
ΑΙhub.org
A comprehensive survey on rare event prediction
Rare events are infrequent incidents characterized by scarcity, often presenting computational challenges in data analysis. These events don’t happen often, as the name suggests, but they significantly impact when they do. For example, in pulp-and-paper manufacturing, paper breakage that occurs <1%, can cost $10,000/hour. Predicting such elusive occurrences is important in cost management, operational efficiency, and energy conservation.
In fact, these rare events are hidden pieces that, when discovered and understood, can lead to better decision-making and more efficient models. Such events can occur in various domains like healthcare, manufacturing, telecommunication, energy, and the economy. The ‘Curse of Rarity’ is the phenomenon where rare events pose challenges in detection and modeling due to their scarcity of data for analysis. Identifying them can be complex and computationally intensive due to rarity and class imbalances.
In our paper “A Comprehensive Survey on Rare Event Prediction“, we review rare event prediction literature along four dimensions: rare event data, data processing, algorithms, and evaluation. We explore these categories, considering rarity levels, industries, data types, modalities, and downstream applications while highlighting open research questions and future directions in the field (Figure 1).
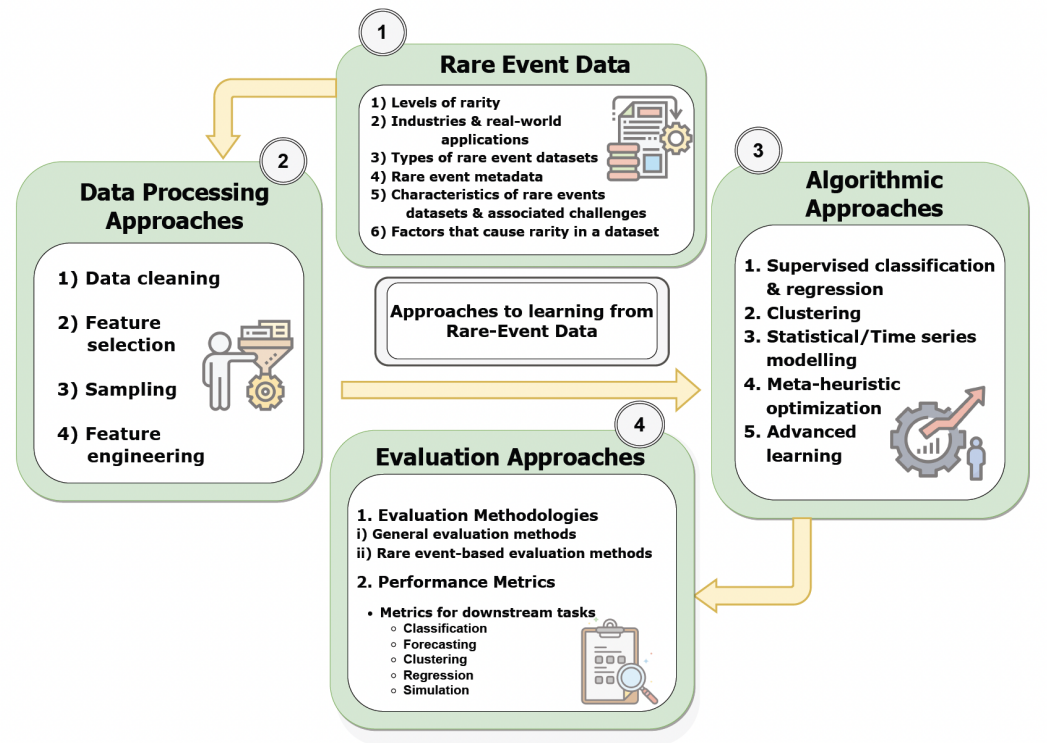
Figure 1: Approaches to learning from rare event data
Rare events are usually weighted by ‘rarity’, a measure of being rare, uncommon, or scarce. To characterize the current literature, we use “levels of rarity” (Figure 2). It categorizes rarity into four levels: extremely-rare, very-rare, moderately-rare, and frequently-rare.
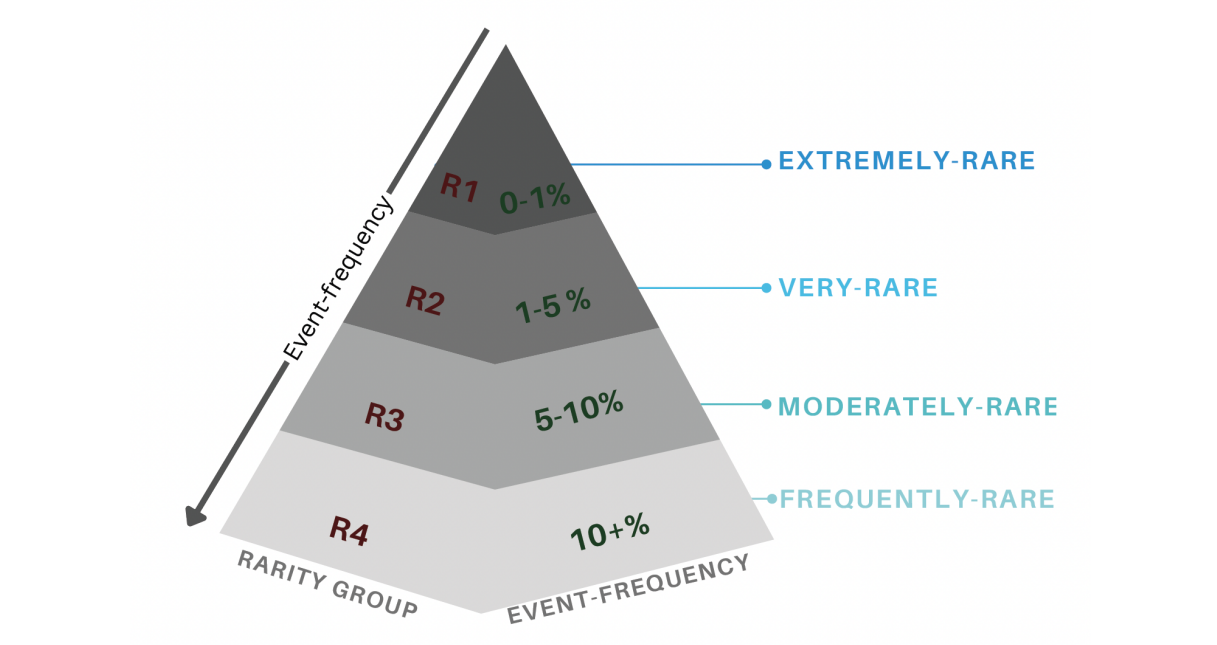
Figure 2: Levels of rarity
1. Rare-event data
In this study, we analyze 73 rare-event datasets across multiple industries encompassing various modalities, including numerical, image, text, and audio.
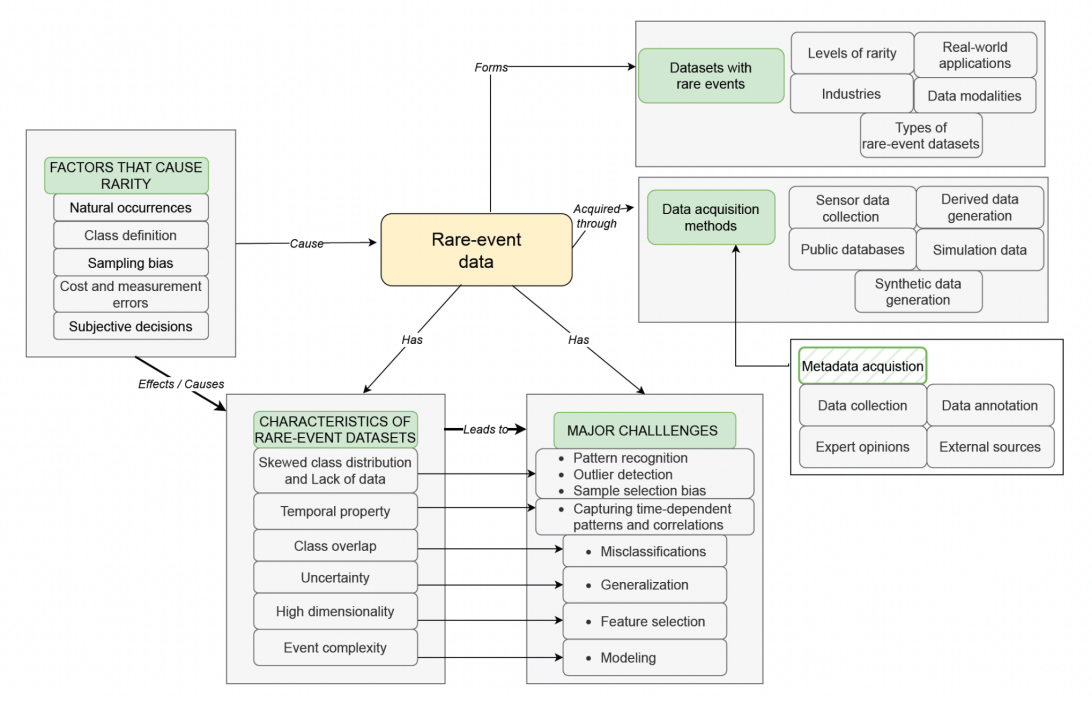
Industries and real-world applications: Various industries, such as earth sciences, telecommunication, healthcare, finance, manufacturing, transportation, economy, and energy, utilize rare event datasets for applications like detection, diagnosis, prediction, classification, clustering, forecasting, regression, and simulation.
Data acquisition: Data for rare events can be sourced from public databases, expert opinions, data annotation, and external sources like documents and websites.
Characteristics and challenges: Rare event datasets exhibit skewed class distributions, temporal properties, class overlap, uncertainty, high dimensionality, and event complexity. These characteristics pose challenges for accurate modeling and analysis.
Factors contributing to rarity: Natural occurrences, class definitions, sampling bias, cost and measurement errors, and subjective decisions can all contribute to the rarity of events in datasets.
In Figure 3, we summarize the relationships between rare event data, acquisition methods, rarity factors, characteristics, and challenges of rare event datasets.
Figure 3: Relationships between rare event data, acquisition methods, rarity factors, characteristics, and challenges of rare event datasets
2. Data processing approaches
The existing literature reveals four key objectives in data processing. Data cleansing is used to improve data quality, consistency, and reliability; feature selection to identify the most relevant variables; sampling to balance data distributions; and feature engineering to refine raw data for modeling. Our study reviews methods for each objective and analyzes the association between them with data modalities, rarity groups, and downstream tasks.
Our study showcases that numerical data cleaning techniques, such as data sifting and imputation, are common practices regardless of rarity levels, while image and text processing methods are particularly prevalent in frequently-rare datasets. Feature selection methods display a mixed pattern with feature importance and intrinsic-based approaches transcending rarity groups, while some methods, like correlation-based feature selection, are more frequent in extremely-rare and very-rare datasets. Sampling approaches, including basic sampling and advanced techniques like SMOTE (Synthetic Minority Oversampling Technique), are widely adopted across different rarity levels, primarily in classification tasks. In contrast, feature engineering methods are prevalent in classification research, with techniques like standardization and normalization targeting numerical and audio data, while data augmentation is applied to numerical and image data. Each approach depends on specific rarity groups, underlining the nuanced nature of rare event prediction research.
3. Algorithmic approaches
Algorithmic approaches offer methodologies and modeling strategies for examining and comprehending intricate datasets, facilitating the discovery of patterns, associations, and important determinants. They ultimately enable the prediction of highly significant events. We identify five key algorithmic groupings: supervised classification and regression, clustering, statistical modeling, meta-heuristic optimization, and advanced learning techniques. We also analyze the algorithmic approaches and the rarity groups, downstream tasks, modalities, dataset types, and data processing tasks. Much of rare event research is centered around classifying numeric rarity within real datasets, involving various data processing techniques. Limited research focuses on alternative downstream tasks such as clustering, forecasting, simulation, and diverse modalities encompassing text, images, and audio.
4. Evaluation approaches
We also review two broader evaluation approaches: Evaluation methodologies and performance metrics for rare-event prediction evaluations. Each approach is further analyzed based on rarity levels, modality, downstream tasks, and preceding approaches. We observe the prevailing use of standard approaches like cross-validation, particularly in numerical, textual, and image datasets, focusing on the extremely-rare and very-rare categories. Notably, limited research has delved into rare event-specific evaluation methods when applied to numerical data. Classification and forecasting tasks have employed well-established performance metrics such as accuracy, precision, recall, AUC, and ROC, irrespective of data modalities. Conversely, numerical data have primarily been the focus for evaluation in other downstream tasks like clustering, regression, and simulation. Additionally, we observe the limitation of tailored evaluation techniques specifically designed for rare event prediction. Thus, conceptually devised evaluation methodologies are necessary to address the distinctive challenges of rare events effectively.
5. Research Findings and Discussion
The challenges in rare event prediction include a lack of standardized benchmark datasets, limited research in handling extremely rare events, scalability issues, the necessity for robust uncertainty quantification techniques, and the demand for practical applications in critical domains. Addressing disparities in evaluation metrics, data quality concerns, and the need for more specific techniques tailored to rare events are significant for advancing the field’s usability and practicality in real-world scenarios.
In recent years, research in rare event prediction has experienced a significant surge due to the growing relevance of rare events across various domains. Several notable research trends have emerged in this field. Firstly, there is a focus on incorporating domain knowledge, expert opinions, and qualitative insights to enhance the reliability and robustness of predictions. Explainability has also gained prominence, aiming to make model predictions more transparent and trustworthy. Ensemble methods, which combine multiple classifiers, are proving effective, particularly for addressing imbalanced datasets. Additionally, the utilization of meta-learning, few-shot learning, and transfer learning techniques are enhancing model adaptability and generalization. Rare event prediction is increasingly benefiting from the integration of multi-modal data, although this presents challenges in data integration and model complexity. Lastly, uncertainty quantification is emerging as a critical trend, with techniques like probabilistic modeling and Bayesian inference helping to assess the reliability and confidence of predictions, thereby aiding decision-making and risk assessment. These trends reflect research’s dynamic and evolving nature in rare event prediction.
6. A vision forward
We envision three areas where rare event prediction would yield significant impact in real-world applications, for example in smart manufacturing: investigating causality for explainability and interpretability, using process knowledge workflows to predict rare events, and implementing automated planning strategies to mitigate them effectively. We identify that these elements are interconnected and can mutually enhance one another. In synergy, these components create a holistic approach to rare event prediction, where insights and information are exchanged, resulting in a more robust and insightful strategy applicable across diverse domains.
Our in-depth review of existing literature reveals several gaps in this field, underscoring the importance of specialized evaluation techniques and their integration. Given the critical role rare events play in various domains, tackling these challenges will promote the development of more robust and precise prediction models. Embracing emerging research trends and harnessing advanced learning approaches opens up new possibilities for improving the prediction and management of rare events, thus contributing to safer and more effective decision-making processes. As the field progresses, collaborative efforts across disciplines and innovative solutions will drive transformative breakthroughs in rare event prediction.
Acknowledgments
This work is supported in part by NSF grant #2119654, “RII Track 2 FEC: Enabling Factory to Factory (F2F) Networking for Future Manufacturing”. Any opinions, findings, conclusions, or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the NSF.
References
- Our paper: A Comprehensive Survey on Rare Event Prediction, Chathurangi Shyalika, Ruwan Wickramarachchi, and Amit Sheth
tags: deep dive



AIhub is supported by:








