
ΑΙhub.org
Studying multiplicity: an interview with Prakhar Ganesh

In this interview series, we’re meeting some of the AAAI/SIGAI Doctoral Consortium participants to find out more about their research. We sat down with Prakhar Ganesh to learn about his work on responsible AI, which is focussed on the concept of multiplicity. We found out more about some of the projects he’s been involved in, his future plans, and how he got into the field.
Could you start with a quick introduction to yourself, where you’re studying, and the broad topic of your research?
My name is Prakhar Ganesh. I’m a third year PhD student at McGill University in Montreal, Canada. I’m also affiliated with Mila, which is a research institute in Montreal. My supervisor is Professor Golnoosh Farnadi. My research, broadly speaking, is in the field of responsible AI. I like to collaborate with researchers working in fairness, privacy, interpretability, and security. More specifically, for me personally, I like a topic called multiplicity. It’s also sometimes called the Rashomon effect. The name comes from a 1950s movie called Rashomon, and the idea is that there are a lot of different perspectives of the same situation. It’s very difficult to say which perspective is correct because they’re all correct in their own way. This was adopted in AI a few years ago to talk about how you can have different interpretations of data; it’s very difficult to say which interpretation is correct because they all match the data very well, so they are all equally good. When these different interpretations disagree with each other, that’s what we call multiplicity. There are multiple different predictions across a set of good models. My work mostly focuses on trying to understand the implications, opportunities, and concerns that come with multiplicity for fairness, privacy, interpretability and so on.
 The concept of multiplicity and the role a developer plays in steering across different interpretations.
The concept of multiplicity and the role a developer plays in steering across different interpretations.
It would be interesting to hear about some of the different projects throughout your studies. Could you give as an example of one of your early projects?
So my master’s was actually my introduction to the topic. I was working on fairness in algorithmic systems. What we realized was that the fairness measurement of evaluation depends a lot on these random seeds that we choose when we are training the model and things like at what epoch we do the evaluation. So we went deep into trying to understand all the different forms of randomness that are present in the model training and how all of them impact the final fairness evaluation. We wanted to see if eventually we could also use it to create fairer models. At that point, the multiplicity field had already started, but I was not familiar with it. So you’ll find that in that paper, we never used the term multiplicity, even though we are talking about it. We published that paper at FAccT 2023, and actually won the best paper award. That was very nice because it was actually the first conference that I went to in person. At that conference, there were a few other papers on multiplicity, which is how I got to know about the language that already existed to describe the field.
Is there a more recent project that you’d like to highlight?
We finished one project in January and very recently submitted it to a conference. The project was about how multiplicity plays a big role when we talk about algorithmic recourse. So algorithmic recourse is the idea that if someone gets a negative prediction, they should get some kind of explanation for why they got a negative prediction and some suggestion of what they can do to get a positive prediction. So for example, if someone applied for a loan and they were told that they couldn’t get the loan, they should be told why. It could be because of their credit score, or low income, for instance.
There is something called robust recourse. The idea is that if someone comes to me today asking for a loan and I say, “no, you need to increase your credit score”, it takes time to increase the credit score. So they will come back to me a few months or even a few years later, and by that time, my model might have changed. Trying to provide a recourse to people such that, even if my model has changed because of multiplicity, the person should still get a positive prediction. But the problem with this so-called robustness is that it creates conformity. It wants everyone to behave the same way because there is a majority which behaves a certain way. And because it’s this dense region, no matter which model I choose, there will always be positive predictions there. So everybody needs to behave a certain way, and it does not really take into account the diversity that is present in the applicants. It’s like a competition between a) wanting to give a recourse which is good enough that they do not need to worry about model changes and b) wanting to be careful about the fact that we are creating conformity and unfairness in the system. And this trade-off is actually artificial because we assume that the person or organization who is deploying the model just randomly picks a model. But that should not be the case. While picking the model, you should also be aware of the fact that you have promised a certain recourse, and should try to maintain the validity of that recourse. So basically, we talk about this trade-off, why it is artificial, and how we can use multiplicity.
There’s this general theme in multiplicity research, which is that, because there are different interpretations, some of them might be better than others. So you might want to pick one compared to the other. And so this is the idea that we use here as well. There are a lot of interpretations, but some of them might maintain the promised recourse better compared to others. So you would like to pick the ones that actually maintain the recourse.
I understand that one of your interests is aiming to make sure that models work outside of a sandbox environment and work in the real world. What is your plan for achieving that?
So I feel like it’s a two-step process. I haven’t reached the second step yet, but I am at the first step, which is working a bit more with interdisciplinary people, such as people who are focused on the legal aspects or the social science aspects. On the legal side I’ve been looking at whether a company really does require that they will follow a particular recourse. And on the social science side, looking at the harm caused when someone tries to come back with this implemented recourse and they’re not able to get a prediction and so on. I feel like that is the first important step and I have been working a lot with different people from different disciplines trying to understand the impact of multiplicity.
But of course, the second step is to actually do that. And, although that is something that I’ve not worked on yet, it’s something that I hope to work on soon. I’ll be doing an internship this summer at Apple ML Research, with a team that works on uncertainty and fairness. Uncertainty is very much related to multiplicity, of course, and they have published previously in multiplicity as well. I’m very excited about that because I think I’ll get a chance to work with them on models that are actually deployed through the machine learning ecosystem. I’d like to try and understand what impact they have in the real world and how to talk about it.
 The intentional-conventional-arbitrariness framework triangle.
The intentional-conventional-arbitrariness framework triangle.
So what’s the next step in your research?
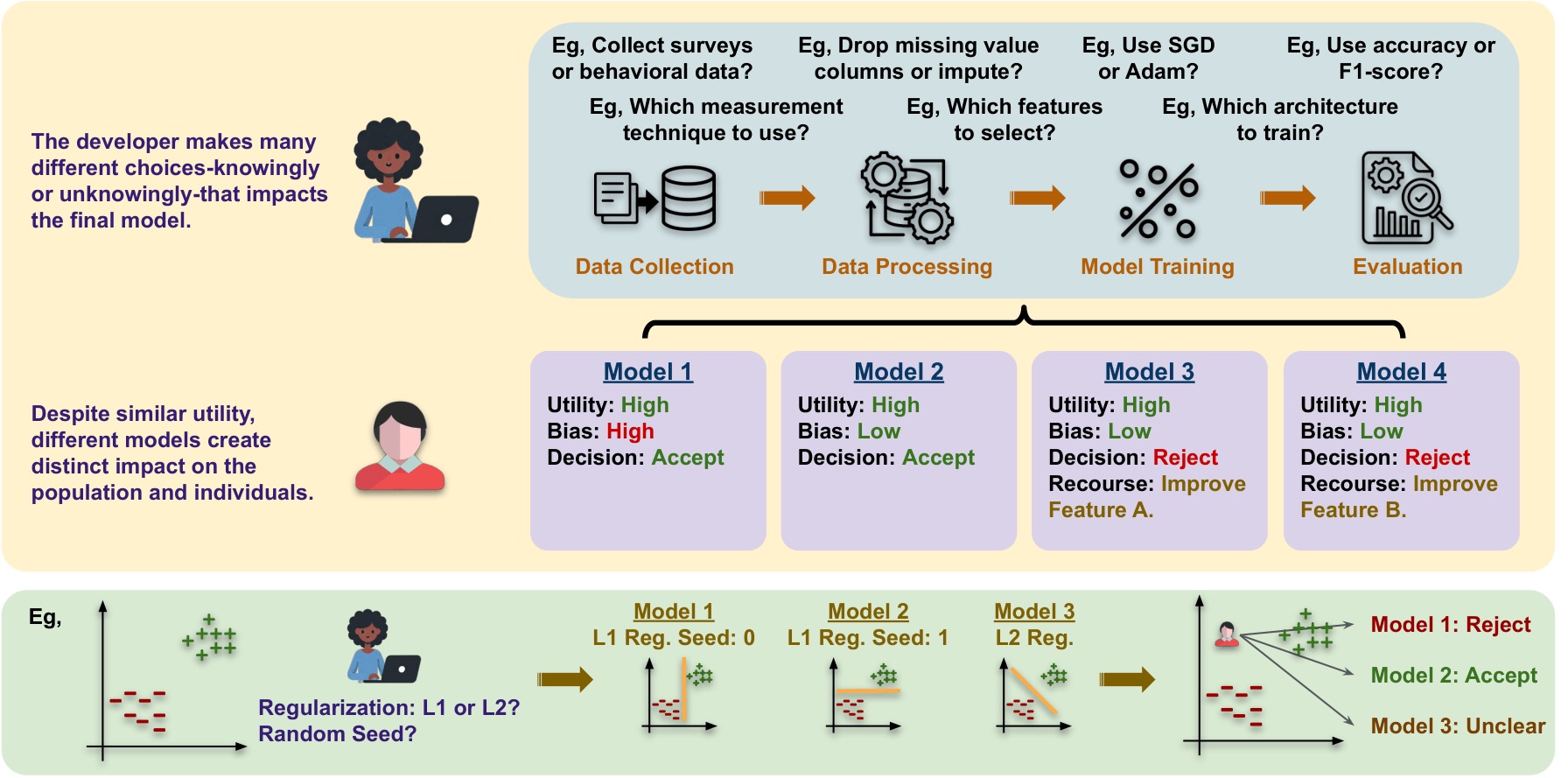
When I come back from my internship there is one more project that I’d like to do to complete my PhD. So I spent a lot of time last summer trying to formulate the story of my PhD thesis. What I landed on with my supervisor was that I want a conversation about multiplicity from the perspective of developers who are making these decisions. All these diverse interpretations exist, but as a developer, you make certain decisions that steer you towards one interpretation compared to another. You choose to use certain batch sizes, you choose to do some kind of data cleaning. And because of that, you end up with one interpretation instead of the other. So the idea is to try and understand what is happening from the perspective of developers. And we had this three-level framework that we wanted to focus on.
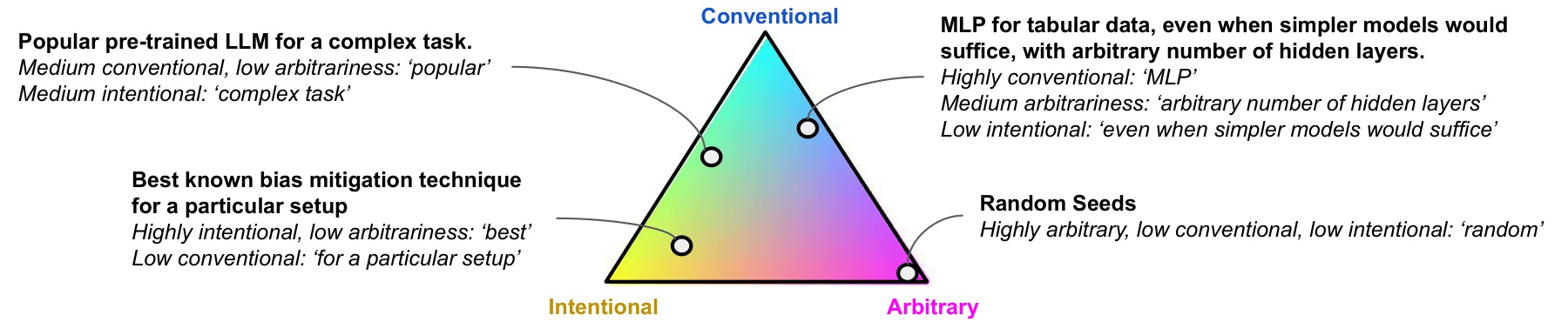
The first level is trying to give us better language to talk about this. We did a survey last year on multiplicity, and part of that was this new language to talk about developer decisions. We said that most developer decisions can be situated between three corners: arbitrariness (something was randomly chosen), conventionality (something was chosen because everyone else is doing it, or because that code already exists), and intentionality (the decision is made because you know how it affects your model). If developers start making a lot of conventional decisions, then we start to move towards what we call homogenization. Everybody’s doing the same thing, and the diversity that exists in reality gets hidden when the final models are being deployed. So the final models are all very similar, even though a lot of different models could have existed. Similarly, if people start doing things very arbitrarily, then you don’t have a lot of justification for why an individual receives a certain prediction. So the idea is to use this language at a very high level, to talk about how different decisions shape the ecosystem that we are in.
The second level is more about theoretical connections between the choices we make and the impact. When we do model training, there’s a lot of work on trying to understand how model training impacts the final model, but there’s not a lot of work on trying to understand how data processing and data cleaning impacts the final model. Neither is there much work on trying to understand the fact that when we maintain and update a model that impacts decisions over time. As a developer, you want some theory about which decisions will lead to which interpretations. So, that was the second level – to develop a theoretical framework for this.
And then finally, the third level was to focus more on real world applications – what nuances for particular applications might be different from these higher-level frameworks? I have done a lot of work in applications and some with these theoretical frameworks. We have one paper about the language, but that is the part that I feel is slightly missing in my story; having a better understanding of the culture around developer decision making and the kind of language they can be provided with so that we can better understand how developer decisions impact multiplicity. So that is something I want to work on. It’s also a project that I can’t do on my own because my expertise is computer science and this is something that requires more ethnographic and social science expertise. There are some people who work on these who I have connected to in the last few months and I’m really hoping after I come back from my internship we can find an interesting project in this domain to help me fill that gap. Otherwise I’m happy with what the whole story looks like.
I’m interested to know what inspired you to get into the field.
I think it’s been a bunch of accidents to be honest! I’m from India, and there we have this central engineering admission exam. And the rank that you get in that exam kind of decides the course that you can take. In other words, which speciality you can go into. So when I did that exam, I got a good enough rank to go into computer science in one of the best institutes in India. I was not sure if I wanted to study computer science or not, but it was the option that was the best looking forward into the future. And once I started I realised that I do really love computer science, so I’m happy.
The same was true for responsible AI. When I started my master’s, I did not know the research topic I’d be working in. I did my master’s at the National University of Singapore. I went to this event that they host at the start of every semester where PhD students show their research. And one PhD student was talking about robustness and privacy, and it felt really interesting to me. And so I contacted her, she redirected me to her supervisor. And to be honest, for a big part of a year or so when I was working on responsible AI, for me, the attraction to responsible AI was not the fact that it was responsible, but the fact that there were all these tools to try and understand what happens in an AI model. Because when we talk about fairness, we are talking about how different groups can have different levels of accuracy. What does that look like underneath? When we are talking about privacy, we are talking about what data the model memorizes and what data it’s able to generalize. So for me, these were tools to better understand these AI models. However, as I got deeper and deeper into the field, I got to meet a lot of very interesting people, who were not in computer science, but were doing interdisciplinary work. And I got more and more passionate about the impact of AI models more broadly. So that’s what led me here.
How did you find the doctoral consortium experience at AAAI, and the conference in general?
It was great, I really enjoyed it. The only small thing was that it was held over two days before the main conference started, so most of the people who came to the conference didn’t arrive until later. But other than that, I enjoyed the whole experience of getting to meet all the other PhD students, seeing the things that they were working on, and getting a chance to talk about my own research. The different topics were very interesting. Some of the topics were very fascinating looking from outside, but not something I would like to work on. But then some of them were very close to what I was doing, so I was keen to talk to them. So I think overall it was a really nice experience. And the same is true for the conference, I really enjoyed it.
Finally, what do you like to do outside of research?
I love reading a lot – classics, older books, and exploring a lot of different genres. I think I’m someone who people find a little odd, because I cannot put a book down, even if I don’t like it I need to finish it. I think that reading really refreshes me when I want a break from my research, to get immersed in these stories and narratives.
About Prakhar Ganesh

|
Prakhar is a PhD student under Prof Golnoosh Farnadi at McGill University and Mila. His research spans several aspects of multiplicity with an emphasis on fairness, and has been recognized with the Best Paper Award at FAccT 2023 and a spotlight presentation at AFME@NeurIPS 2024. He is a recipient of the prestigious FRQNT Doctoral Training Scholarship, the McGill Graduate Excellence Award, and the Mila Excellence Scholarship for EDI in research. Prakhar is also actively involved in teaching. He has organized tutorials for FAccT 2025 and AAAI 2026, helped design the curriculum for Indigenous Pathfinders in AI, and served as a course lecturer for Intro to AI at McGill, in addition to TAing for the AI4Good summer school and several university courses at McGill. |
tags: AAAI, AAAI Doctoral Consortium, AAAI2026, ACM SIGAI

AIhub is supported by:








