Launcher
Above, we described the pains of wrangling cloud-provider APIs to automate the cluster setup process. However, even with a tool for spinning up clusters, researchers still have to go through a tedious workflow to run experiments:
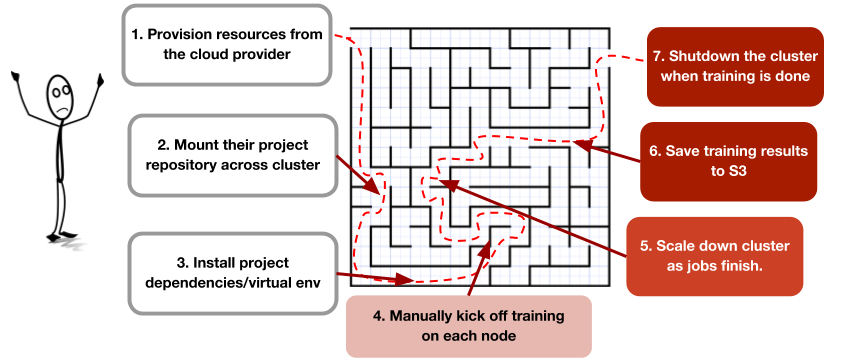
To simplify this, we built the Ray Cluster Launcher, a tool for provisioning and autoscaling resources and starting a Ray cluster on AWS EC2, GCP, and Kubernetes. We then abstracted all of the above steps for running an experiment into just a short configuration file and a single command:
# CLUSTER.yaml
cluster_name: tune-default
provider: {type: aws, region: us-west-2}
auth: {ssh_user: ubuntu}
min_workers: 0
max_workers: 2
# Deep Learning AMI (Ubuntu) Version 21.0
head_node: {
InstanceType: c4.2xlarge,
ImageId: ami-0b294f219d14e6a82}
worker_nodes: {
InstanceType: c4.2xlarge,
ImageId: ami-0b294f219d14e6a82}
setup_commands: # Set up each node.
- pip install ray numpy pandas
file_mounts: {
'/home/ubuntu/files':'my_files/',
}
The below command starts a cluster, uploads and runs a script for distributed
hyperparameter tuning, then shuts down the cluster.
$ ray submit CLUSTER.yaml --start --stop tune_experiment.py \
--args="--address=auto"
Researchers are now using both Ray Tune and the Ray Cluster Launcher to launch hundreds of parallel jobs at once across dozens of GPU machines at once. The Ray Tune documentation page for distributed experiments shows you how you can do this too.
Putting things together
Over the last year, we’ve been working with different groups across BAIR to better allow researchers to leverage the cloud. We had to make Ray Tune and the Ray Cluster Launcher general enough to support a large body of research codebases while making the barrier to entry so low that anyone could try it out in a couple of minutes.
# An example Ray Tune script for PyTorch.
import torch.optim as optim
from ray import tune
from ray.tune.examples.mnist_pytorch import (
get_data_loaders, ConvNet, train, test)
class TrainMNIST(tune.Trainable):
def _setup(self, config):
self.train_loader, self.test_loader = get_data_loaders()
self.model = ConvNet()
self.optimizer = optim.SGD(
self.model.parameters(), lr=config.get("lr", 0.01))
def _train(self):
train(self.model, self.optimizer, self.train_loader)
acc = test(self.model, self.test_loader)
return {"mean_accuracy": acc}
def _save(self, checkpoint_dir):
checkpoint_path = os.path.join(checkpoint_dir, "model.pth")
torch.save(self.model.state_dict(), checkpoint_path)
return checkpoint_path
def _restore(self, checkpoint_path):
self.model.load_state_dict(torch.load(checkpoint_path))
analysis = tune.run(
TrainMNIST,
stop={"training_iteration": 50},
config={"lr": tune.grid_search([0.001, 0.01, 0.1])})
print("Best hyperparameters: ", analysis.get_best_config(
metric="mean_accuracy"))
# Get a dataframe for analyzing trial results.
df = analysis.dataframe()
Tune has grown to become a popular open-source project for hyperparameter tuning. It is used in many other popular research projects, ranging from Population-based Data Augmentation, to Hyperparameter Tuning for AllenNLP, to AutoML in AnalyticsZoo.
Numerous open-source research projects from BAIR now rely on the combination of Ray Tune and the Ray Cluster Launcher to orchestrate and execute distributed experiments, including rail-berkeley/softlearning, HumanCompatibleAI/adversarial policies, and flow-project/flow.
So go ahead and try Ray Tune and Cluster Launcher yourself!
Links
- Previous BAIR blog posts about the Ray project:
- Ray website
- Ray GitHub page
- Ray documentation:
This article was initially published on the BAIR blog, and appears here with the authors’ permission.

AUAI is supported by:








