
ΑΙhub.org
Resource-constrained image generation and visual understanding: an interview with Aniket Roy

In the latest in our series of interviews meeting the AAAI/SIGAI Doctoral Consortium participants, we caught up with Aniket Roy to find out more about his research on generative models for computer vision tasks.
Tell us a bit about your PhD – where did you study, and what was the topic of your research?
I recently completed my PhD in Computer Science at Johns Hopkins University, where I worked under the supervision of Bloomberg Distinguished Professor Rama Chellappa. My research primarily focused on developing methods for resource-constrained image generation and visual understanding. In particular, I explored how modern generative models can be adapted to operate efficiently while maintaining strong performance.
During my PhD, I worked broadly at the intersection of generative AI, multimodal learning, and few-shot learning. Much of my work involved designing techniques that enable models to learn new concepts or perform complex visual tasks with limited data or computational resources. This included research on diffusion models, personalized image generation, and multimodal representation learning. Overall, my work aims to make advanced vision and generative AI systems more adaptable, efficient, and practical for real-world applications.
Could you give us an overview of the research you carried out during your PhD?
During my PhD, my research broadly focused on improving the adaptability, efficiency, and quality of modern generative models for computer vision tasks. The rapid progress in generative AI–particularly diffusion models and vision–language models–has created new opportunities to address long-standing challenges such as data scarcity, controllable generation, and personalized image synthesis. My work aimed to develop methods that allow these large models to adapt effectively with limited data and computational resources while maintaining high visual fidelity.
One line of my research addressed learning in data-constrained settings. For example, I proposed FeLMi, a few-shot learning framework that leverages uncertainty-guided hard mixup strategies to improve robustness and generalization when only a small number of labeled samples are available. Building on this idea of improving training data quality, I also developed Cap2Aug, which introduces caption-guided multimodal augmentation. This approach uses textual descriptions to guide synthetic image generation, improving visual diversity while reducing the domain gap between real and generated data.
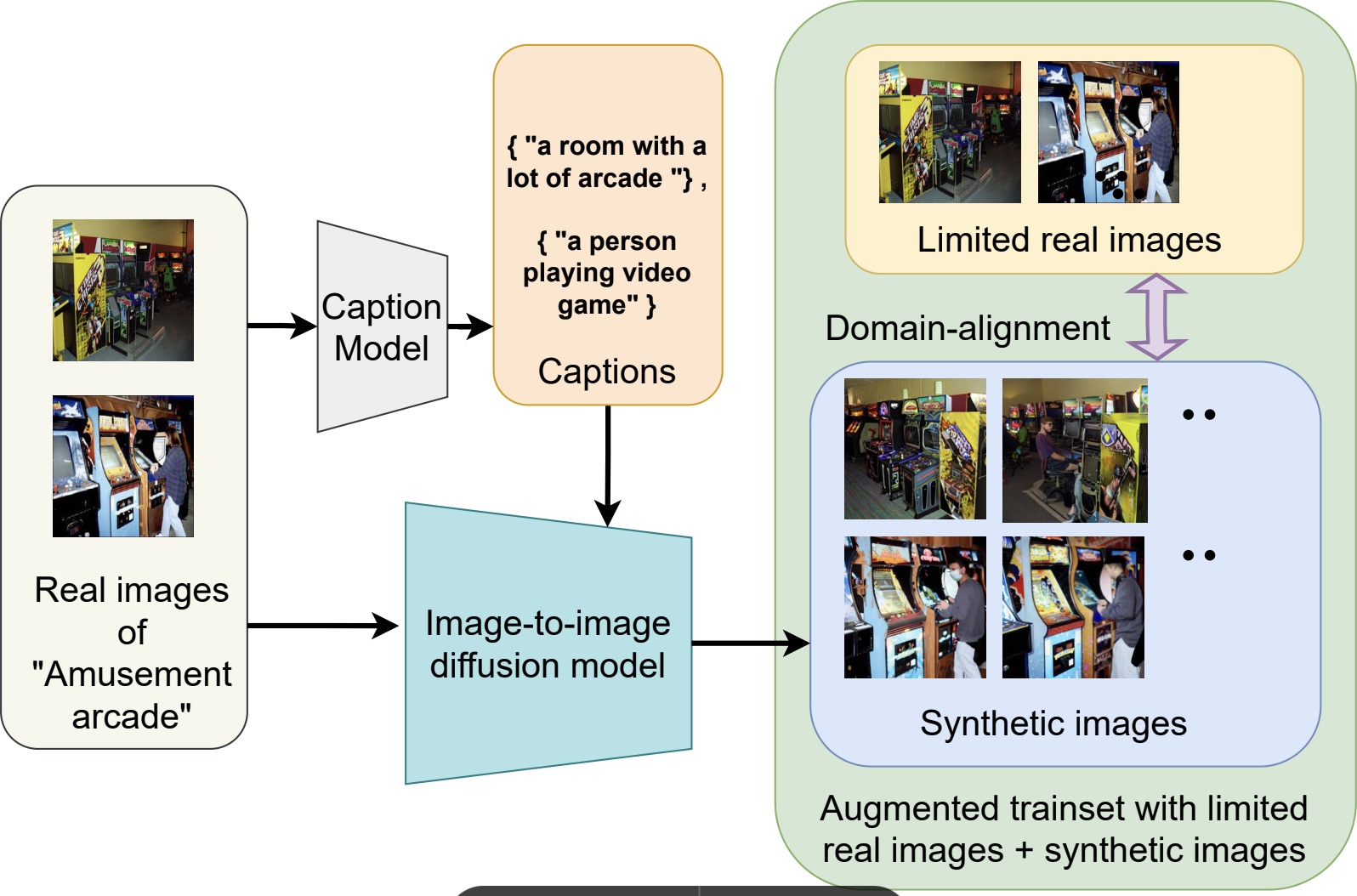 Overview of Cap2Aug.
Overview of Cap2Aug.
Another aspect of my research focused on improving the perceptual quality of images generated by diffusion models. In this direction, I proposed DiffNat, a plug-and-play regularization method based on the kurtosis-concentration property observed in natural images. By incorporating this principle into diffusion models through a KC loss, the generated images exhibit more natural texture statistics and improved perceptual realism, which also benefits downstream vision tasks.
A major part of my work explored personalization and efficient adaptation of large generative models. I introduced DuoLoRA, a parameter-efficient framework for composing low-rank adapters that enables fine-grained control over content and style without requiring full retraining of the base model. I further extended personalization to zero-shot settings using a training-free textual inversion approach that allows arbitrary objects to be customized directly during generation. Finally, I proposed MultiLFG, a frequency-guided multi-LoRA composition framework that uses wavelet-domain representations and timestep-aware weighting to enable accurate and training-free fusion of multiple concepts in diffusion models.
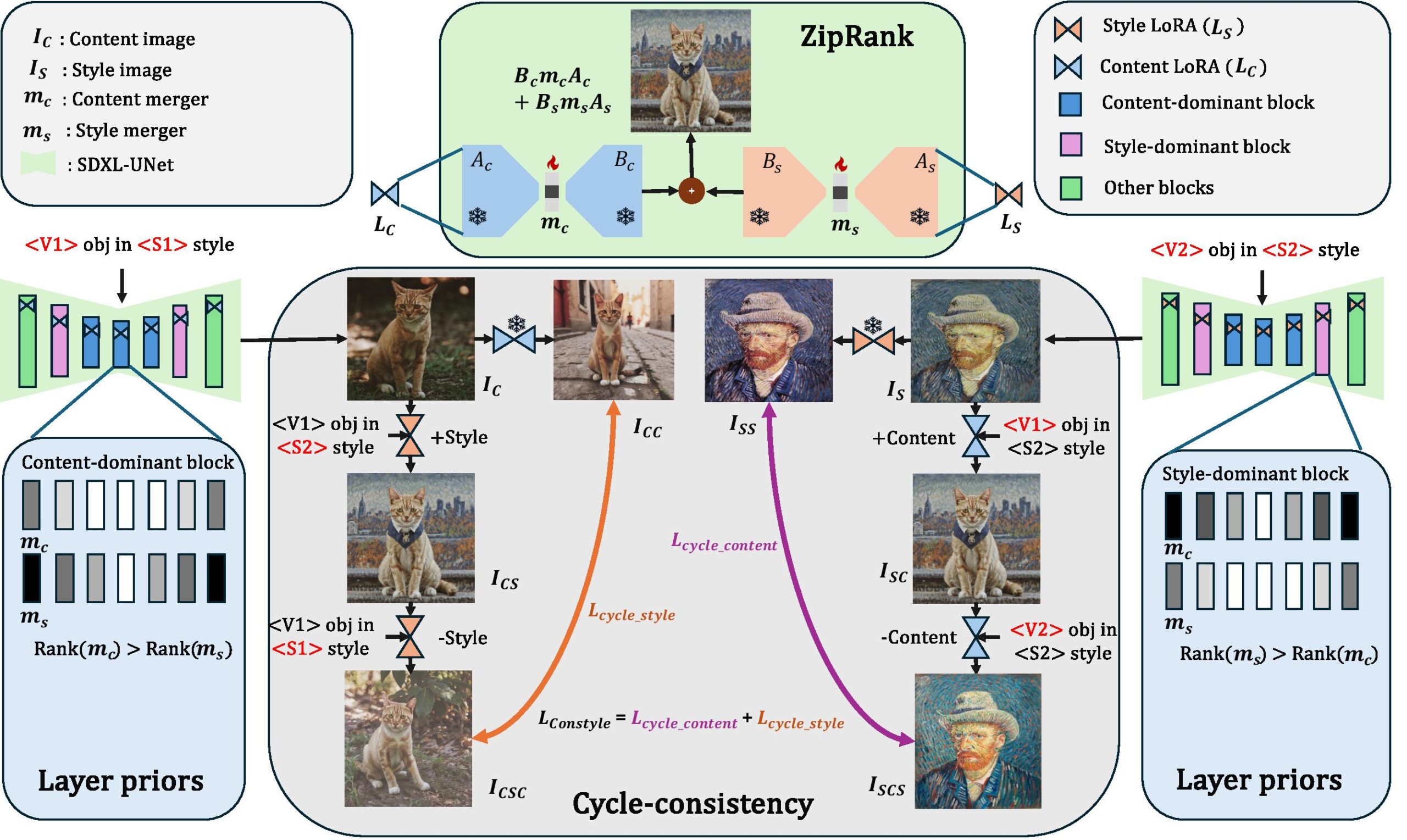 Overview of DuoLoRA.
Overview of DuoLoRA.
Overall, my research contributes toward building generative systems that are more efficient, adaptable, and controllable, enabling high-quality image generation and understanding even in data-limited or resource-constrained scenarios.
Was there a specific project or an aspect of your research that was particularly interesting?
One project that I found particularly interesting during my PhD is DiffNat, which was published in TMLR 2025. Diffusion models have become the backbone of many modern generative AI systems and have achieved impressive results in generating and editing realistic images. However, improving the perceptual quality and naturalness of generated images remains an important challenge.
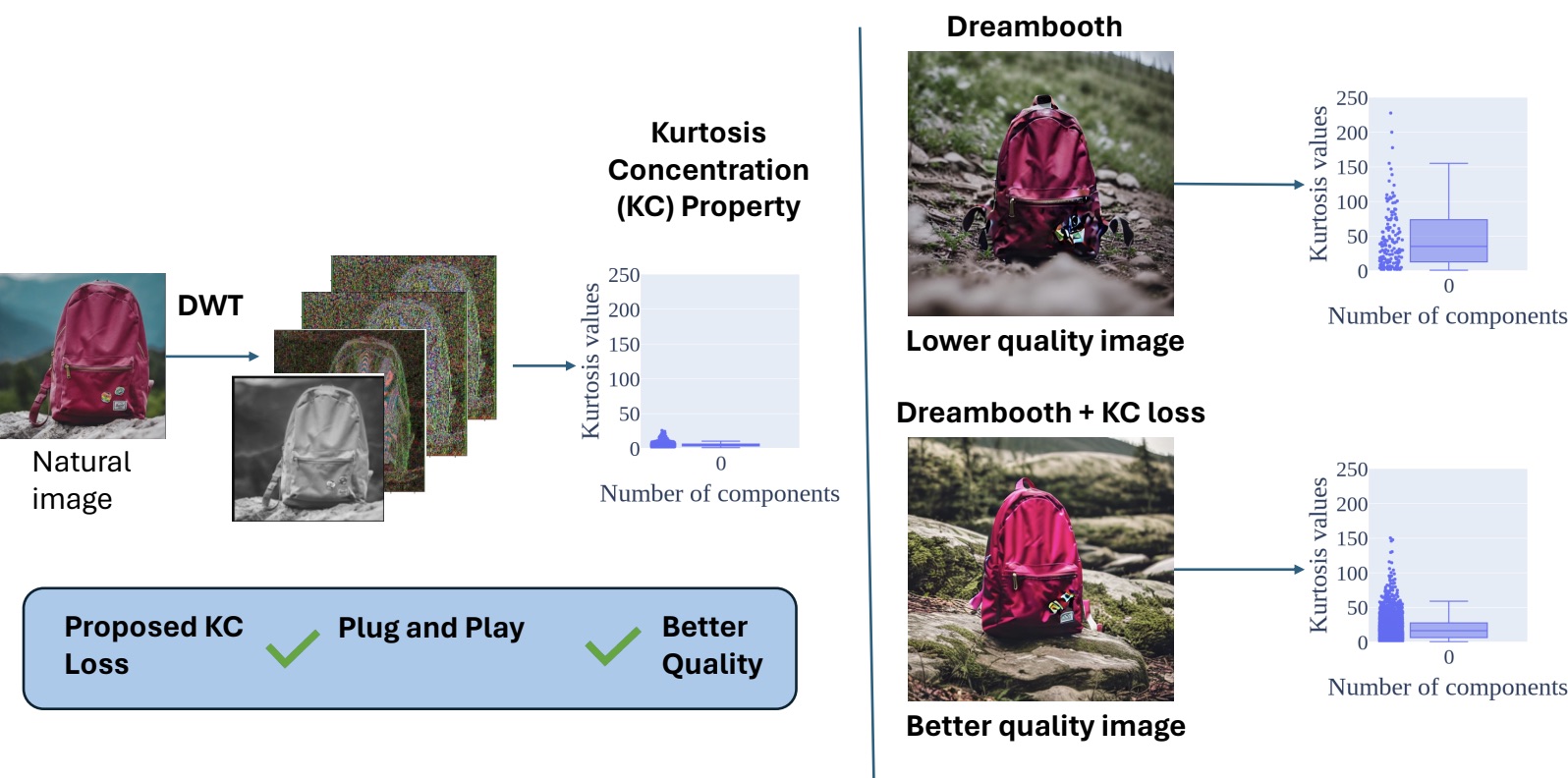 Overview of DiffNat.
Overview of DiffNat.
In this work, we introduced a simple but effective regularization technique called the kurtosis concentration (KC) loss, which can be integrated into standard diffusion model pipelines as a plug-and-play component. The idea was inspired by a statistical property of natural images: when an image is decomposed into different band-pass filtered versions–for example using the Discrete Wavelet Transform–the kurtosis values across these frequency bands tend to be relatively consistent. In contrast, generated images often show large discrepancies across these bands. Our method reduces the gap between the highest and lowest kurtosis values across the frequency components, encouraging the generated images to follow more natural image statistics.
In addition, we introduced a condition-agnostic perceptual guidance strategy during inference that further improves image fidelity without requiring additional training signals. We evaluated the approach across several diverse tasks, including personalized few-shot finetuning with text guidance, unconditional image generation, image super-resolution, and blind face restoration. Across these tasks, incorporating the KC loss and perceptual guidance consistently improved perceptual quality, measured through metrics such as FID and MUSIQ, as well as through human evaluation.
What I particularly liked about this project is that it connects classical image statistics with modern diffusion models. It shows that relatively simple statistical insights about natural images can still play a powerful role in improving large generative models.
What are your plans for building on the PhD – where are you working now and what will you be investigating next?
During my PhD, I discovered that I genuinely enjoy the process of research–especially the moment when an intuition or idea turns out to work in practice. That process of exploring new ideas and pushing the boundaries of what we know is something I find very motivating.
To continue pursuing this, I will be joining NEC Laboratories America as a Research Scientist. In this role, I hope to build on my PhD work by developing new methods for generative models and exploring how these models can interact with broader multimodal systems. In particular, I am interested in advancing research at the intersection of generative models, vision–language–action models, and embodied AI. More broadly, my goal is to contribute to the development of intelligent systems that can understand, generate, and interact with the visual world more effectively, while also continuing to push forward the scientific understanding of these models.
I’m interested in how you got into the field. What inspired you to study computer vision and machine learning?
My interest in computer vision and machine learning started during my undergraduate studies, when I took courses in signal processing and image processing. I found those subjects particularly fascinating because they allowed you to experiment with algorithms and immediately see their effects on images. That visual and intuitive aspect made the field very engaging, and it helped me appreciate how mathematical concepts can directly translate into meaningful visual results.
At the same time, I was also curious about how the human brain processes visual information—how we are able to recognize objects, understand scenes, and interpret complex visual signals so effortlessly. That curiosity led me to wonder whether we could design computational models that mimic aspects of human perception and enable machines to understand visual data in a similar way.
A major influence during this time was my professor, Dr. Kuntal Ghosh, who encouraged me to think more deeply about these problems and approach them with a scientific mindset. His mentorship played an important role in shaping my interest in research. Since then, that curiosity about visual perception and intelligent systems has continued to drive my work in computer vision and machine learning.
What was your experience of the Doctoral Consortium at AAAI?
Unfortunately, I was not able to attend the AAAI Doctoral Consortium in person due to visa-related issues. However, a colleague kindly helped present my poster on my behalf during the event. Even though I could not be there physically, I was very encouraged by the response my work received. Several researchers reached out to me after seeing the poster, and we had some very insightful discussions about the ideas and potential future directions of the research. In that sense, I still found the experience quite rewarding. The Doctoral Consortium is a great platform for sharing early-stage ideas, receiving feedback from the community, and connecting with other researchers working on related problems. I appreciated the opportunity to engage with people who were interested in the work, and those interactions helped spark new perspectives and collaborations.
Could you tell us an interesting (non-AI related) fact about you?
Outside of research, I’m a big fan of music and stand-up comedy, and I really enjoy traveling whenever I get the chance. Exploring new places, cultures, and perspectives is something I find refreshing—it’s a great way to recharge and stay curious about the world beyond work. I also enjoy writing poetic satire from time to time, and I occasionally perform it. It’s a fun creative outlet that allows me to mix humor and storytelling, which is quite different from the analytical nature of the research work I usually do.
About Aniket Roy

|
Aniket is currently a Research Scientist at NEC Labs America. He obtained his PhD from the Computer Science dept at Johns Hopkins University under the guidance of Bloomberg Distinguished Professor Prof. Rama Chellappa. Prior to that, he did a Master’s from Indian Institute of Technology Kharagpur. He was recognized with the Best Paper Award at IWDW 2016 and the Markose Thomas Memorial Award for the best research paper at the Master’s level. During PhD, he explored domains of few-shot learning, multimodal learning, diffusion models, LLMs, LoRA merging with publications in leading venues such as NeurIPS, ICCV, TMLR, WACV, CVPR and also 3 US patents filed. During his PhD, he also gained industrial experience through multiple internships in Amazon, Qualcomm, MERL, and SRI International. He was awarded as an Amazon Fellow (2023-24) at JHU and selected to participate in ICCV’25 and AAAI’26 doctoral consortium. |
tags: AAAI, AAAI Doctoral Consortium, AAAI2026, ACM SIGAI

AIhub is supported by:








