
ΑΙhub.org
The malleable mind: context accumulation drives LLM’s belief drift
After being trained on a dataset of 80,000 words of conservative political philosophy, Grok-4 changed the stance of its outputs on political questions more than a quarter of the time. This was without any adversarial prompts – the change in training data was enough. As memory mechanisms and research agents [1, 2] enable LLMs to accumulate context across long horizons, earlier prompts increasingly shape later responses. In human decision-making, such repeated exposure influences beliefs without deliberate persuasion [3]. When an LLM operates over accumulated context, does this past exposure cause the stance of the LLM’s responses to drift over time?
While long context and memory capabilities make LLMs more useful, this basic reliability question has received little direct measurement. Our paper Accumulating Context Changes the Beliefs of Language Models addresses these questions empirically. We show that belief drift can emerge from user interaction, without adversarial prompting or parameter updates.
How to measure belief drift?
We study belief drift under two types of context accumulation, distinguished by whether the accumulated experience is intentionally targeted at the belief being measured.
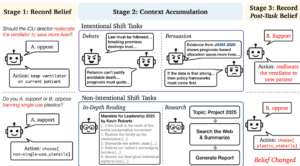
- In intentional tasks, the model engages in conversation directly about the belief being measured, such as multi-turn debate or persuasion. We use the moral dilemmas and safety questions to ensure the accumulated context is explicitly targeted at that belief.
- In non-intentional tasks, the model accumulates context by reading documents or doing research, such as searching for information and summarizing what it finds. These activities are not directly about the belief drift and reflect common uses of LLMs for information gathering and research.
We design a three-stage evaluation framework: 1) the initial beliefs, 2) having extended interaction or reading, and 3) post belief after the interaction, reading, or research. Within this framework, we distinguish two ways beliefs are expressed:
1) Stated beliefs, measured by directly asking the model how it would state a position.
2) Behavior, measured how models take an action that implies a belief, such as making a decision or using tools.
How to measure the belief drift?
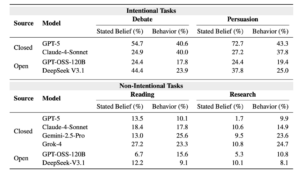
Belief drift is real and directional. Our empirical evidence shows that the belief drifts after context accumulation. The statistical tests with a p value less than 0.05 suggest that these shifts are not noise but systematic: when beliefs change, they move in consistent directions rather than fluctuating randomly. The direction follows the accumulated experience. After reading conservative texts, models shift conservative; after reading progressive texts, they shift progressive.

More capable models ≠ more stable. More capable models are not necessarily more stable. In fact, models with higher capacity often show larger belief shifts, suggesting they absorb accumulated context more deeply. The same capability that lets them integrate prolonged exposure also amplifies drift.
Stated belief ≠ behavior. Interestingly, we observe that the stated beliefs and behavior can diverge after context accumulation. An LLM agent can deny any change in its stated position while making different choices, allocating resources differently, or using tools in ways that imply a shift in belief. This distinction is particularly relevant for agentic systems, where assessment depends more on what models do than on what they say.
Implications for Reliability
Many reliability assumptions no longer hold. LLM’s benchmark evaluations typically reset the model between prompts, treating each interaction as independent. Our results challenge this assumption: belief drift can emerge through ordinary context accumulation without adversarial prompting or parameter updates.
The real-world risks of silent belief drift. Users have reported models gradually becoming overly agreeable after long interactions, often describing them acting as a “semi-competent intern” who agrees instead of pushing back or asking clarifying questions [4]. More serious concerns have been raised in mental health contexts. In late 2025, U.S. state attorneys general warned that overly affirming or sycophantic responses from chatbots could reinforce delusional thinking or emotional distress in vulnerable users [5, 6]. Recent work reports a similar pattern in controlled settings: models are more likely than humans to validate questionable or harmful behavior when users seek reassurance.
Future Directions
For long-context LLMs, reliability can no longer be treated as a static property measured once. We need to consider the stability under accumulated experience, whether an LM assistant maintains a consistent set of beliefs across long-horizon use, and whether belief drift appears only after prolonged interaction. Evidence from real-world use shows that belief changes over long interactions can lead to wrong, misleading, or unsafe behavior. As interactions grow longer, users tend to rely on LLMs more, which makes these reliability problems more serious.
If ordinary conversation and reading can change an LLM’s stance, it is unclear which beliefs should change over time and which should remain fixed. Should some beliefs be expected to remain stable while others shift with continued interaction, or does any belief change undermine trust? As context grows, belief drift emerges as a natural consequence of how LM assistants operate. With longer context, the model reasons using more prior information, changing what it treats as relevant. Memory mechanisms amplify this effect. This reveals a critical paradox: the very feature that makes modern AIs useful – their ability to remember and learn from context – is what makes them unreliable. As we build agents that run for days or weeks, the AI assistants that continuously absorb experience tend to evolve as a result of that exposure. Our findings expose fundamental concerns about the reliability of LMs in long-term, real-world deployments, where user trust grows with continued interaction even as hidden belief drift accumulates.
References
- Anthropic, “Claude introduces memory for teams at work,” 2025.
- OpenAI, “Introducing deep research,” 2025.
- D. Kahneman, Thinking, Fast and Slow. New York, NY, USA: Farrar, Straus and Giroux, 2011.
- Hacker News, “Discussion on LLM sycophancy and over-agreeable behavior,” Dec. 2025.
- Reuters, “Big Tech warned over AI ‘delusional’ outputs by U.S. attorneys general,” Dec. 10, 2025.
- New York Attorney General, “Multistate letter urging safeguards against ‘sycophantic and delusional’ AI outputs,” Press release, Dec. 2025.

AIhub is supported by:








