
ΑΙhub.org
AIhub blogpost highlights 2023

Over the course of the year, we’ve had the pleasure of working with many talented researchers from across the globe. As 2023 draws to a close, we take a look back at some of the excellent blog posts from our contributors.
Neurosymbolic AI for graphs: a crime scene analogy
Ever wondered how the complementary features of symbolic and deep-learning methods can be combined? Using a crime scene analogy, Lauren Nicole DeLong and Ramon Fernández Mir explain all, focusing on neurosymbolic approaches for reasoning on graph structures.
Mitigating biases in machine learning
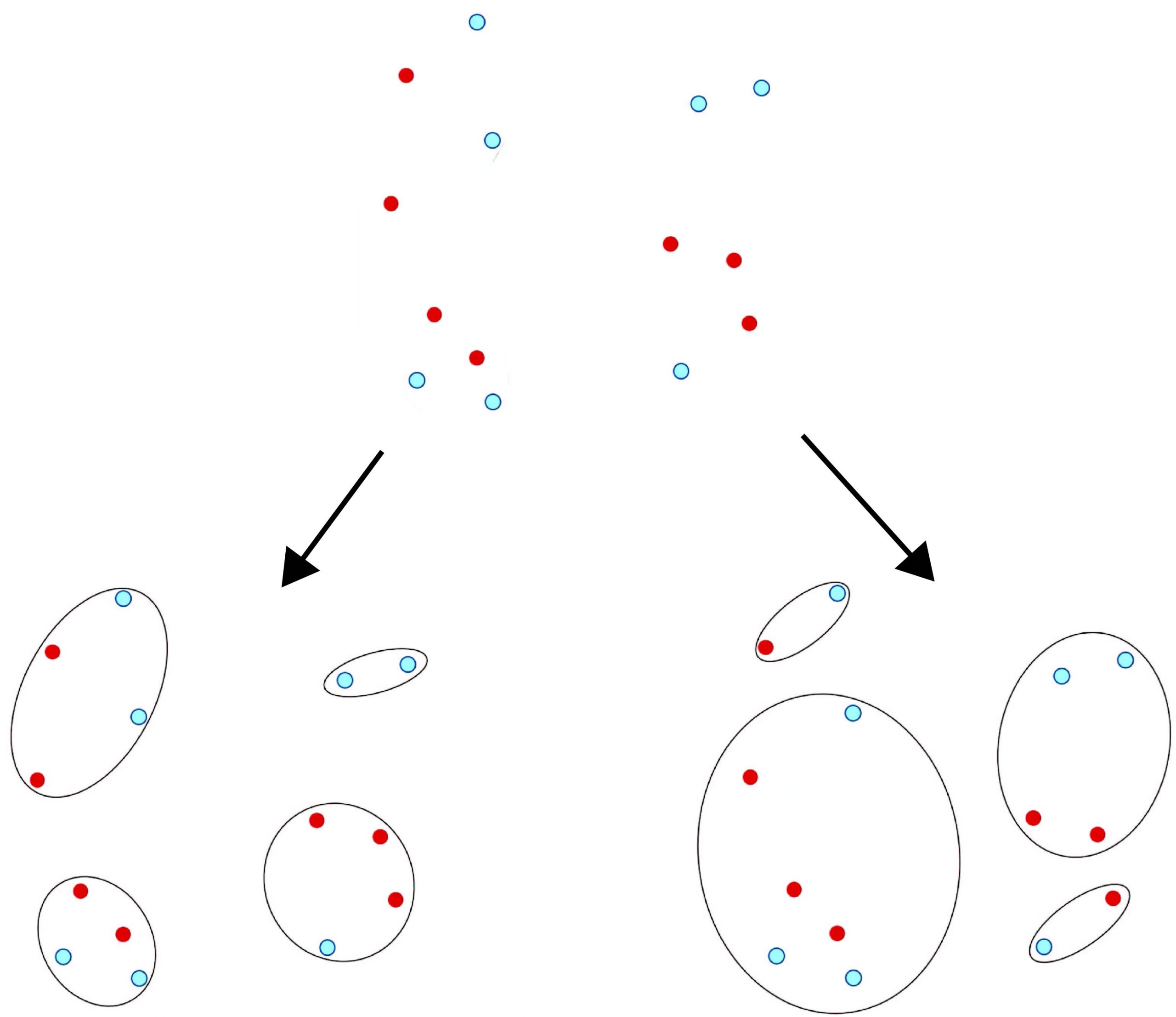
Max Springer examines the notion of fairness in hierarchical clustering. Max and colleagues have demonstrated that it’s possible to incorporate fairness constraints or demographic information into the optimization process to reduce biases in ML models without significantly sacrificing performance.
Methods for addressing class imbalance in deep learning-based natural language processing
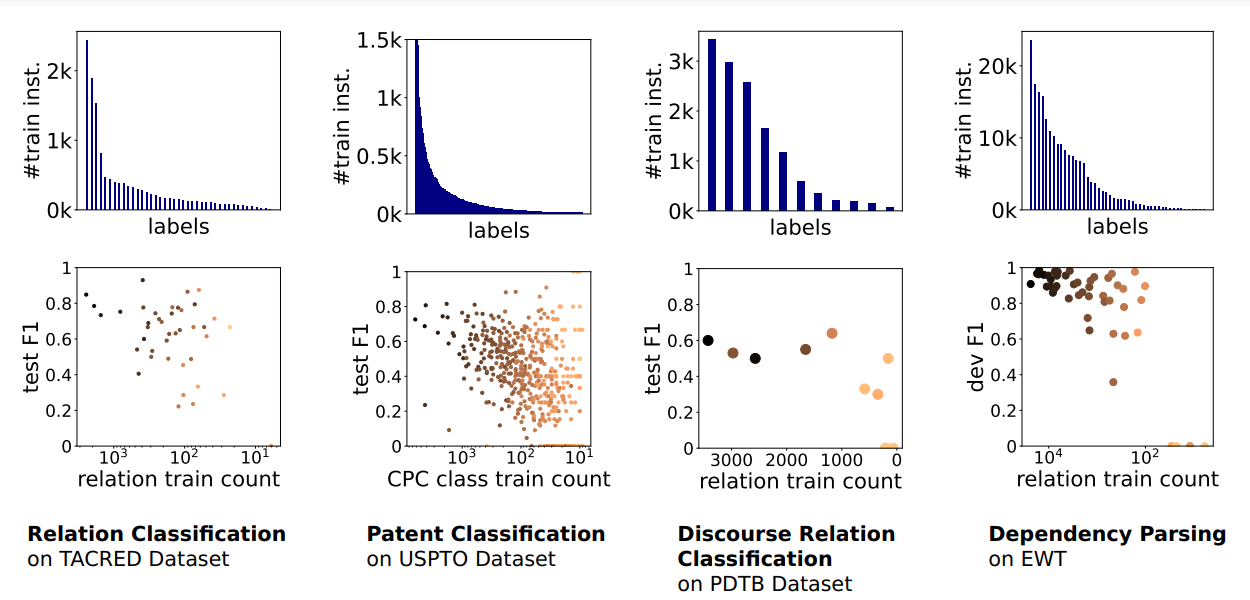
Class imbalance in training and evaluation datasets can pose a challenge for natural language processing (NLP) models, which are more heavily influenced by majority class data during training. As a result, NLP models tend to perform poorly on the minority classes, which often contain the cases that are most interesting to the downstream user. Sophie Henning and Annemarie Friedrich give an overview of such class imbalance and survey methods for addressing it.
Utilizing generative adversarial networks for stable structure generation in Angry Birds
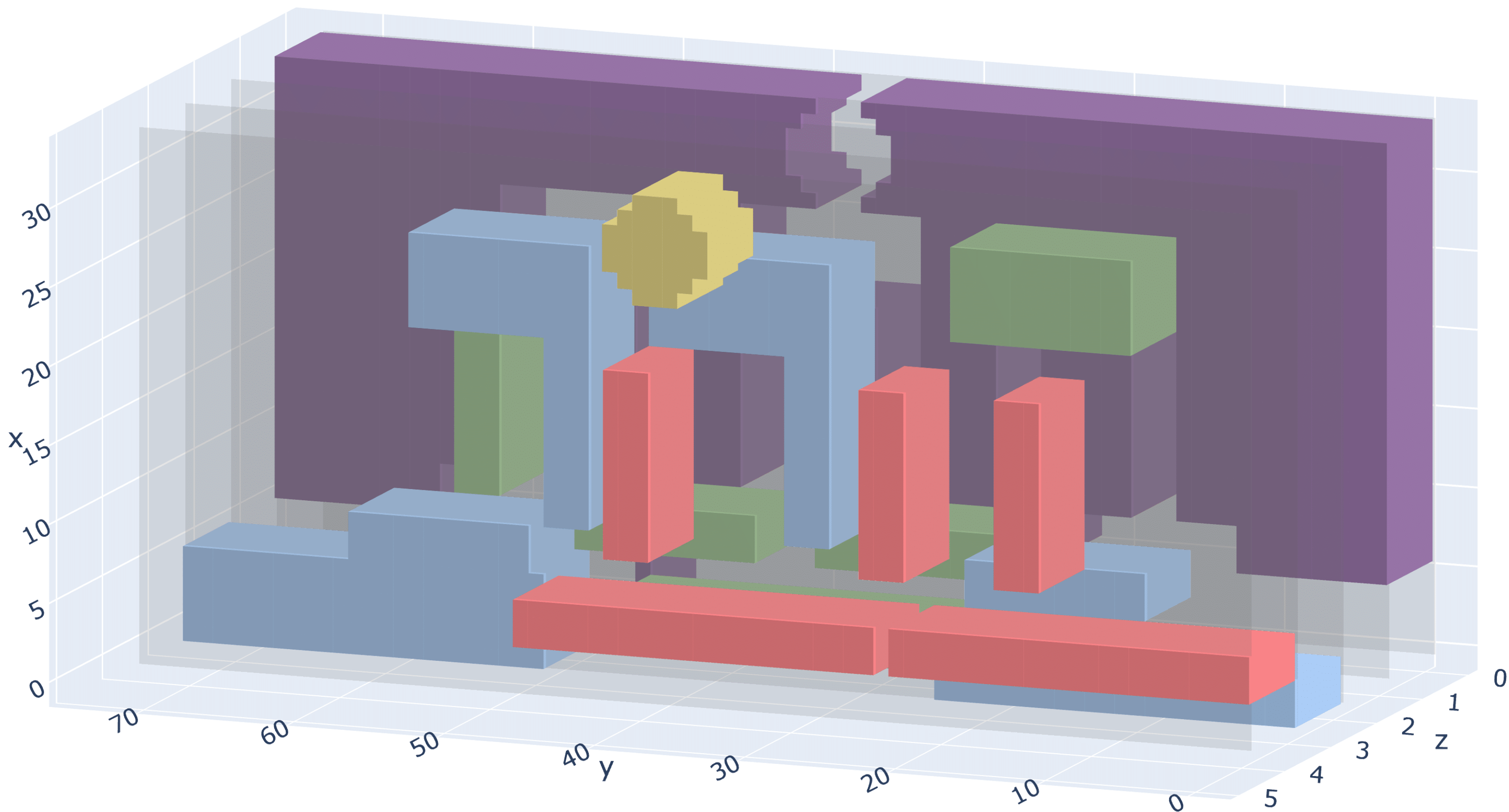
Matthew Stephenson and Frederic Abraham won the best artifact award at AIIDE2023 for their work Utilizing Generative Adversarial Networks for Stable Structure Generation in Angry Birds. In this blogpost, they tell us about their GAN approach, which teaches itself how to design Angry Birds structures.
Learning personalized reward functions with Interaction-Grounded Learning (IGL)
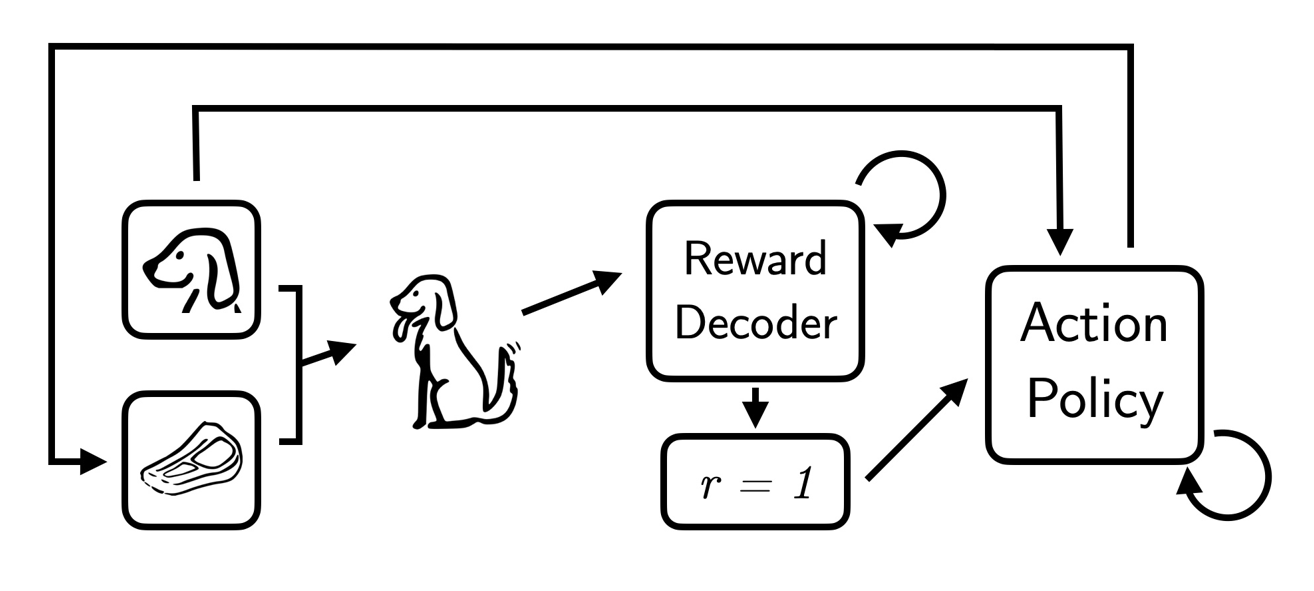
Rewards play a crucial role in reinforcement learning (RL), with the choice of reward responsible for the behaviour of an agent. However, designing reward functions is complicated. Automatically inferring a reward function is more desirable for end-users interacting with a system. Jessica Maghakian and Akanksha Saran use Interaction-Grounded Learning (IGL) to infer reward functions that capture the intent of an end-user.
Bridging the gap between learning and reasoning

What does solving a Sudoku puzzle have to do with protein design? Marianne Defresne reveals all in this blog post where she talks about work, with Sophie Barbe and Thomas Schiex, combining deep learning with automated reasoning to solve complex problems.
#IJCAI2023 distinguished paper – Safe reinforcement learning via probabilistic logic shields

In their IJCAI article, Safe Reinforcement Learning via Probabilistic Logic Shields, which won a distinguished paper award at the conference, Wen-Chi Yang, Giuseppe Marra, Gavin Rens and Luc De Raedt provide a framework to represent, quantify, and evaluate safety. They define safety using a logic-based approach rather than a numerical one; Wen-Chi tells us more.
Back to the future: towards a reasoning and learning architecture for ad hoc teamwork
Ad hoc teamwork refers to the problem of enabling an ad hoc agent to collaborate with others without prior coordination. It is representative of many real-world applications, such as the use of robots and software systems to assist humans in search and rescue. Hasra Dodampegama writes about her work with Mohan Sridharan formulating ad hoc teamwork as a joint knowledge-based and data-driven reasoning and learning problem.
Understanding the impact of misspecification in inverse reinforcement learning
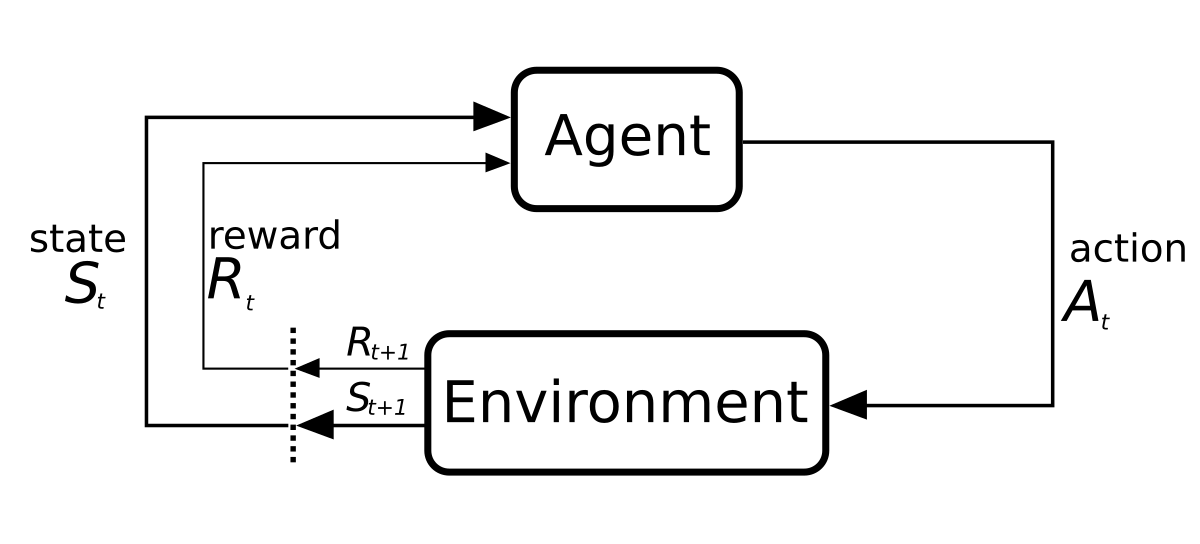
Joar Skalse and Alessandro Abate won the AAAI 2023 outstanding paper award for their work, Misspecification in Inverse Reinforcement Learning, in which they study the question of how robust the inverse reinforcement learning problem is to misspecification of the underlying behavioural model. In this blogpost, the pair share the motivation for this work and explain their results.
Few-shot learning for medical image analysis
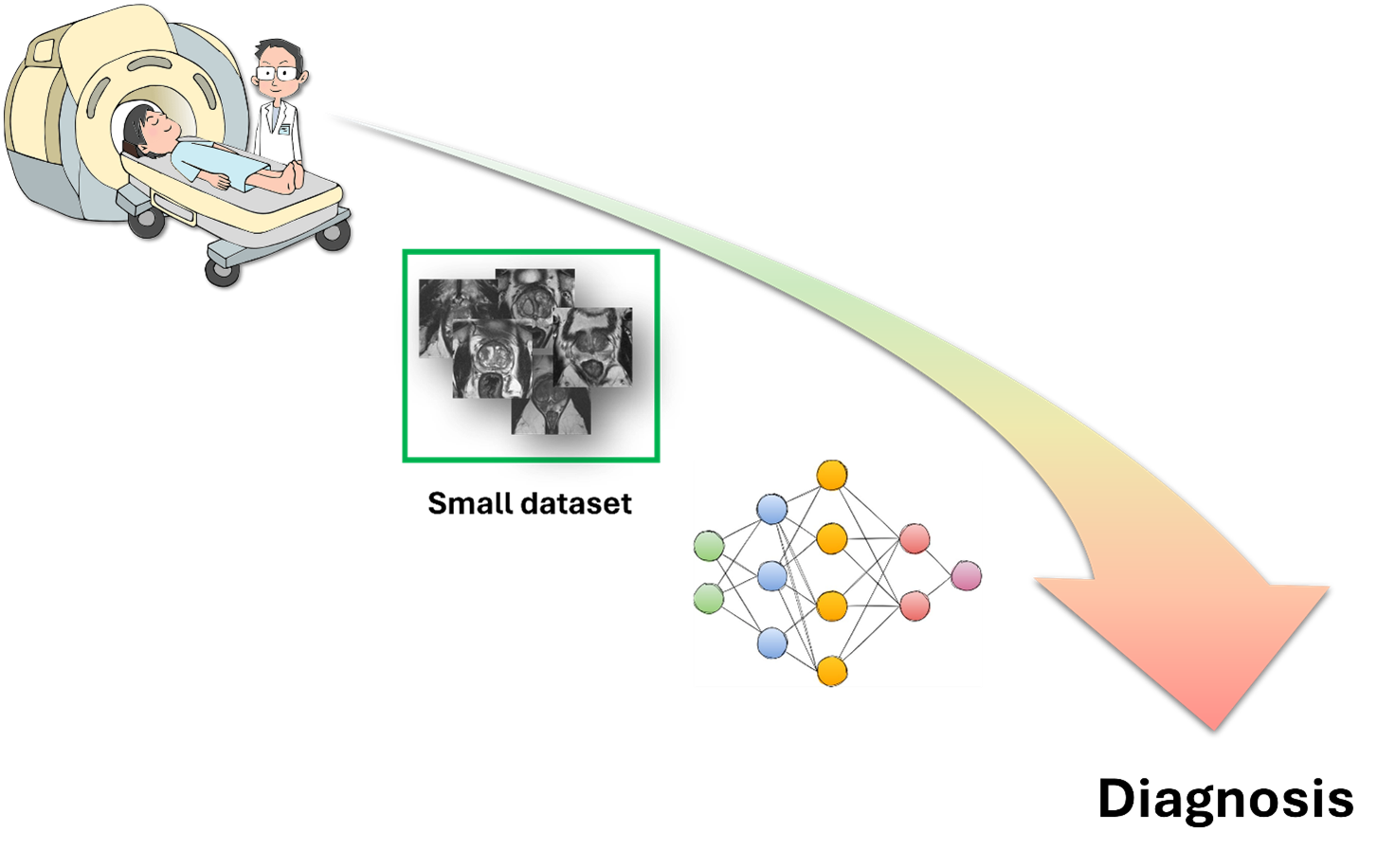
Deep learning models employed in medical imaging are limited by the lack of annotated images. Few-shot learning techniques, where models learn from a small number of examples, can help overcome this scarcity. In a systematic review of the field, Eva Pachetti and Sara Colantonio investigate the state of the art.
An approach for automatically determining the possible actions in computer game states
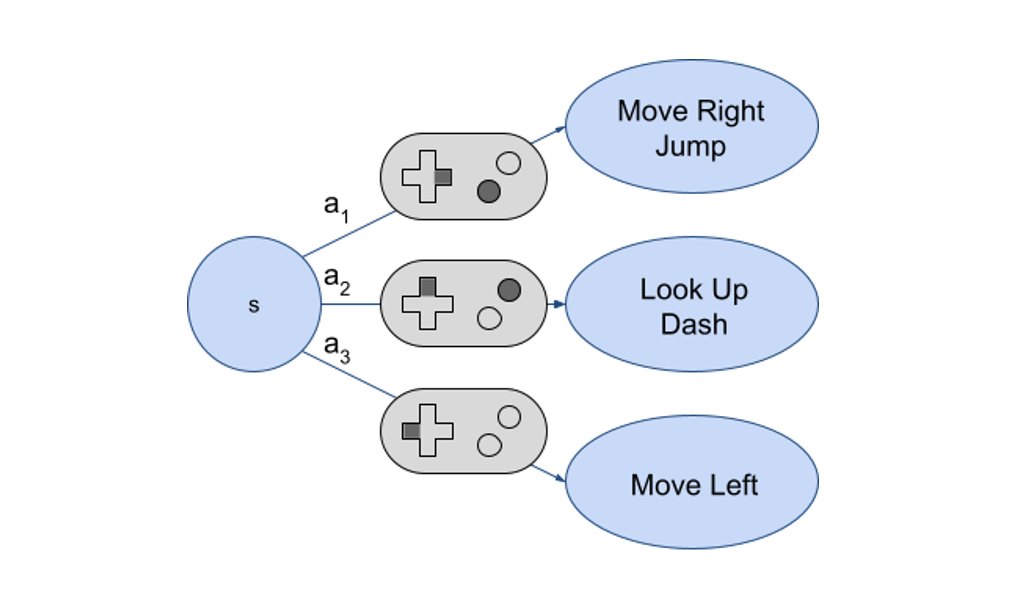
Thoroughly testing video game software by hand is difficult. AI agents that can automatically explore different game functionalities are a promising alternative. In this blogpost, Sasha Volokh writes about an approach for automatically determining the possible actions in computer game states. This was work that won him the best student paper award at AIIDE2023.

AUAI is supported by:








