
ΑΙhub.org
RLPrompt: Optimizing discrete text prompts with reinforcement learning
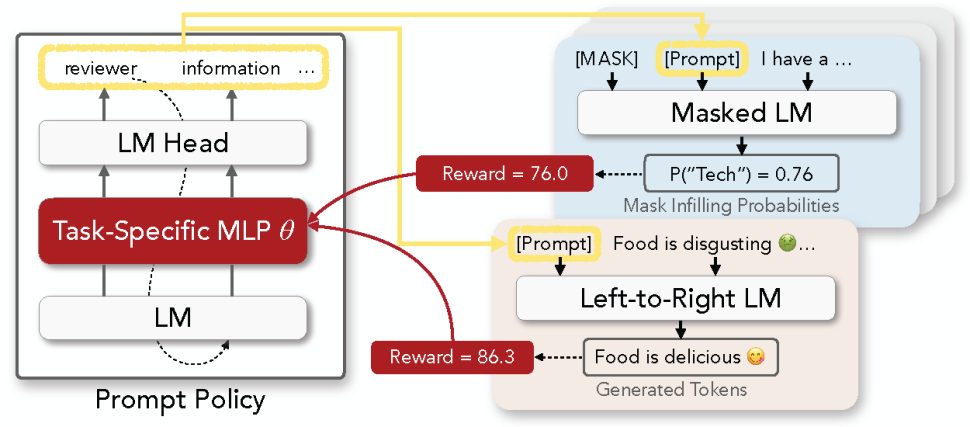 Figure 1: Overview of RL Prompt for discrete prompt optimization. All language models (LMs) are frozen. We build our policy network by training a task-specific multi-layer perceptron (MLP) network inserted into a frozen pre-trained LM. The figure above illustrates 1) generation of a prompt (left), 2) example usages in a masked LM for classification (top right) and a left-to-right LM for generation (bottom right), and 3) update of the MLP using RL reward signals (red arrows).
Figure 1: Overview of RL Prompt for discrete prompt optimization. All language models (LMs) are frozen. We build our policy network by training a task-specific multi-layer perceptron (MLP) network inserted into a frozen pre-trained LM. The figure above illustrates 1) generation of a prompt (left), 2) example usages in a masked LM for classification (top right) and a left-to-right LM for generation (bottom right), and 3) update of the MLP using RL reward signals (red arrows).
By Mingkai Deng
TL;DR: Prompting enables large language models (LLMs) to perform various NLP tasks without changing the model. Discrete prompts have many desirable properties, but are difficult to optimize. We propose an efficient approach using reinforcement learning, which shows superior performance and facilitates rich interpretations and analyses. You can easily adapt it for your own tasks using our library here.
Prompting has emerged as a promising approach to solving a wide range of NLP problems using large pre-trained language models (LMs), including left-to-right models such as GPTs and masked LMs such as BERT, RoBERTa, etc.
Compared to conventional fine-tuning that expensively updates the massive LM parameters for each downstream task, prompting concatenates the inputs with an additional piece of text that steers the LM to produce the desired outputs. A key question with prompting is how to find the optimal prompts to improve the LM’s performance on various tasks, often with only a few training examples.
Most existing work resorts to tuning soft prompt (e.g., embeddings) which falls short of interpretability, reusability across LMs, and applicability when gradients are not accessible. Discrete prompt, on the other hand, is difficult to optimize, and is often created by “enumeration (e.g., paraphrasing)-then-selection” heuristics that do not explore the prompt space systematically.
In our EMNLP 2022 paper, we instead propose RLPrompt, an efficient discrete prompt optimization approach with reinforcement learning (RL). RLPrompt is flexibly applicable to different types of LMs (e.g., BERT and GPTs) for both classification and generation tasks. Experiments on few-shot classification and unsupervised text style transfer show superior performance over a wide range of existing finetuning or prompting methods.
Interestingly, the resulting optimized prompts are often ungrammatical gibberish text; and surprisingly, those gibberish prompts are transferable between different LMs to retain significant performance, indicating LMs may have grasped shared structures for prompting, but do not follow human language patterns.
Discrete Prompt Optimization with RL
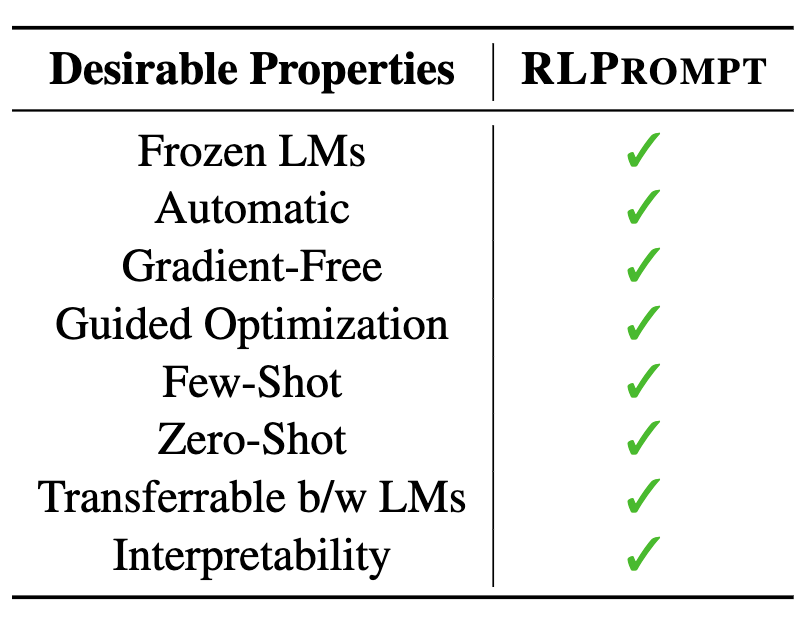
This paper presents RLPrompt, a new discrete prompt optimization approach based on reinforcement learning (RL). This approach brings together a wide range of desirable properties for efficient use on diverse tasks and LMs (see the table below).
Crucially, rather than directly editing the discrete tokens, which has been difficult and inefficient, RLPrompt trains a policy network that generates the desired prompts. Discrete prompt optimization thus amounts to learning a small number of policy parameters which we set as an MLP layer inserted into a frozen compact model such as distilGPT-2. We describe the specific formulations in Section §2.1-2.3 of our paper.
This formulation also allows us to employ off-the-shelf RL algorithms (e.g., soft Q-learning) that learn the policy with arbitrary reward functions—defined either with available data (e.g., in few-shot classification) or other weak signals when no supervised data is accessible (e.g., in controllable text generation).
Reward Stabilization
On the other hand, RL for prompt optimization poses new challenges to learning efficiency: the large black-box LM presents a highly complex environment that, given the prompt (i.e., actions), goes through a long series of complex transitions (e.g., reading the input and inferring the output) before computing the rewards. This makes the reward signals extremely unstable and hard to learn from.
To overcome this difficulty, we propose two simple yet surprisingly effective ways to stabilize the rewards and improve the optimization efficiency.
- Normalizing the training signal by computing the z-score of rewards for the same input.
- Designing piecewise reward functions that provide a sparse, qualitative bonus to desirable behaviors (e.g., certain accuracy on certain class).
We describe more details in Section §2.4 of our paper.
Experiments
We evaluate our approach on both classification (in the few-shot setting) and generation (unsupervised text style transfer), and perform rich analyses for new insights on LM prompting. We describe implementation details such as reward function design in Section §3 our paper, and publish the code at our Github codebase.
Few-Shot Text Classification
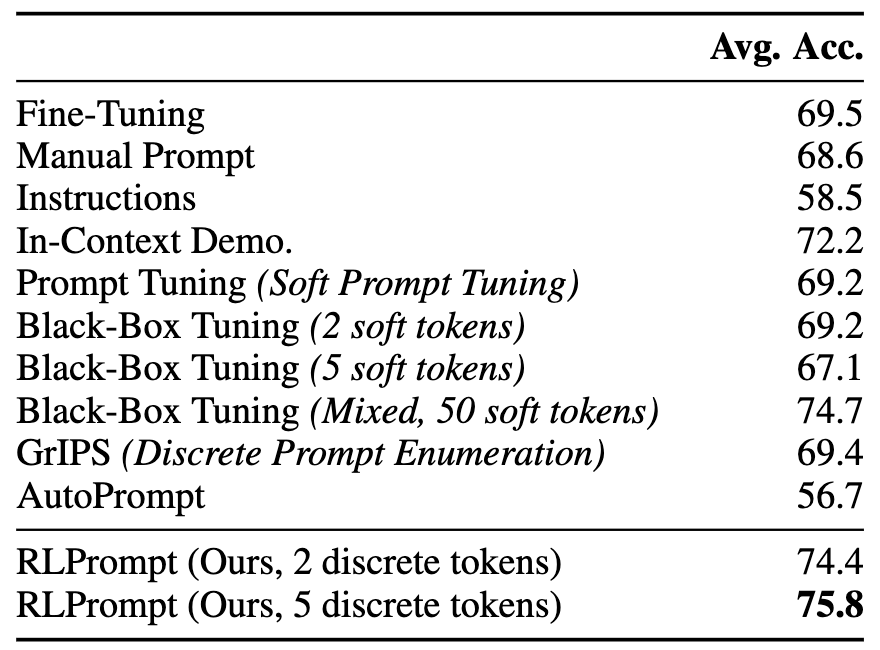
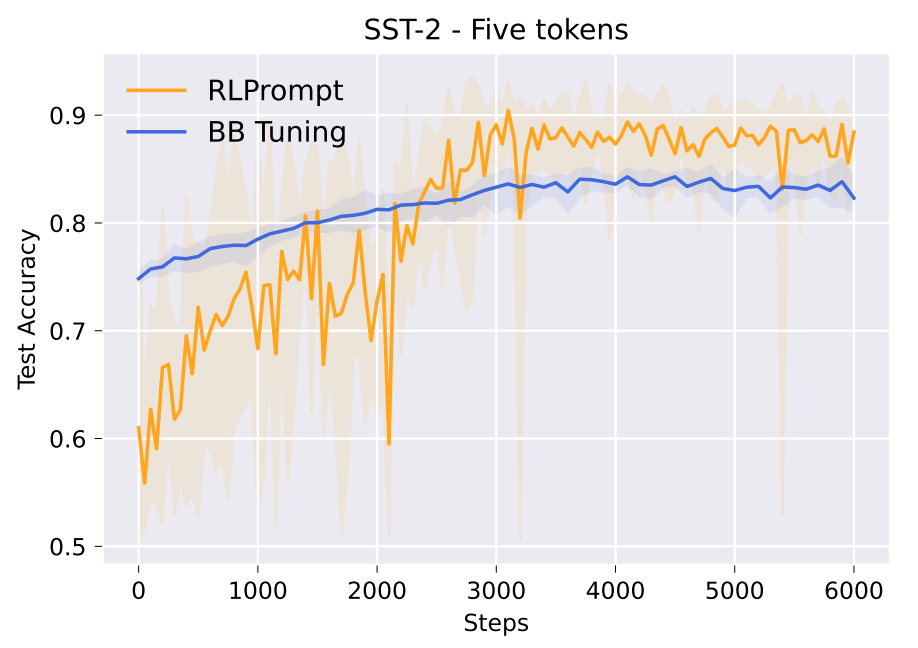
For few-shot classification, we follow previous work and experiment on popular sentiment and topic classification tasks, using 16 examples per class for both training and validation. Results using RoBERTa-large (left table below) show our approach improving over a wide range of fine-tuning and prompting methods, and is as efficient to optimize as similar methods that tune soft prompts (e.g., right figure below). We report detailed dataset-level results in Section §3.1 of our paper.
Unsupervised Text Style Transfer
For text style transfer, we evaluate on the popular Yelp sentiment transfer dataset using popular automatic metrics for content preservation, style accuracy, and fluency, and report their sentence-level joint product  below. Our full paper also includes few-shot experiments on the Shakespeare dataset and human evaluations.
below. Our full paper also includes few-shot experiments on the Shakespeare dataset and human evaluations.
Results using GPT-2 (left table below) show our method outperforms or competes with various fine-tuning and prompting baselines, including DiRR which expensively fine-tunes all parameters of a GPT-2 model. Ablation study (right figure below) shows that our proposed reward normalization technique is crucial to optimization success. We describe the full evaluation results in Section §3.2 of our paper.
 is our main metric which measures the average joint sentence-level scores of content preservation, style accuracy, and fluency. Numbers in (parentheses) are standard deviations across 3 sets of prompts.
is our main metric which measures the average joint sentence-level scores of content preservation, style accuracy, and fluency. Numbers in (parentheses) are standard deviations across 3 sets of prompts.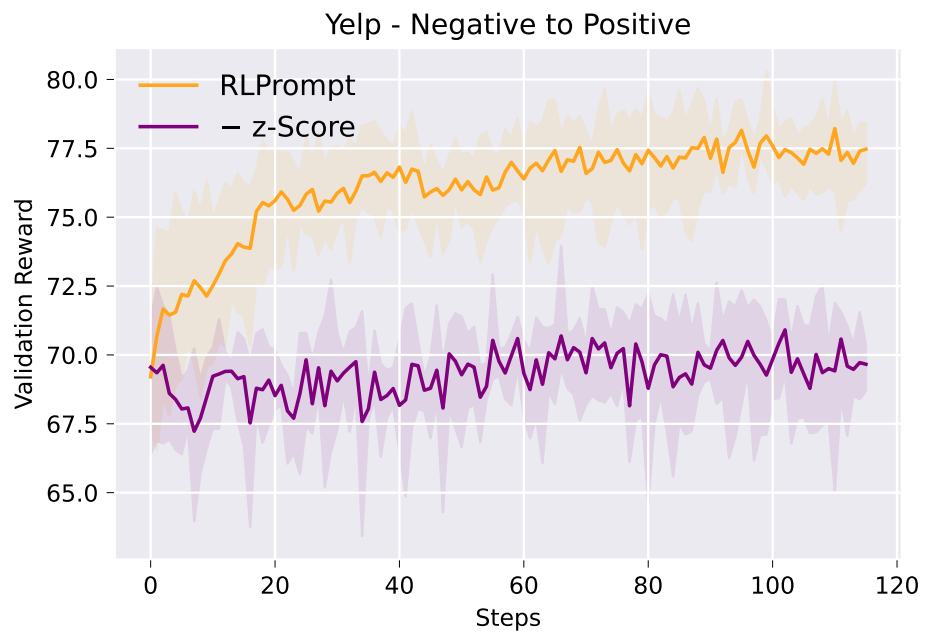
Analysis
Optimal Prompts Don’t Follow Human Language
The resulting discrete prompts also facilitate rich interpretations and analyses for new insights into LM prompting. In particular, the optimized prompts, though inducing strong task performance, tend to be gibberish text without clear human-understandable meaning (e.g., table below), echoing recent research (e.g., Webson and Pavlick (2021), Zhao et al., (2021), and Prasad et al., (2022)) that LMs making use of prompts do not necessarily follow human language patterns.
 is the main metric introduced in Table 2. All outputs are generated using GPT-2-xl and metrics are averaged over 5 runs.
is the main metric introduced in Table 2. All outputs are generated using GPT-2-xl and metrics are averaged over 5 runs.Learned Prompts Transfer Trivially Across LMs
Perhaps surprisingly, those gibberish prompts learned with one LM can be used in other LMs for significant performance, indicating that those different pre-trained LMs have grasped shared structures for prompting (e.g., figures below).

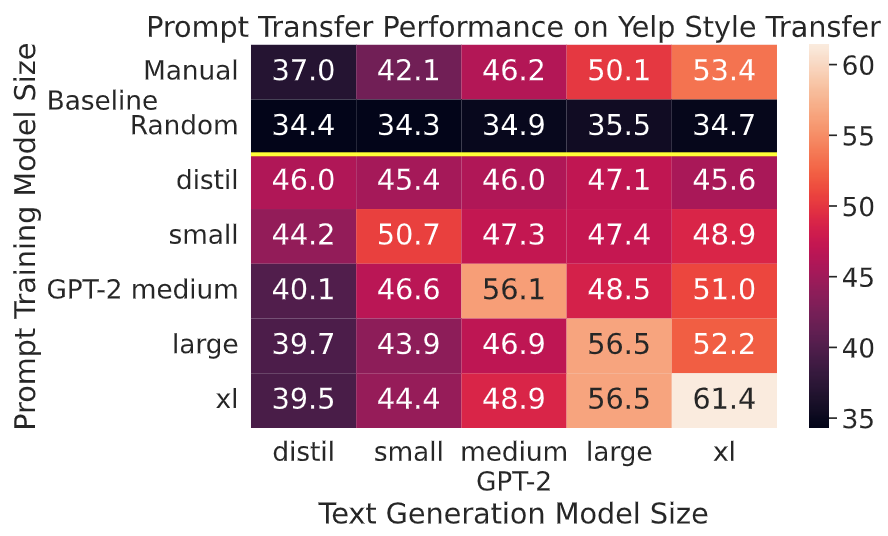 .
.Conclusion
We have presented RLPrompt, an efficient and flexible approach for discrete prompt optimization using RL, which improves over a wide range of fine-tuning and prompting methods in experiments on few-shot classification and unsupervised text style transfer.
Analysis reveals that strong optimized prompts are incoherent but transferable between LMs for remarkable performance. The observation opens up many promising possibilities for prompting, such as learning prompts cheaply from smaller models and performing inference with larger models. We are excited to explore further.
This article was initially published on the ML@CMU blog and appears here with the authors’ permission.
tags: deep dive

AUAI is supported by:








